开学篇之图像分割评价指标
参考论文:[1704.06857] A Review on Deep Learning Techniques Applied to Semantic Segmentation (arxiv.org)
基础知识
图像分割(Instance Segmentation)是在语义检测(Semantic Segmentation)的基础上进一步细化,分离对象的前景与背景,实现像素(pixel)级别的对象分离。
并且图像的语义分割与图像的实例分割是两个不同的概念:语义分割仅仅会区别分割出不同类别的物体,而实例分割则会进一步的分割出同一类中不同实例的物体。
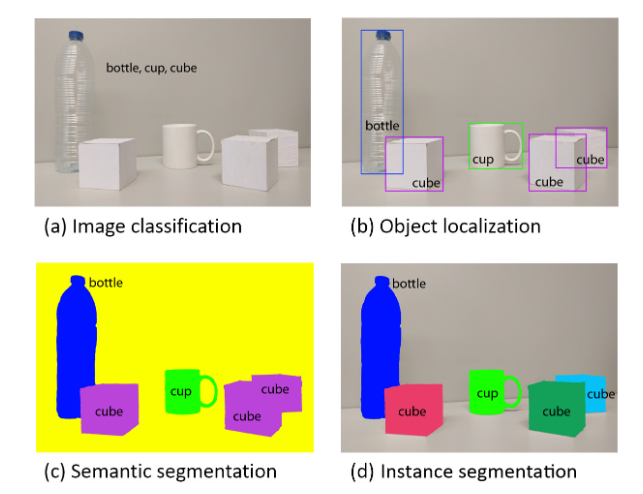
图像分割的(包括语义分割,实例分割,以及全景分割),它们的评价指标都是一样的。常用的图像分割指标有:
- 像素准确率(Pixel Accuracy,PA):这是最简单的度量,为标记正确的像素占总像素的比例;
- 类别平均像素准确率(Mean Pixel Accuracy,MPA):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均;
- 交并比(Intersection over Union,IoU)
- 平均交并比(Mean Intersection over Union,MIoU):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均;
- 频率加权交并比(Frequency Weighted Intersection over Union):为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
在以上所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
直观理解
如下图所示,椭圆A代表真实值,椭圆B代表预测值。橙色部分为A与B的交集,即真正(预测为1,真实值为1)的部分,绿色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个椭圆之外的白色区域表示真负(预测为0,真实值为0)的部分。表示绿色+橙色+黄色为A与B的并集。
- MP计算橙色与(橙色与黄色)的比例。
- MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(绿色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1 。
