深度学习模型之CNN(二十六)MobileViT网络讲解及通过Pytorch搭建
MobileViT是CNN和Transformer的混合架构模型,原论文:MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
网络架构学习
前言
当前纯Transformer模型存在的问题:
- 参数多,算力要求高(比如ViT-L Patch16模型,仅权重模型就有1G多);
- 缺少空间归纳偏置;
- 迁移到其他任务比较繁琐(相对于CNN);
为什么会繁琐?
主要由于位置偏置导致的,比如在Vision Transformer当中采用的是绝对位置偏置,那么绝对位置偏置的序列长度是和输入token的序列长度保持一致的。也就是说在训练模型的时候,在指定了输入图像尺寸之后,绝对位置偏置所对应的序列长度其实就固定了,如果后期要更改输入图片的尺寸的话,会发现通过图片生成的token序列长度和绝对位置偏置的序列长度是不一致的。这样就没法进行一个相加以及后续的处理了。
针对这个问题,现有的问题最简单的就是去进行一个差值。也就是说将绝对位置编码给差值到与输入token数据序列相同的一个长度,那么差值之后呢,又会引入另外一个新的问题。就是说一般我们将差值之后的模型拿来直接用的话,会发现可能会出现掉点的情况。但是对于CNN模型,比如在224x224的图片尺寸上进行训练,然后在384x384的尺寸上进行验证,一般是会出现一个长点的情况,比如在ImageNet上可能会涨一个点左右。但是对于Transformer的模型,如果简单通过差值的方式在一个相对更高的分辨率上进行验证,会发现可能会掉点。
所以说一般对Transformer的绝对位置偏置进行差值之后,还要进行一个微调。但如果每次修改了图片尺寸之后都要重新对绝对位置偏置进行一个差值和微调,就会太麻烦了一点。
有人会说,可以采用像Swin Transformer当中所采用的相对位置偏执。的确如此,在Swin Transformer当中的相对位置偏执,对输入图片尺寸并不敏感,只对设置的window的大小有关。但如果训练的模型的输入图片尺寸和迁移到其他任务的图片尺寸相差比较大的话,其实一般还是会对window的尺寸进行一个调整的。