开学篇之目标检测评价指标
参考理解:【必备】目标检测中的评价指标有哪些?-腾讯云开发者社区-腾讯云 (tencent.com)
对于评价一个目标检测模型的好坏,可以从以下三个方面来评估:
- 精度评价指标:准确率(Accuracy)、精准度(Precision),召回率(Recall)、R-R曲线、AP(Average Precision)、mAP(mean Average Precision)、混淆矩阵 (Confusion Matrix)、ROC + AUC,非极大值抑制(NMS)、交并比(IoU);
- 速度评价指标:FPS(即每秒处理的图片数量或者处理每张图片所需的时间,当然必须在同一硬件条件下进行比较)。
严格说某些场合也会很在意模型的大小,这也是一个研究方向,比如 efficient net, mobile net, shuffle net 等。所以除了上面三个维度,模型的大小也可以是一个评价维度。
与图像分类中的混淆矩阵类似,分为两种错误情况的检测:
- 第一,原假设是正确的,而判断出来是错误的,对应下表的FN;
- 第二,原假设是错误的,而判断出来是正确的,对应下表的FP。
| 检测真实值 | 预测-正例 | 预测-负例 |
|---|---|---|
| 正例 | 真正例(A) TP | 假负例(C) FN |
| 负例 | 假正例(B) FP | 真正例(D) TN |
| 符号 | 含义 |
|---|---|
| TPR(true positive rate) | 真正率、灵敏度(sensitivity) |
| FNR(false negative rate) | 假负率、虚警率(false alarm) |
| FPR(false positive rate) | 假正率 |
| TNR(true negative rate) | 真负率、特异度(specifivity) |
| TP(true positive) | 实际是正例,预测为正例 |
| FN(false negative) | 实际是正例,预测为负例 |
| FP(false positive) | 实际是负例,预测为正例 |
| TN(true negative) | 实际是负例,预测为负例 |
精度评价指标
Precision(精确率/查准率)
在所有检测出的目标中检测正确的概率。
精确率是从预测的结果的角度来定义。精确率又称为查准率。需要注意的是, Precision 和 Accuracy 是不一样的,Accuracy 针对所有样本,而 Precision 仅针对检测出来(包括误检)的那一部分样本。
Recall(召回率/查全率)
召回率是指所有的正样本中正确识别的概率。
召回率是从样本的角度出发的。召回率又称查全率。
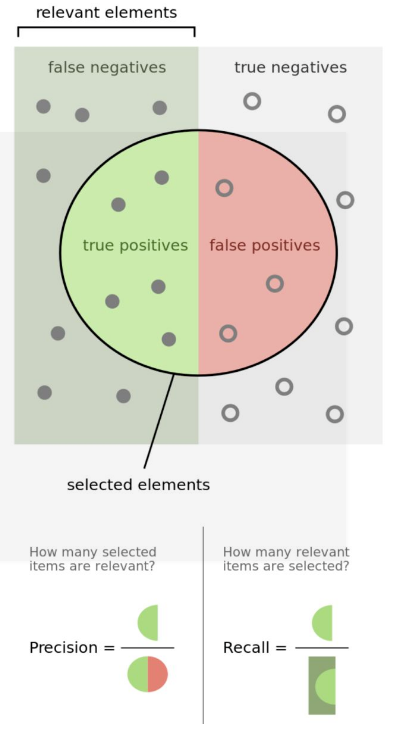
缺陷:假设有一样本(正例10,负例990),但是模型检测将所有样本都分为正例,即TP=10,FN=990,即此刻Recall = 100%,实际上目前模型依旧什么鬼用也没有。
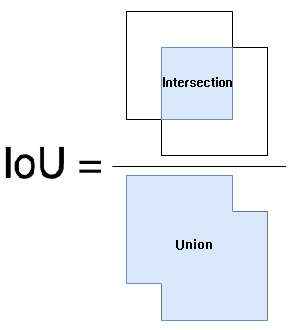
IoU(Intersection over Union)
