一些函数解释(更新ing)
assert
用于程序调试
使用assert断言语句是一个非常好的习惯,python assert断言句语格式及用法很简单。在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行到最后崩溃,不如在出现错误条件时就崩溃,这样在跑大规模程序的时候不会过多的浪费时间和计算资源,这时候就需要assert断言的帮助。
例子1
1 | assert expression |
该形式用来测试断言的expression语句,如果expression是True,那么什么反应都没有。但是如果expression是False,那么会报错AssertionError。
如:
1 | # 出错时 |
例子2
1 | assert expression1, expression2 |
assert断言语句可以添加异常参数,也就是在断言表达式后添加字符串信息,用来解释断言并更好的知道是哪里出了问题。格式如下:
1 | assert expression [, arguments] |
如:
1 | # 出错时 |
nn.Parameter()
parameter,中文意为参数。我们知道,使用PyTorch训练神经网络时,本质上就是训练一个函数,这个函数输入一个数据(如CV中输入一张图像),输出一个预测(如输出这张图像中的物体是属于什么类别)。而在我们给定这个函数的结构(如卷积、全连接等)之后,能学习的就是这个函数的参数了,我们设计一个损失函数,配合梯度下降法,使得我们学习到的函数(神经网络)能够尽量准确地完成预测任务。
通常,我们的参数都是一些常见的结构(卷积、全连接等)里面的计算参数。而当我们的网络有一些其他的设计时,会需要一些额外的参数同样很着整个网络的训练进行学习更新,最后得到最优的值,经典的例子有注意力机制中的权重参数、Vision Transformer中的class token和positional embedding等。
首先可以把这个函数理解为类型转换函数,将一个不可训练的类型
Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
ViT中nn.Parameter()
在ViT中,positonal embedding和class token是两个需要随着网络训练学习的参数,但是它们又不属于FC、MLP、MSA等运算的参数,在这时,就可以用nn.Parameter()来将这个随机初始化的Tensor注册为可学习的参数Parameter。
1 | ... |
举个栗子
指定这两个参数的初始数值为0.98,并打印迭代器net.Parameters()。
1 | ... |
实例化一个ViT模型并打印net.Parameters():
1 | net_vit = ViT( |
输出结果中可以看到,最前两行就是我们显式指定为0.98的两个参数pos_embedding和cls_token:
1 | tensor([[[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800], |
这就可以确定nn.Parameter()添加的参数确实是被添加到了Parameters列表中,会被送入优化器中随训练一起学习更新。
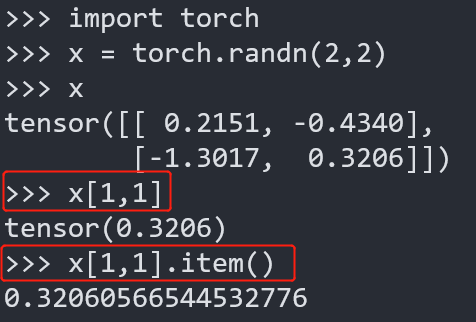
.item()
取出单元素张量的元素值并返回该值,保持原元素类型不变。,即:原张量元素为整形,则返回整形,原张量元素为浮点型则返回浮点型,etc
x[1,1] VS x.item():
1 | import torch |
numpy.pad()
在卷积神经网络中,为了避免因为卷积运算导致输出图像缩小和图像边缘信息丢失,常常采用图像边缘填充技术,即在图像四周边缘填充0,使得卷积运算后图像大小不会缩小,同时也不会丢失边缘和角落的信息。在Python的numpy库中,常常采用numpy.pad()进行填充操作。
*numpy.pad(array, pad_width, mode=‘constant’, *kwargs)
array
表示需要填充的数组。
pad_width
表示每个轴(axis)边缘需要填充的数值数目。
参数输入方式为:((before_1, after_1), … (before_N, after_N)),其中(before_1, after_1)表示第1轴两边缘分别填充before_1个和after_1个数值。
mode
表示填充的方式(取值:str字符串或用户提供的函数),总共有12种填充模式。
默认为’constant’方式填充。
**kwargs
表示关键字参数,它本质上是一个dict。
- constant_values : sequence or scalar, optional。用于‘constant’填充方式指定的填充值。
- stat_length : sequence or int, optional。用于 ‘maximum’, ‘mean’, ‘median’,和‘minimum’填充方式中。每个轴边缘用于计算统计量的数据个数,默认用到整个轴。
- end_values : sequence or scalar, optional。用于 ‘linear_ramp’填充方式,设定结束值。
- reflect_type : {‘even’, ‘odd’}, optional,默认为‘even’。
Swin Transformer中需要对输入图片进行padding处理
1 | pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0) |
torch.meshgrid()
torch.meshgrid()的功能是生成网格,可以用于生成坐标。函数输入两个数据类型相同的一维张量,两个输出张量的行数为第一个输入张量的元素个数,列数为第二个输入张量的元素个数,当两个输入张量数据类型不同或维度不是一维时会报错。
其中第一个输出张量填充第一个输入张量中的元素,各行元素相同;第二个输出张量填充第二个输入张量中的元素各列元素相同。
1 | # 【1】 |
torch.stack()
stack(tensors,dim=0,out=None)在维度上连接(concatenate)若干个张量。(这些张量形状相同)。
将若干个张量在dim维度上连接,生成一个扩维的张量,比如说原来你有若干个2维张量,连接可以得到一个3维的张量。
设待连接张量维度为n,dim取值范围为-n-1~n,这里得提一下为负的意义:-i为倒数第i个维度。举个例子,对于2维的待连接张量,-1维即3维,-2维即2维。
1 | a=torch.tensor([[1,2,3],[4,5,6]]) |