比如说先在ImageNet上进行一个预训练,那么训练的时候可能输入的图片大小为224x224,假设要迁移到目标检测任务中,那么此时输入的图像分辨率可能是1280x1280,那么很明显,从224到1280,图像尺寸发生非常大的变化。如果此时不去调整window的尺寸大小的话,那么效果依旧会受到影响。所以一般针对这个情况,还是会去将window的尺寸给设置的更大一点。一旦window的尺寸发生变化,那么相对位置编码的序列长度也会发生变化,那么还是遇见更改提到的问题。
因此当前所采用的这些位置编码其实有很多值得优化的地方,比如在Swin TransformerV2的论文当中,其实就针对Swin Transformerv1当中所采用的相对位置编码进行了优化。
- 模型训练困难(相对于CNN)
根据现有的一些经验,训练一个Transformer往往需要更多训练数据和迭代更多的epoch,需要更大的L2正则,需要更多的数据增强,并且对数据增强是比较敏感的。
针对以上提出的几点问题,现有一个很好的解决办法就是可以将CNN架构和Transformer架构进行一个混合使用。因为CNN架构本身就带有空间归纳偏置,如果使用它之后就不需要单独去加上位置偏置或者位置编码。并且加入CNN之后是能够加速网络的收敛,使整个网络的训练过程更加稳定。

在上图中,Augmentation指数据增强的两种方式,一个是比较基础的basic,另一个是更加先进的advance。basic就代表采用的使像ResNet那样的一个比较简单的数据增强,也就是随机裁剪加一个水平方向的随机翻转。但对advance所包含的数据增强方式就非常的多。
根据上图(b)表可以看出,MobileViT尽管采用的Augmentation中的basic,但是Top-1还是能达到74.8和78.4,也说明MobileViT对数据增强没有那么敏感,而且学习能力也是比较强的。

根据上图MobileViT与比较轻量和重的模型对比,能够看出来CNN和Transformer所结合的MobileViT模型确实效果是非常不错的。

模型结构解析
Vision Transformer结构简介