交并比,计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。
指的是ground truth bbox与predict bbox的交集面积占两者并集面积的一个比率,IoU值越大说明预测检测框的模型算法性能越好,通常在目标检测任务里将IoU>=0.7的区域设定为正例(目标),而将IoU<=0.3的区域设定为负例(背景),其余的会丢弃掉。
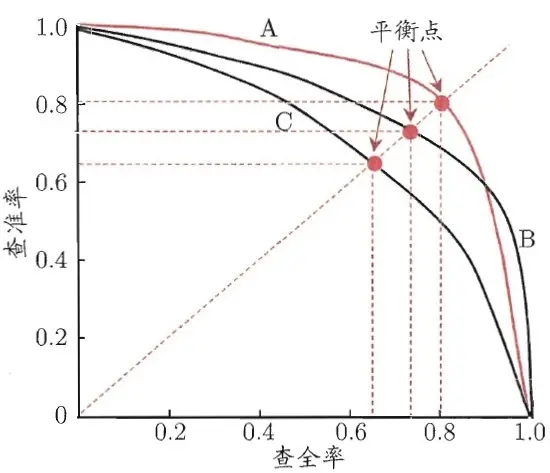
AP(Average Precision)
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
指的是所有图片内的具体某一类的PR曲线下的面积,其计算方式有两种,第一种算法:首先设定一组recall阈值[0, 0.1, 0.2, …, 1],然后对每个recall阈值从小到大取值,同时计算当取大于该recall阈值时top-n所对应的最大precision。这样,我们就计算出了11个precision,AP即为这11个precision的平均值,这种方法英文叫做11-point interpolated average precision;第二种算法:该方法类似,新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, …, M/M),对于每个recall值r,该recall阈值时top-n所对应的最大precision,然后对这M个precision值取平均即得到最后的AP值。
mAP(mean Average Precision)
指所有图片内的所有类别的AP的平均值。
假设有10张图像用于目标检测,每张图像都事先标记有GT(Ground Truth)标注框,这里的类别可以有多个且每张图像同一类别也可以有多个目标,但是AP是指所有图片内的具体某一类的PR曲线下的面积,因此我们只关注一个类别即可,比如我们只关注车辆,那么经过算法预测后,每一张图像都会得出相应的车辆预测框和置信度,我们根据置信度进行降序排序,然后按照常用阈值取IoU=0.5,预测框与实际框的IoU大于0.5时,我们记为TP,否则记为FP,当然,也许在一张图像里算法一个目标都没有检测到,这时候检测不到的目标则被标记为FN,有了每一张图像的TP、FP和FN我们就可以计算每一张图像的Precision和Recall值了,从而就可以计算出PR曲线下的面积得出具体类别的AP值了。
搬运栗子:
假设上述10张图像有两张图像都有2个车辆目标,而其余图像仅有1个车辆目标,那么总的GT则有12个,经过算法预测后有9张图像检测出车辆,而有一张有2个车辆目标的图像无法检测出车辆,这样,每张图像有多少个车辆预测框、预测置信度、TP、FP及FN即可假设如下表所示:
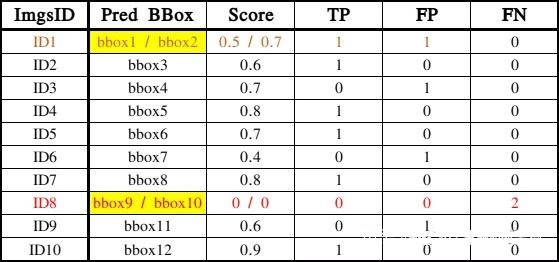
其中,ImgsID为ID1和ID8的这两张图像每张都有两个车辆目标,但ID8这张图像检测不出任何车辆目标,而在依据置信度降序排序时我们将以每一个预测框来计算Precision和Recall,从而我们可以得出如下的Precision和Recall计算表:
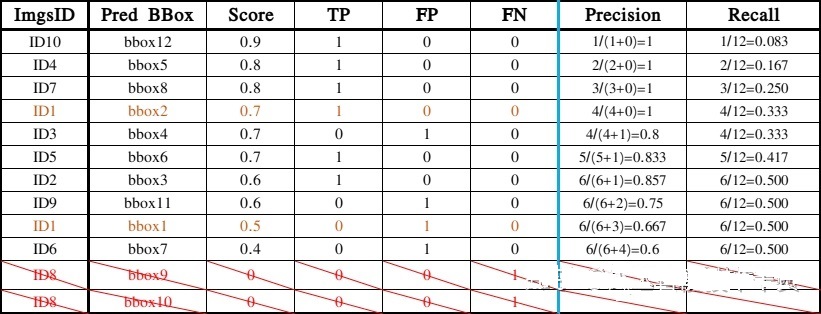
AP指的是所有图片内的具体某一类的PR曲线下的面积,PR曲线通常横坐标为Recall值,而其纵坐标为Precision,对于同一个Recall值,我们取的是最大的Precision,因此,有如下的PR曲线取值:
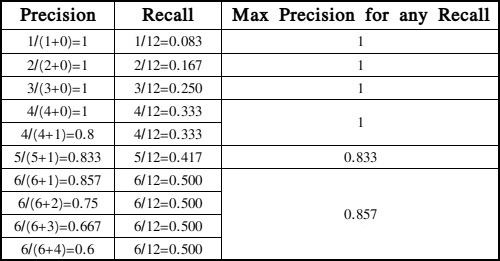
依据以上PR表格,我们可以得出如下PR曲线图:
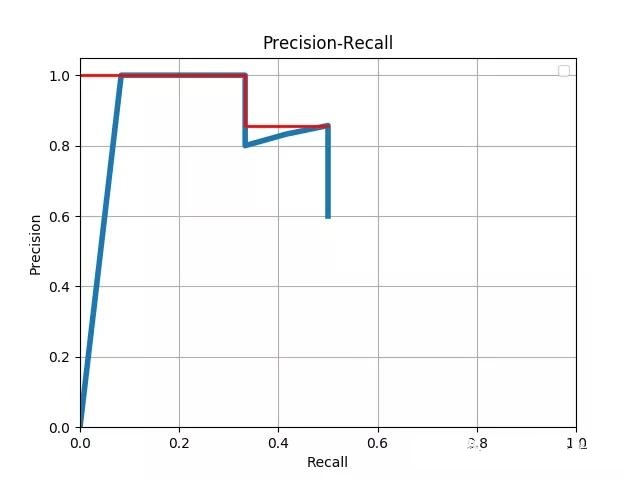
蓝色折线即为PR曲线,而红色折线与横纵坐标所包围的面积即为该PR曲线下的PR面积即AP值,从而依据上述假设和PR曲线图或PR表格,我们可以得出该目标检测算法车辆类的AP值即PR曲线垂直投射横纵坐标下的面积计算公式如下:
AP = (0.333 - 0) 1 + (0.5 - 0.333) 0.857 = 0.476
因此,在该假设情况下,该目标检测算法的车辆类在Iou为0.5的情况下其AP值为0.476,同理,其他目标类别可依据该方法计算得出。
由此即可算出mAP计算公式:(C为目标检测任务中的类别数量)
注意:计算mAP在NMS之后
mAP是统计检测模型的最终评价指标,是所有操作完成之后,以最终的检测结果作为标准,来计算mAP值的,另外提一点一般只有测试的时候才会作NMS,训练的时候不进行NMS操作,因为训练的时候需要大量的正负样本去学习。
fppi/fppw
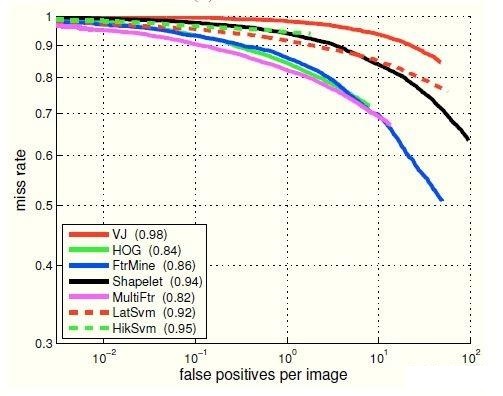
fppi曲线的纵轴为FN(即Miss rate),横轴为false positive per image。相比PR曲线,fppi更接近于实际应用(如果就业情况,对待产品介绍时可以用这个来表示模型算法有多牛)。
非极大值抑制(NMS)
非极大值抑制虽然一般不作评价指标,但是也是目标检测中一个很重要的步骤
单个预测目标
NMS的英文为Non-Maximum Suppression,就是在预测的结果框和相应的置信度中找到置信度比较高的bounding box。对于有重叠在一起的预测框,如果和当前最高分的候选框重叠面积IoU大于一定的阈值的时候,就将其删除,而只保留得分最高的那个(保留红框)。

计算步骤:
1). NMS计算出每一个bounding box的面积,然后根据置信度进行排序,把置信度最大的bounding box作为队列中首个要比较的对象;
2). 计算其余bounding box与当前最大score的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU预测框;
3). 然后重复上面的过程,直至候选bounding box为空。
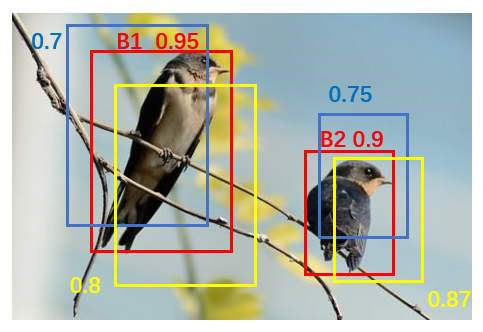
多个预测目标
当存在多目标预测时,如下图,先选取置信度最大的候选框B1,然后根据IoU阈值来去除B1候选框周围的框。然后再选取置信度第二大的候选框B2,再根据IoU阈值去掉B2候选框周围的框。
速度评价指标
FPS,检测器每秒能处理图片的张数,简单的说就是一秒钟能够检测多少张图片。
FLOPs和FLOPS