Tensor的维度变换
Tensor通道排列顺序: [ batch, channel, height, width ]
view和reshape
从功能上来看,它们的作用是相同的,都是用来重塑 Tensor 的 shape 的。view 只适合对满足连续性条件 (contiguous) 的 Tensor进行操作,而reshape 同时还可以对不满足连续性条件的 Tensor 进行操作,具有更好的鲁棒性。view 能干的 reshape都能干,如果 view 不能干就可以用 reshape 来处理。
简单来说就是reshape是view的大哥,大哥都能干(满足或不满足连续性条件),小弟只能干一部分(只满足连续性条件),如果想简单了事,就直接用reshape,但个人觉得最好还是通过contiguous()之后在同view。
因为当不满足连续条件时,需要先使用 contiguous() 方法将原始 Tensor 转换为满足连续条件的 Tensor,然后就可以使用 view 方法进行 shape 变换了。或者直接使用 reshape 方法进行维度变换,但这种方法变换后的 Tensor 就不是与原始 Tensor共享内存了,而是被重新开辟了一个空间。
a.reshape = a.view() + a.contiguous().view()
view 的存在可以显示地表示对这个 Tensor 的操作**只能是视图操作而非拷贝操作,只能是浅拷贝而非深拷贝操作。**这对于代码的可读性以及后续可能的 bug 的查找比较友好,可以避免不必要的显存开销。
- 例子1:height × width
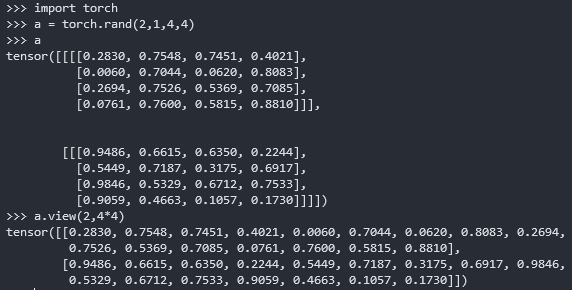
1 | a = torch.rand(2,1,4,4) |
解读:将图片的通道数、图片的像素行列值都拼接在一起,成为[4,784],适合全连接层的输入
- 例子2:batch × channel
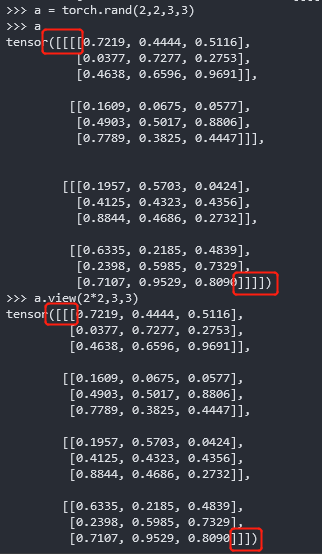
1 | a = torch.rand(2,1,4,4) |
解读:表示我们现在只关注feature map这个属性,而不关注它来自哪个图片的哪个通道
注意:在view之后如果想恢复到原来的维数是要进行记录的,否则直接恢复是不行的。
squeeze和unsqueeze
squeeze
进行维度压缩,去掉 tensor 中维数为1的维度(如果设置dim=a,就是去掉指定维度中维数为1的)
1 | import torch |
unsqueeze
进行维度扩充,在指定位置加上维数为1的维度(如果设置dim=a,就是在维度为a的位置进行扩充)
1 | import torch |
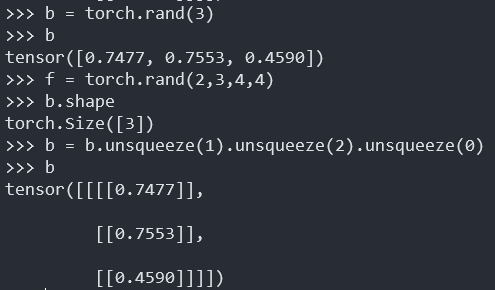
例子:f表示2张4*4的拥有3个通道的图片,而b表示给图片的每个channel上的所有的像素添加一个偏置,我们的目标就是把b叠加在f上面,所以要将b的维度变换与f相同才可以进行,然后再进行b的扩张。