这是论文当中作者所给的标准的Vision Transformer视觉模型结构,和之前讲过的Vision Transformer有一点点的不一样。最主要这里并没有Vision Transformer里面所提到的class token。其实class token就是参考BERT网络,但是对于视觉任务而言,其实class token并不是必须的,所以下图所展示的是一个更加标准的针对视觉的一个Vision Transformer架构。
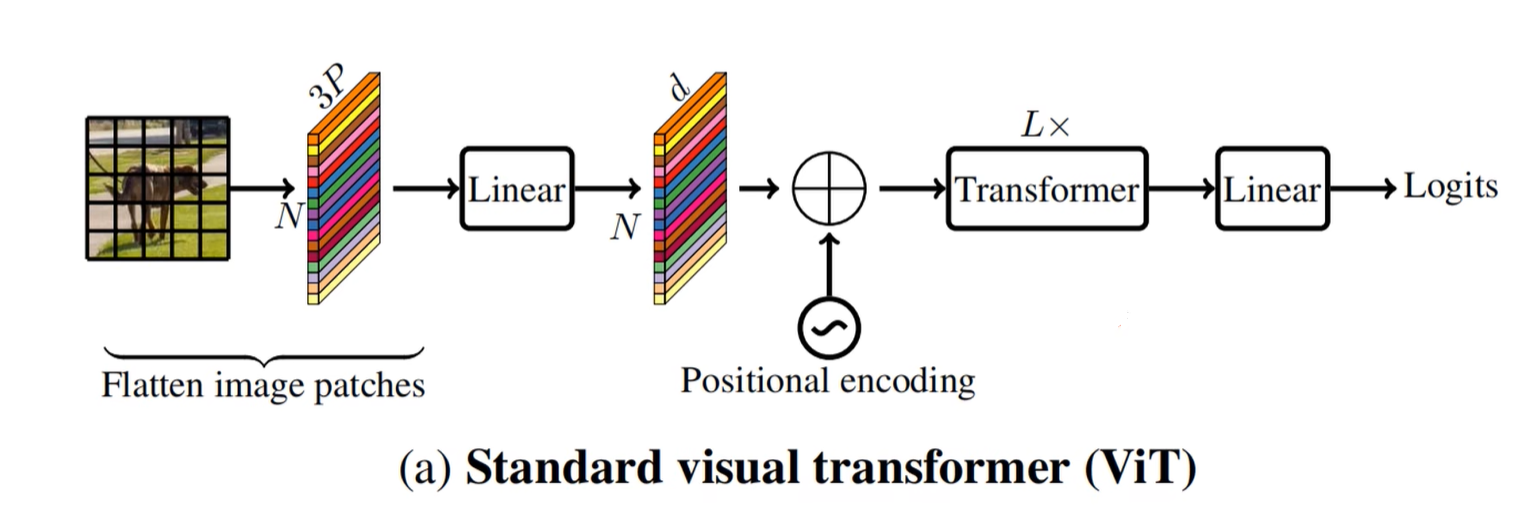
首先可以看到我们是针对输入的图片划分为一个一个patch,然后将每个patch的数据进行展平,展平之后再通过一个线性映射得到针对每一个patch所对应的token(其实每一个token对应的也就是一个向量而已),那么将这些token放在一起就得到一个token序列(在网络实际搭建过程当中,其实关于这一步也就是展平加线性映射这一块是可以直接通过一个卷积操作实现的),然后再加上一个位置编码或者说位置偏置(可以采用绝对位置偏置或者相对位置偏置),接着再通过L x Transformer Block(其实可以在Transformer Block和全连接层之间加一个全局池化层),再通过一个全连接层就得到输出。
MobileViT介绍
整体架构
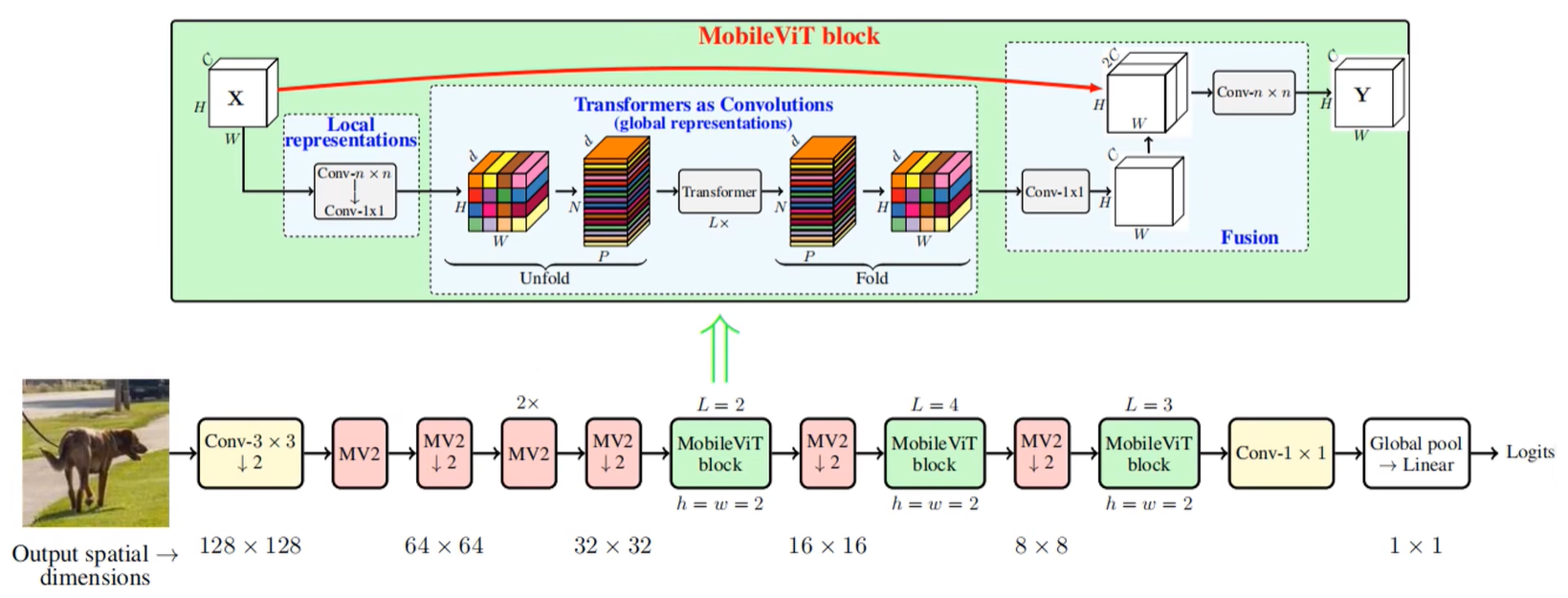
MV2
相当于MobileNet v2当中提出的Inverted Residual Block。有些MV2会有向下的箭头,这代表这个模块是需要对特征图进行一个下采样的。
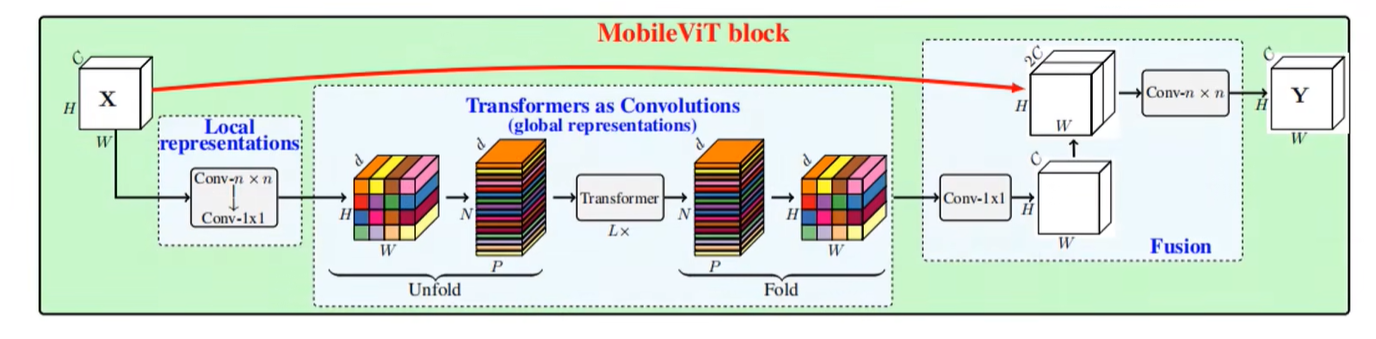
MobileViT block
首先输入一个$H✖W✖C$的特征图,先做一个局部的表征或者说做一个局部的建模(Local representations,其实就是通过一个卷积核大小为$n✖n$的卷积层实现的。在代码当中就是一个3x3的卷积层,然后再通过一个1x1的卷积层去调整通道数)。
调整完之后,进行一个全局表征或者说全局的建模(global representations,其实就是通过一个Unfold,再通过L个Transformer Block,然后再通过Fold折叠回特征图)。
接着再通过一个1x1的卷积层去调整通道数,将通道数又还原回了C,也就是和输入的特征图的通道数保持一致。接着通过一个shortcut将更改得到的特征图和输入特征图进行concat拼接,拼接玩完之后通道数为2C,再通过一个$n✖n$的卷积层进行一个特征融合(在源码中,这里的n对应的是3x3)。