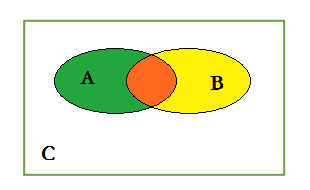
针对预测值和真实值之间的关系,我们可以将样本分为4类: (和图像分类目标检测都一样)
真正值(TP):预测值为1,真实值为1;橙色,A∩B
真负值(TN):预测值为0,真实值为0;白色,~(A∪B)
假正值(FP):预测值为1,真实值为0;黄色,B-(A∩B)
假负值(FN):预测值为0,真实值为1;绿色,A-(A∩B)
- precesion = TP/(TP+FP) 其中分母预测为正样本数量;
- recall = TP/(TP+FN) 其中分母表示原来样本中的正样本数量
衡量指标
假设如下:共有k个类(从$L_1$到$L_k$,其中包含一个空类或背景),Pij表示本属于类i但被预测为类j的像素数量。即Pii表示真正的数量,而Pij和Pji则分别被解释为假正和假负。并且下面以一个图示的方法来展示在分割图中TP、TN、FP、FN等概念。
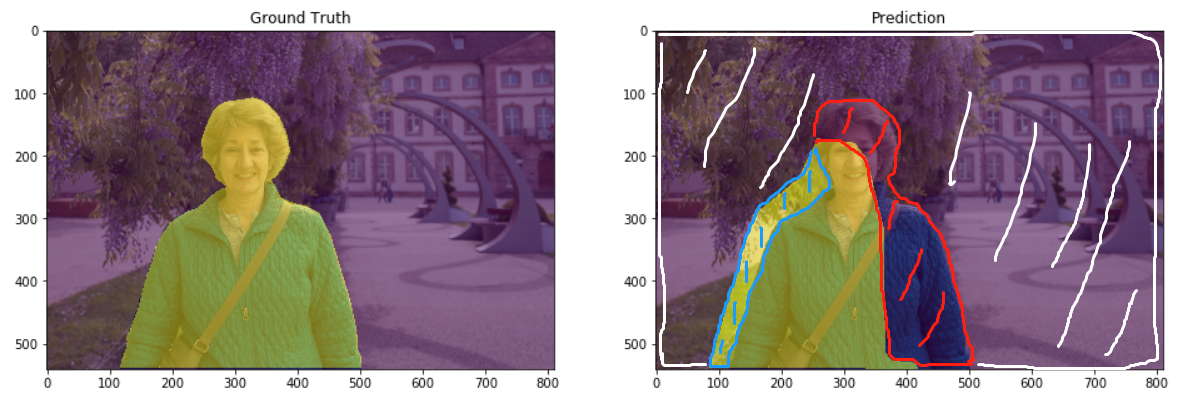
在上图中,左侧是GroundTruth,右侧是Prediction,即预测的掩码图。
Prediction图被分成四个部分:
- 大块的白色斜线标记的是true negative(TN,预测中真实的背景部分);
- 红色线部分标记是false negative(FN,预测中被预测为背景,但实际上并不是背景的部分);
- 蓝色的斜线是false positive(FP,预测中分割为某标签的部分,但是实际上并不是该标签所属的部分);
- 荧光黄色块就是true positive(TP,预测的某标签部分,符合真值)。
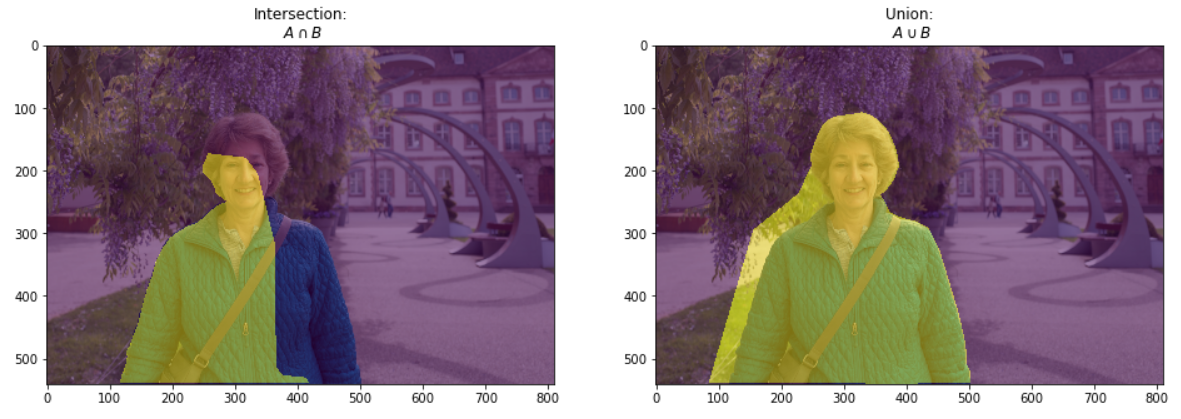
在上图中,左侧是GT,右侧是Prediction,即预测的掩码图。左侧是预测掩码图和真值掩码图的交集,右侧是预测掩码图和真值掩码图的并集。
混淆矩阵
图像分类、目标检测、图像分割都有混淆矩阵,含义基本一致,只是一些略微名词的区别。
混淆矩阵表示统计分类模型的分类结果。对角线代表了模型预测和数据标签一致的数目,所以准确率也可以用混淆矩阵对角线之和除以测试集图片数量来计算。对角线上的数字越大越好,代表模型在该类的预测结果更好。其他地方是预测错误的地方,值越小说明模型预测的更好。
| 标签真实值 | 预测-正例 | 预测-负例 |
|---|---|---|
| 正例 | 真正例(A) TP | 假负例(C) FN |
| 负例 | 假正例(B) FP | 真正例(D) TN |
像素准确率(PA)
$$PA=\frac{\sum_{i=1}^kp_{ii}}{\sum_{i=1}^k\sum_{i=1}^kp_{ij}}$$