1 | b = torch.rand(2) |
expand和repeat
进行维度的扩展,就像前面的b [1,3,4,4],要想与 f [2,3,4,4]进行相加的话,b就要进行维度的扩展。
区别:两种方法在效果方面是等效的,但是expand只在需要的时候进行数据的复制,而repeat会直接复制数据。所以推荐使用expand
expand
例子1
1 | b = torch.randn(1,3,1,1) |
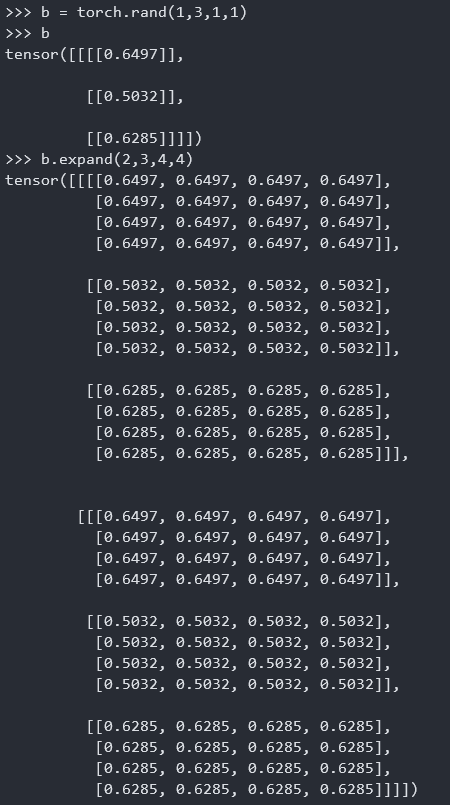
局限性:
- 要求expand之前之后的dimension必须一样。
- 只能在之前维数为1的地方进行expand,而如果之前的维数为3是没有办法扩张到m的。
[ 3,3,4,4 ]——b.expand(4,3,4,4)报错
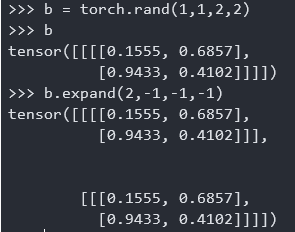
例子2:不想进行变动的地方使用-1代替就可以
1 | b = torch.rand(1,1,2,2) |
repeat
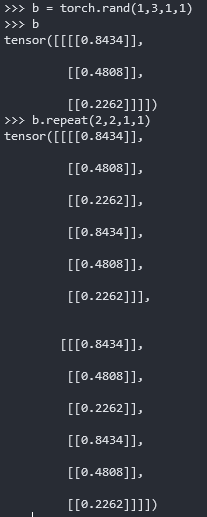
repeat的参数表示你要在该维数位置进行多少次复制
1 | b = torch.randn(1,3,1,1) |
表示:1复制4次变为4,32复制32次变为1024,其它没变
.t()转置
进行tensor的转置,但是要注意:只能进行2D tensor的转置,即矩阵的转置。
transpose转置
进行某几维之间的相互交换
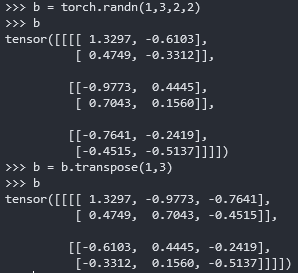
例子1
1 | b = torch.randn(1,3,2,2) |
例子2:这样变换前后的二者是一样的(contiguous()表示进行transpose之后数据不再是按顺序存放的,使用该方法进行顺序的调整)
1 | a2 = b.transpose(1,3).contiguous().view(2,3*2*2).view(2,3,2,2).transpose(1,3) |

注意:[ B C H W ] → [ B W H C] → [ B W * H * C ] →[ B C W H ]这样的变换是不行的 W与H的顺序变换了,图像也会处出现变换
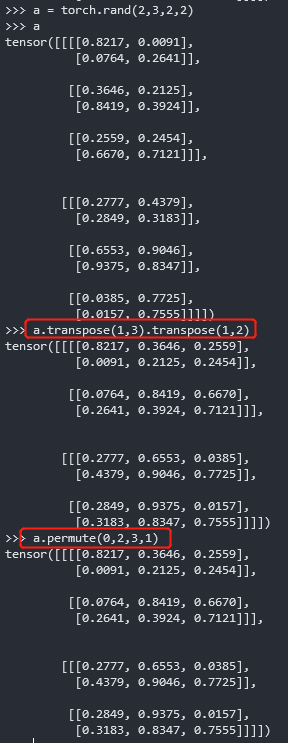
例子3
1 | a = torch.rand(2,3,2,2)#[B C H W] |
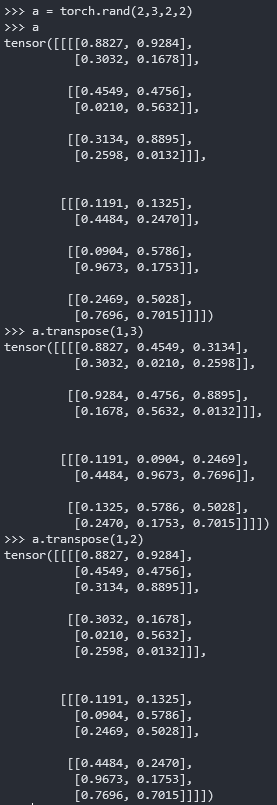
由于[B H W C]是numpy中储存图片的方式,所以这样变换以后才能导出numpy
permute函数
transpose中的例子3使用permute函数进行简单的一步变换:
1 | # a.transpose(1,3).transpose(1,2) = a.permute(0,2,3,1) |