这就是整一个MobileViT block的结构,核心其实还是有关全局表征这部分
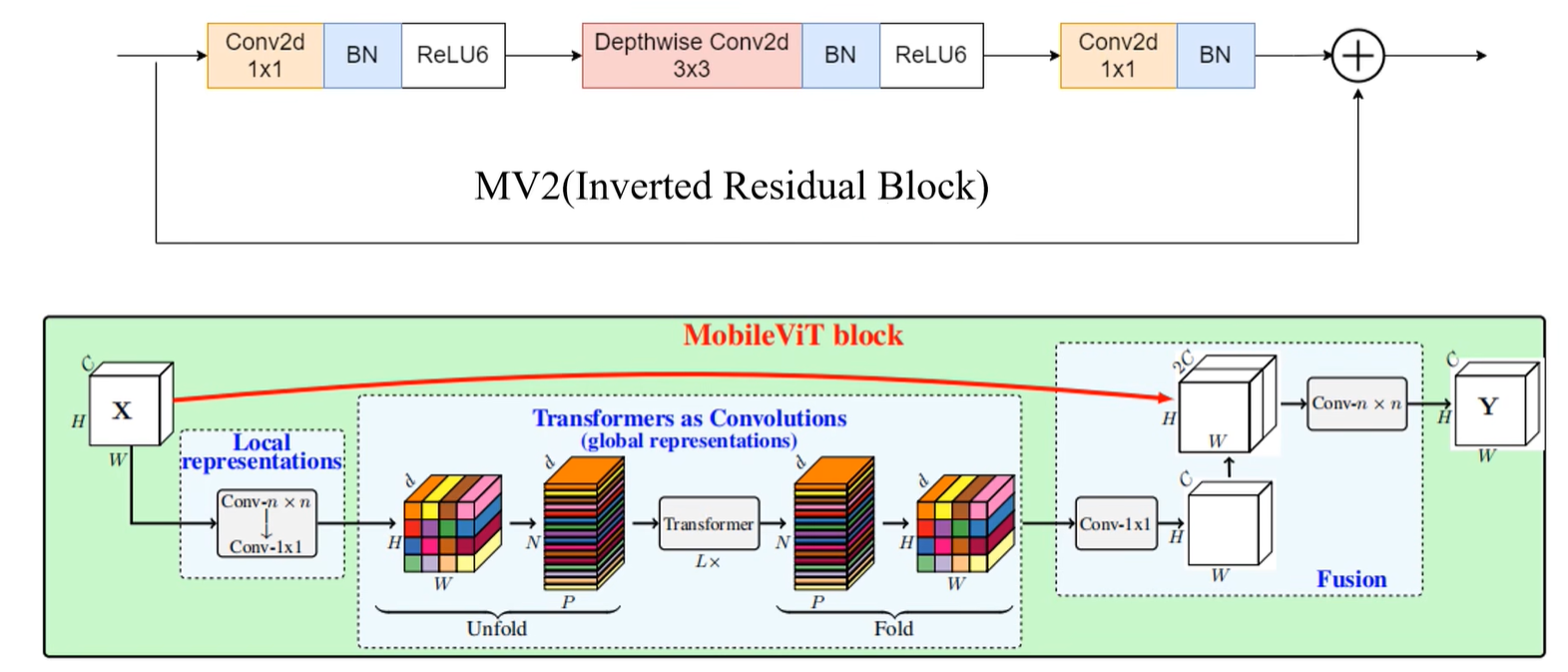
全局表征中的Transformer
下图(中)为方便忽略channel,对于输入transformer block或者说transformer encoder,一般将特征图直接展平成一个序列,然后再输入到transformer block当中。
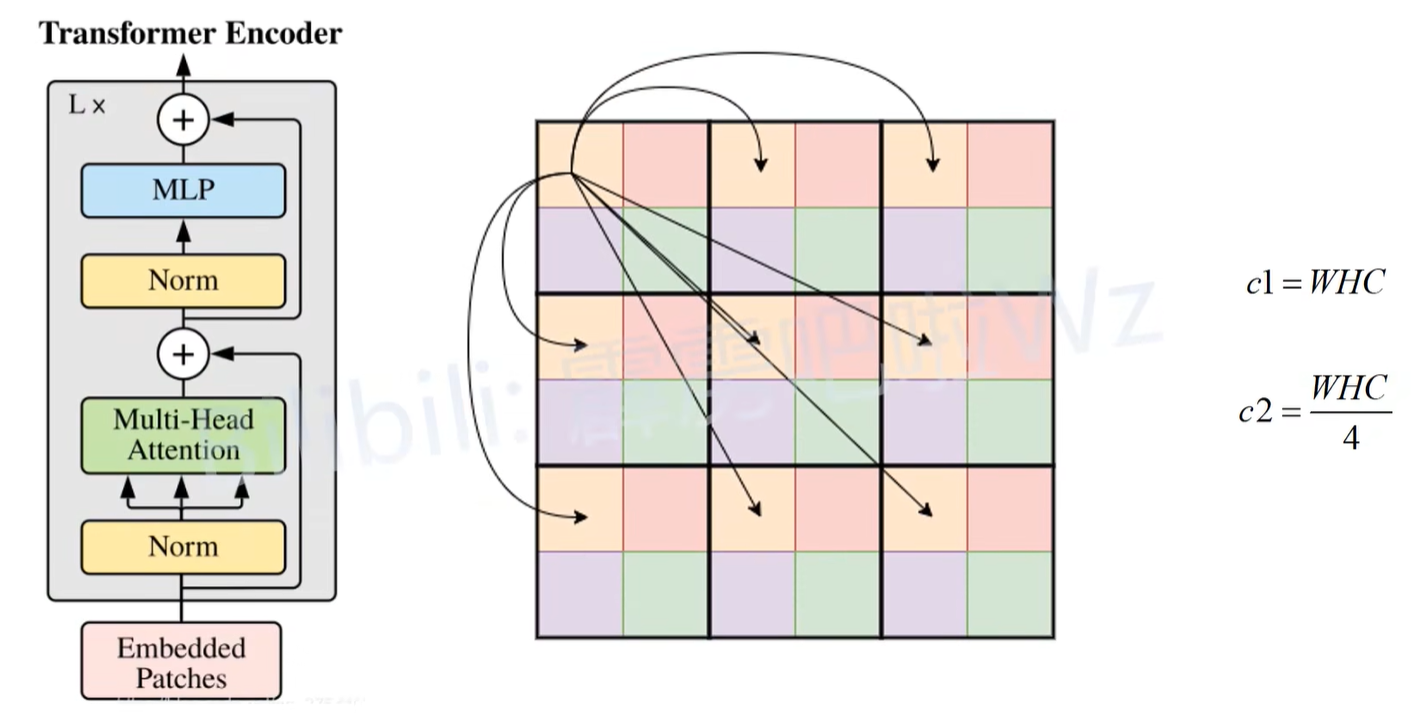
在做Self-Attention的时候,图中的每一个像素或者说每一个token是需要和所有的token进行一个Self-Attention的。但是在MobileViT当中,并不是这么去做的。
首先会将输入特征图划分成一个个patch,在下图(中)中以2x2大小的patch为例。
划分完之后在实际做Attention时,其实是将每一个patch当中对应相同位置的token去做self Attention,也就是说,下图(中)这些颜色相同的token才会去所self Attention,那么通过这么个方式,就能减少Attention的计算量。
对于原始的self Attention这段计算过程(也就是说每一个token都要和所有的token去进行一个Attention),假设计算某一个token与其他所有token进行Attention的计算量,记为$WHC$,因为要和每一个token都去进行self Attention;
但是在MobileViT当中,只是让颜色相同的这些token去做self Attention,以下图2x2的patch为例,对于每一个token做self Attention的时候,实际计算量为$\frac{HWC}{4}$,因为这里的patch大小为2x2,所以计算量缩减为原来的$\frac{1}{4}$。
其实这样做只能减少在做self Attention时的计算量。对于transformer block或者说transformer encoder的其他部分的计算量是没有任何变化的。因为像下图(左)中这些像Norm以及MLP其实是针对token去做处理的。
为什么可以这么做呢?