图像中共有k类,$p_{ii}$表示将第i类分成第i类的像素数量(正确分类的像素数量),$p_{ij}$表示将第i类分成第j类像素数量(所有像素数量)。因此PA表示正确分类像素数量占总像素数量的比例。
缺点:如果图像中大部分的面积都是背景,目标却很小,即使把整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。
类别平均像素准确率(MPA)
$$MPA=\frac{1}{k}\sum_{i=1}^k\frac{p_{ii}}{\sum_{j=1}^kp_{ij}}$$
分别计算每个类被正确分类像素数的比例,然后累加求平均。
交并比(IoU)
交并比表示的含义是模型对某一类别预测结果和真实值的交集与并集的比值。只不过对于目标检测而言是检测框和真实框之间的交并比,而对于图像分割而言是计算预测掩码和真实掩码之间的交并比。(是一个标准的衡量metric ,实际上都是计算两个集合之间交集和并集的比例)
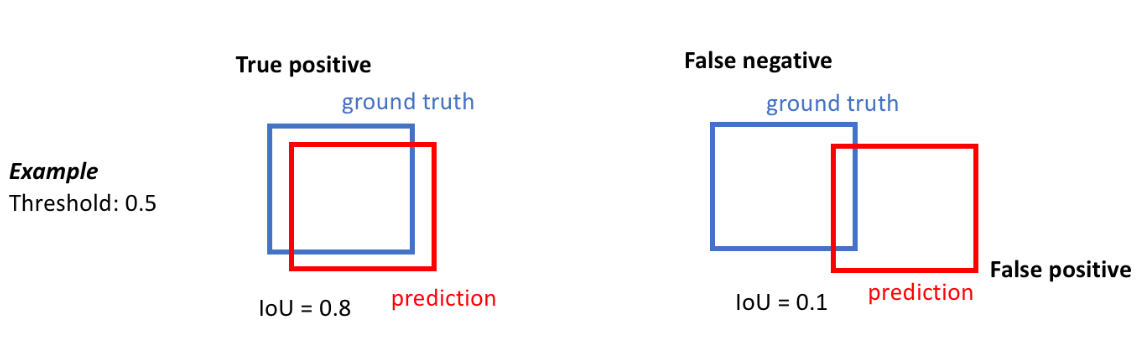
计算方式:交/并=TP/(TP+FN+FP)
即:$IoU=\frac{TP}{TP+FN+FP}$
平均交并比(MIoU)
$$MIoU=\frac{1}{k}\sum_{i=1}^k\frac{p_{ii}}{\sum_{j=1}^kp_{ij}+\sum_{j=1}^kp_{ji}-p_{ii}}$$
预测区域和实际区域交集除以预测区域和实际区域的并集,这样计算得到的是单个类别下的IoU,然后重复此算法计算其它类别的IoU,再计算它们的平均数即可。
表示的含义是模型对每一类预测的结果和真实值的交集与并集的比值,之后求和再计算平均。
可做简化理解,以二分类为例
$$MIoU=\frac{IoU正例Positive+IoU反例Negative}{2}=\frac{\frac{TP}{TP+FP+FN}+\frac{TN}{TN+FP+FN}}{2}$$
MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
频权交并比(FWIoU)
$$FWIoU=\frac{1}{\sum_{i=1}^k\sum_{j=1}^kp_{ij}}\sum_{i=1}^k\frac{\sum_{j=1}^kp_{ij}p_{ii}}{\sum_{j=1}^kp_{ij}+\sum_{j=1}^kp_{ji}-p_{ii}}$$
频权交并比FWIoU是MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。