因为在对图像进行处理中,是存在非常多的冗余数据,特别是对于图像分辨率较高的一个情况。对于相对底层的特征图也就是说当H和W比较大的时候,相邻像素之间的一个信息差异其实是比较小的。如果在做self Attention的时候,每一个token都要去看一遍的话,还是挺浪费算力的。
但并不是说去看相邻的像素或者token没有意义,只是说在分辨率较高的特征图上,收益可能很低,那么增加了这些计算成本远大于ACC上的收益。而且在做全局表征之前,也就是
Local representations,已经提前做了一个局部表征,后面做全局表征的时候其实就没必要那么细了。
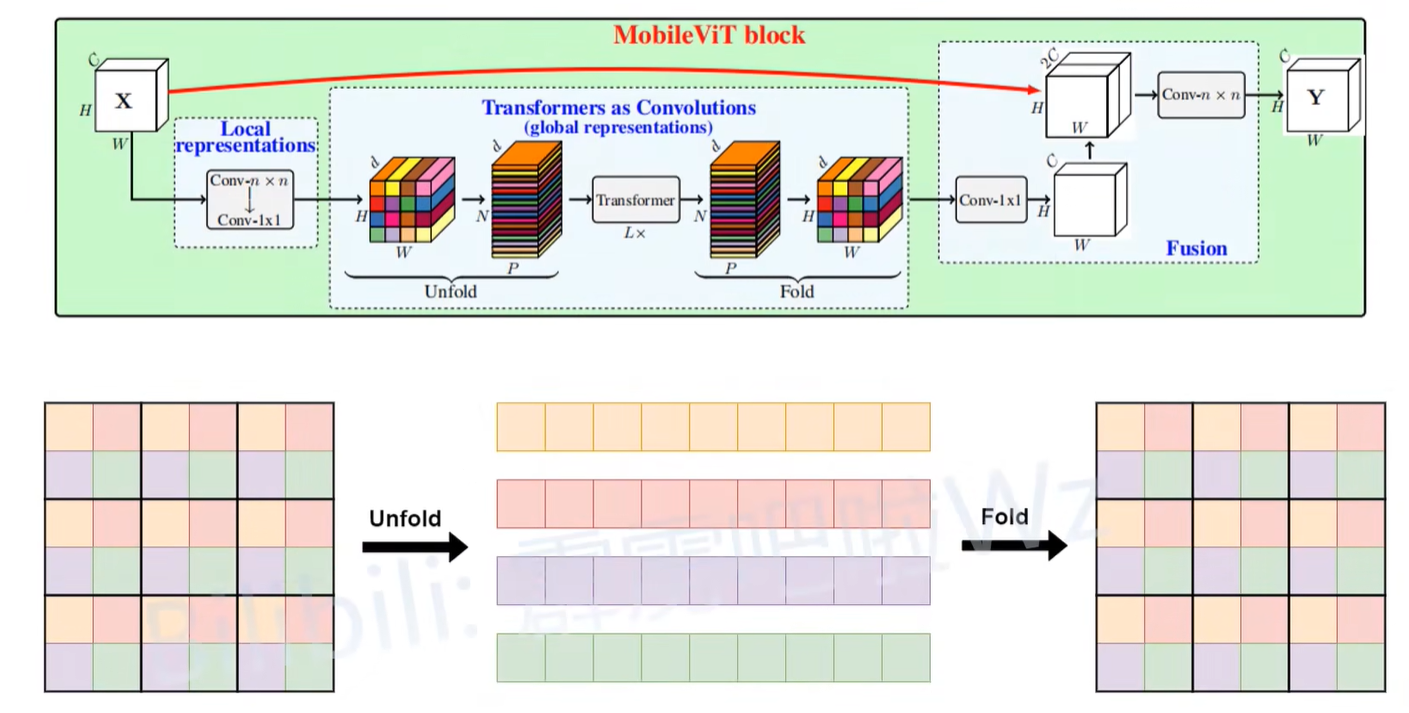
全局表征中的Unfold和Fold
在MovileViT中,只是将这些颜色相同的token去做Attention,颜色不同的token是不做信息交互的,所以在论文当中,这里的Unfold就是将颜色相同的这些token给拼成一个序列。比如将patch设置为2x2的话,通过Unfold可以得到4个序列。
之后将每个序列输入到Transformer Block当中进行全局建模。这里的每一个序列在输入Transformer Block时,是可以进行并行计算的,所以速度还是非常快的。
最后再通过Fold方法将这些特征折叠回原特征图的一个形式。
所以全局表征中的Unfold和Fold就是对特征图进行一个拆分和重新折叠的过程。
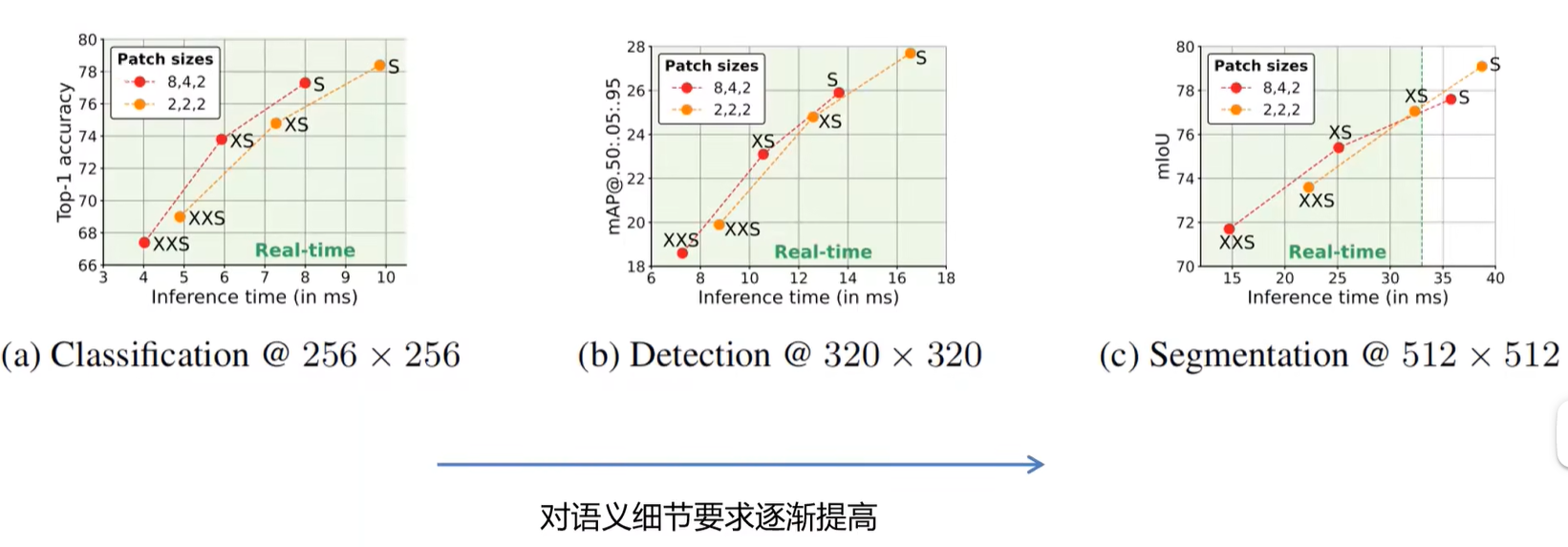
Patch Size对性能的影响
作者有做两组对比实验,分别对应的Patch Size时8,4,2和2,2,2。这三个数字分别对应的是针对下采样的8倍,16倍以及32倍的 特征图。并且如下图所示,分别在分类、目标检测和分割任务上进行了对比。横坐标对应的时推理时间,希望越小越好,纵坐标对应的时在各项任务上的一个指标,一般都是越大越好。所以越靠近坐标的左上方代表模型的综合性能越好。
模型详细配置
一共有三类模型配置:
- MobileViT-S(small);
- MobileViT-XS(extra small);
- MobileViT-XXS(extra extra small)
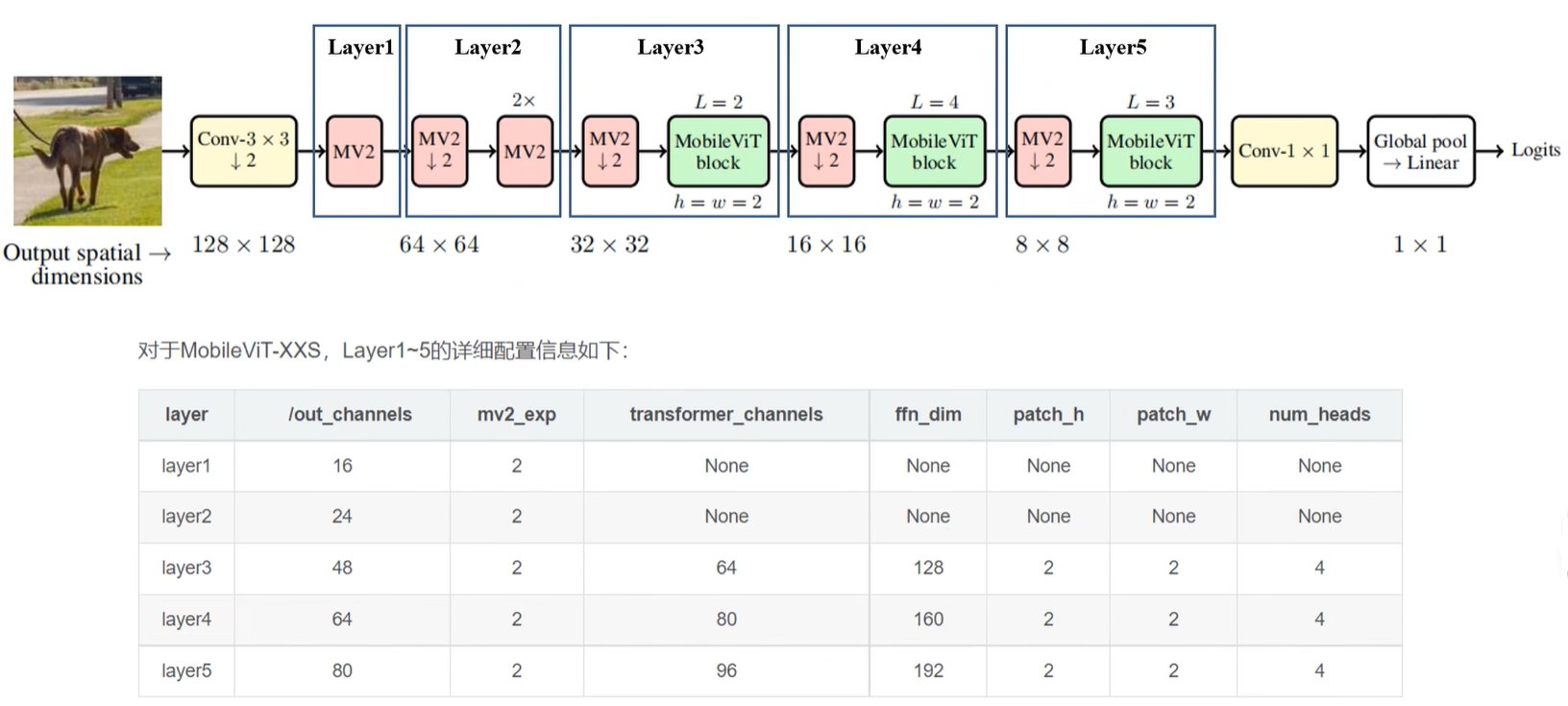
out_channels:每一个layer输出的一个特征图的通道数;mv2_exp:在Inverted Residual模块当中的expansion ratio;transformer_channels:输入transformer block的一个token的向量长度或者输入特征图的通道数;ffn_dim:transformer block MLP中间层的一个节点个数;patch_h和patch_w:patch size的大小;num_heads:transformer block当中的Muti-Head Self-Attention的header的个数。
Pytorch搭建
工程目录
1 | ├── Test15_MobileViT |
model
1 | """ |
ConvLayer类
1 | class ConvLayer(nn.Module): |
MV2(InvertedResidual类)
skip_connection:是否使用shortcut
hidden_dim:通过第一个1x1卷积层之后将特征图的通道数调整为多少
1 | class InvertedResidual(nn.Module): |
MobileViTBlock
transformer_dim:输入到Transformer Encoder Block中每个token所对应的序列长度;
ffn_dim:Transformer Encoder Block中MLP结构的第一个全连接层的节点个数;
n_transformer_blocks:global representations当中重复堆叠Transformer Encoder Block的次数;
head_dim:在做Muti-Head Self-Attention时每个header所对应的dimension;
1 | class MobileViTBlock(nn.Module): |
unfolding函数
1 | def unfolding(self, x: Tensor) -> Tuple[Tensor, Dict]: |
folding函数
1 | def folding(self, x: Tensor, info_dict: Dict) -> Tensor: |
正向传播函数
1 | def forward(self, x: Tensor) -> Tensor: |
MobileViT类
1 | class MobileViT(nn.Module): |
_make_layer函数
1 | def _make_layer(self, input_channel, cfg: Dict) -> Tuple[nn.Sequential, int]: |
_make_mobilenet_layer函数
1 |
|
_make_mit_layer函数
1 |
|
init_parameters函数
1 |
|
forward函数
1 | def forward(self, x: Tensor) -> Tensor: |
transformer
1 | from typing import Optional |
unfold_test
up将把token按照相同颜色抽离出来的那部分代码自己重新写了,会更加容易理解。(这一块看图理解了,但代码是怎么据图片那样将颜色相同的token拼接成一个向量的,还没搞明白)
1 | import time |
model_config
1 | def get_config(mode: str = "xxs") -> dict: |
train
1 | import os |
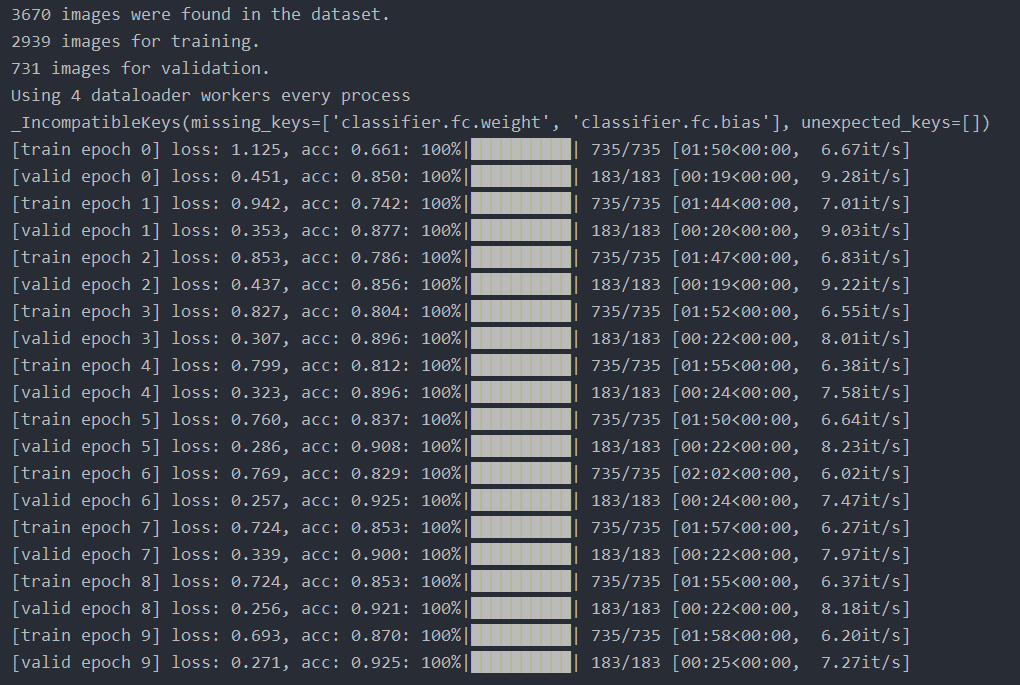
训练结果
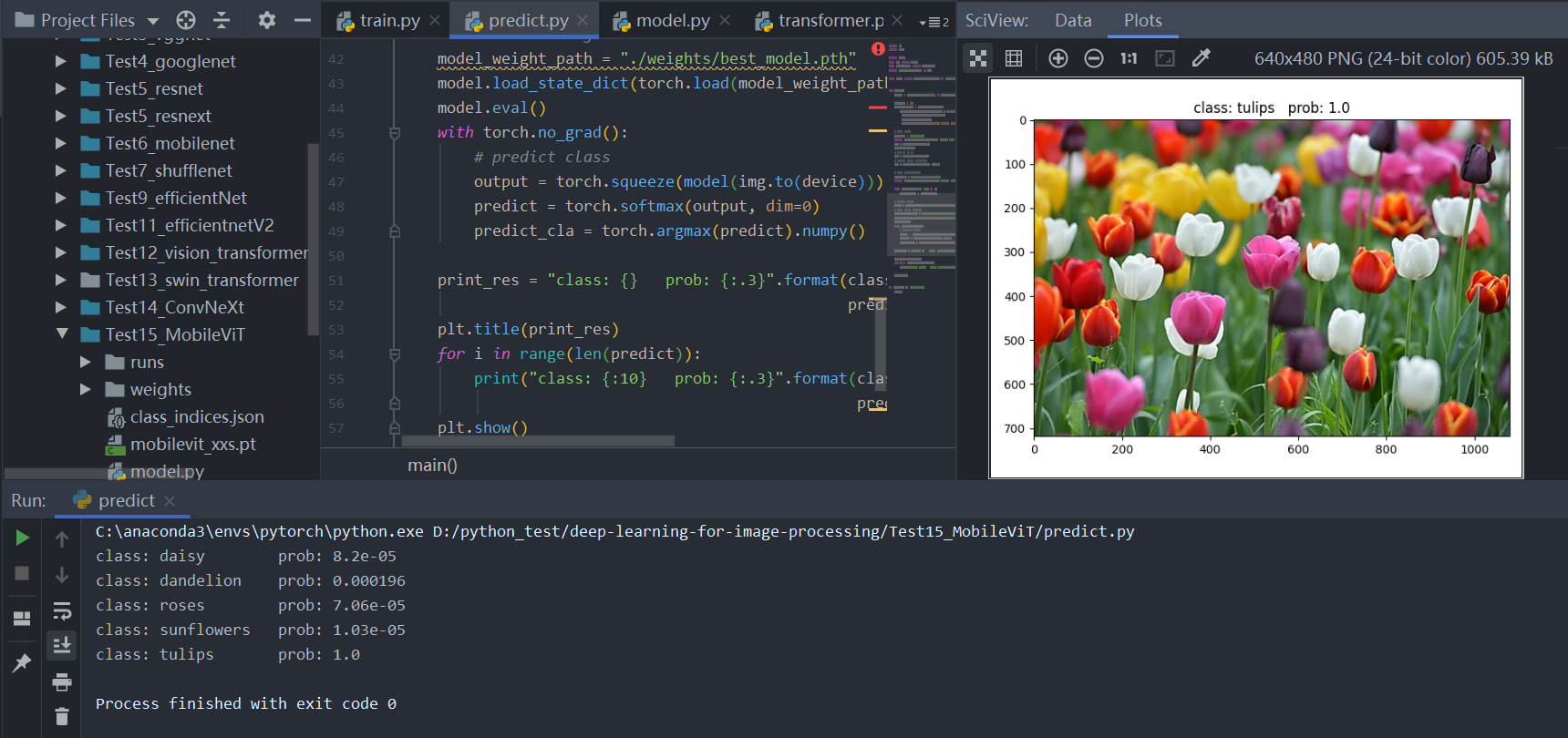
predict
1 | import os |
预测结果