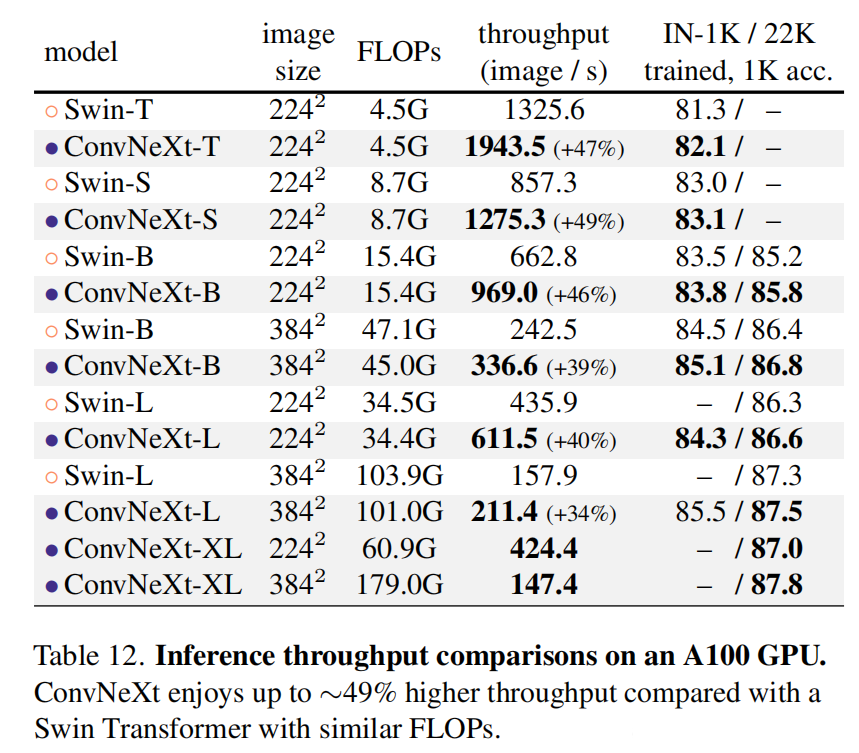
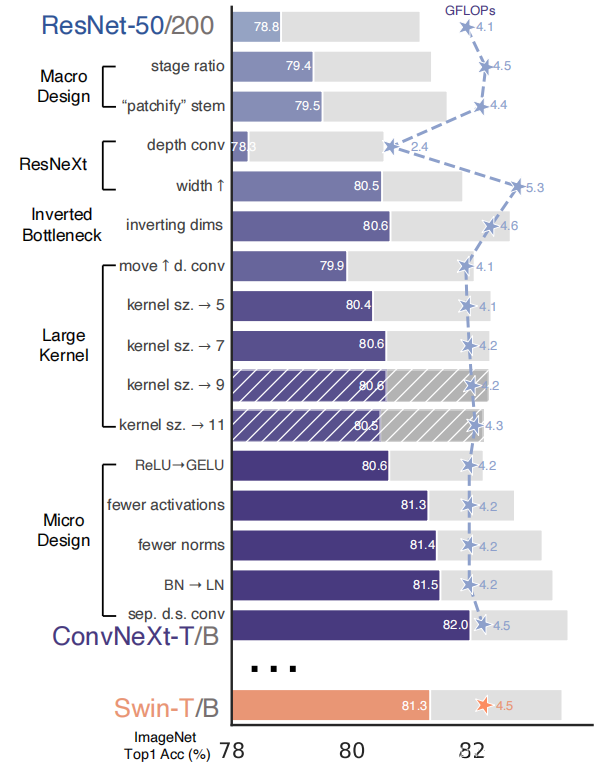
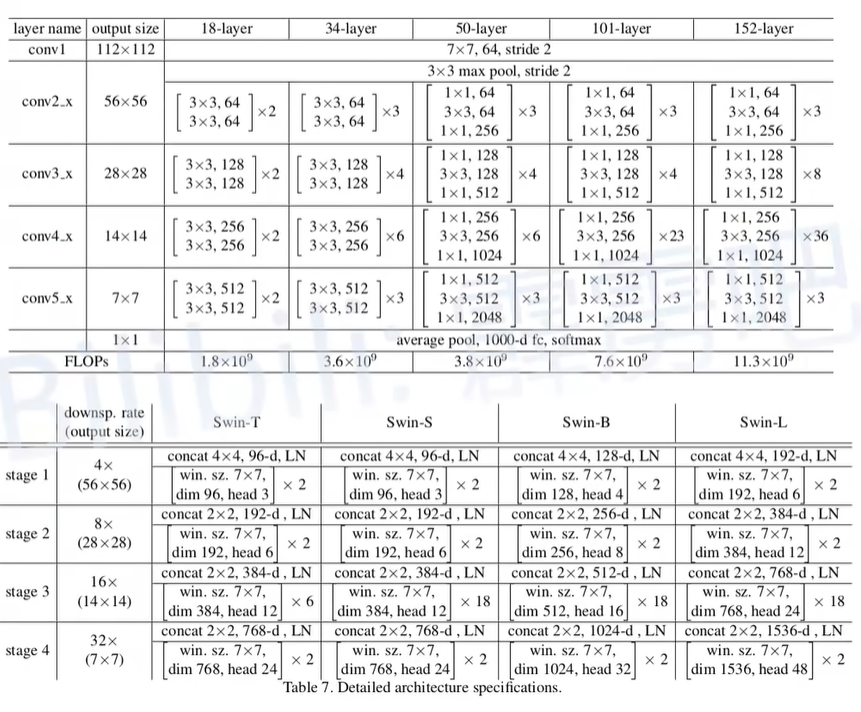
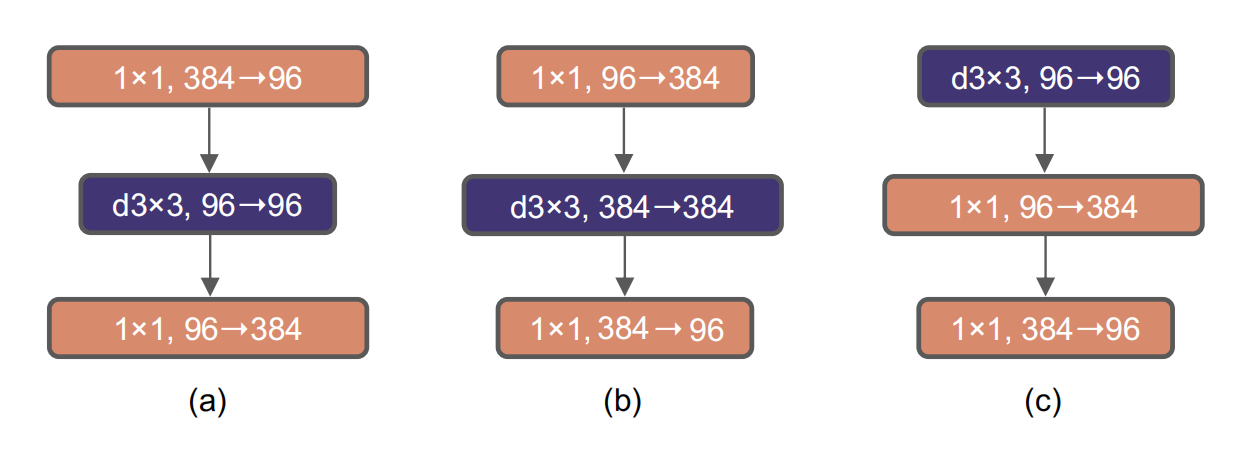
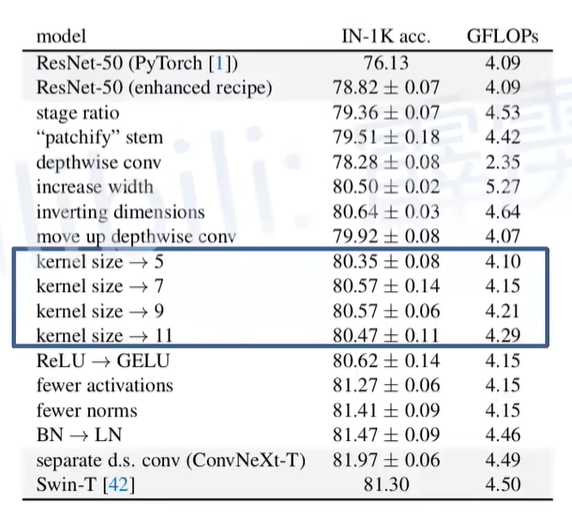
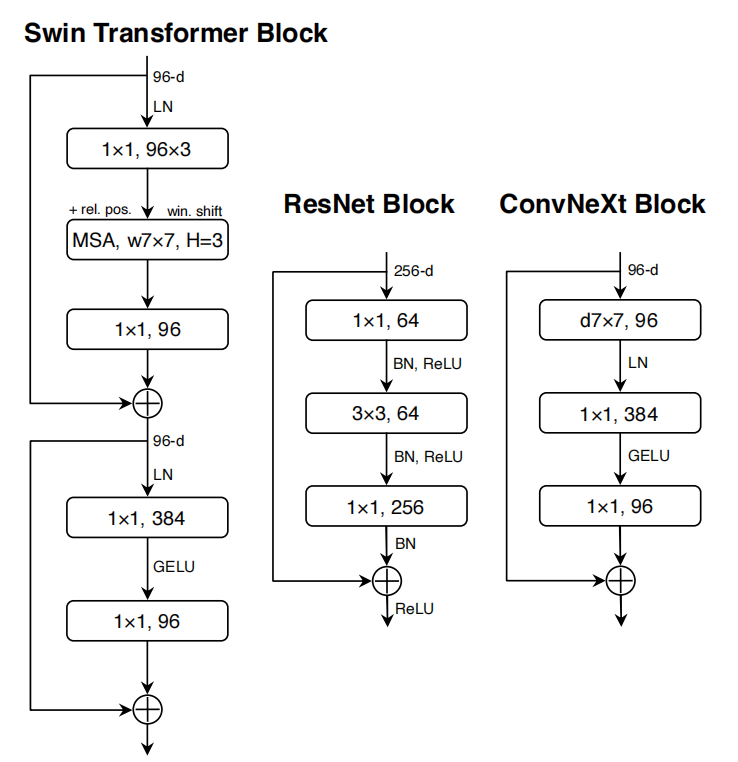
自从ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱,而卷积神经网络已经开始慢慢淡出舞台中央。20221月,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率(下图所示)。
defdrop_path(x, drop_prob: float = 0., training: bool = False): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument. """ if drop_prob == 0.ornot training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output
classDropPath(nn.Module): """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). """ def__init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob
classLayerNorm(nn.Module): r""" LayerNorm that supports two data formats: channels_last (default) or channels_first. The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch_size, height, width, channels) while channels_first corresponds to inputs with shape (batch_size, channels, height, width). """
def__init__(self, normalized_shape, eps=1e-6, data_format="channels_last"): super().__init__() self.weight = nn.Parameter(torch.ones(normalized_shape), requires_grad=True) self.bias = nn.Parameter(torch.zeros(normalized_shape), requires_grad=True) self.eps = eps self.data_format = data_format if self.data_format notin ["channels_last", "channels_first"]: raise ValueError(f"not support data format '{self.data_format}'") self.normalized_shape = (normalized_shape,)
defforward(self, x: torch.Tensor) -> torch.Tensor: if self.data_format == "channels_last": return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps) elif self.data_format == "channels_first": # [batch_size, channels, height, width] mean = x.mean(1, keepdim=True) var = (x - mean).pow(2).mean(1, keepdim=True) x = (x - mean) / torch.sqrt(var + self.eps) x = self.weight[:, None, None] * x + self.bias[:, None, None] return x
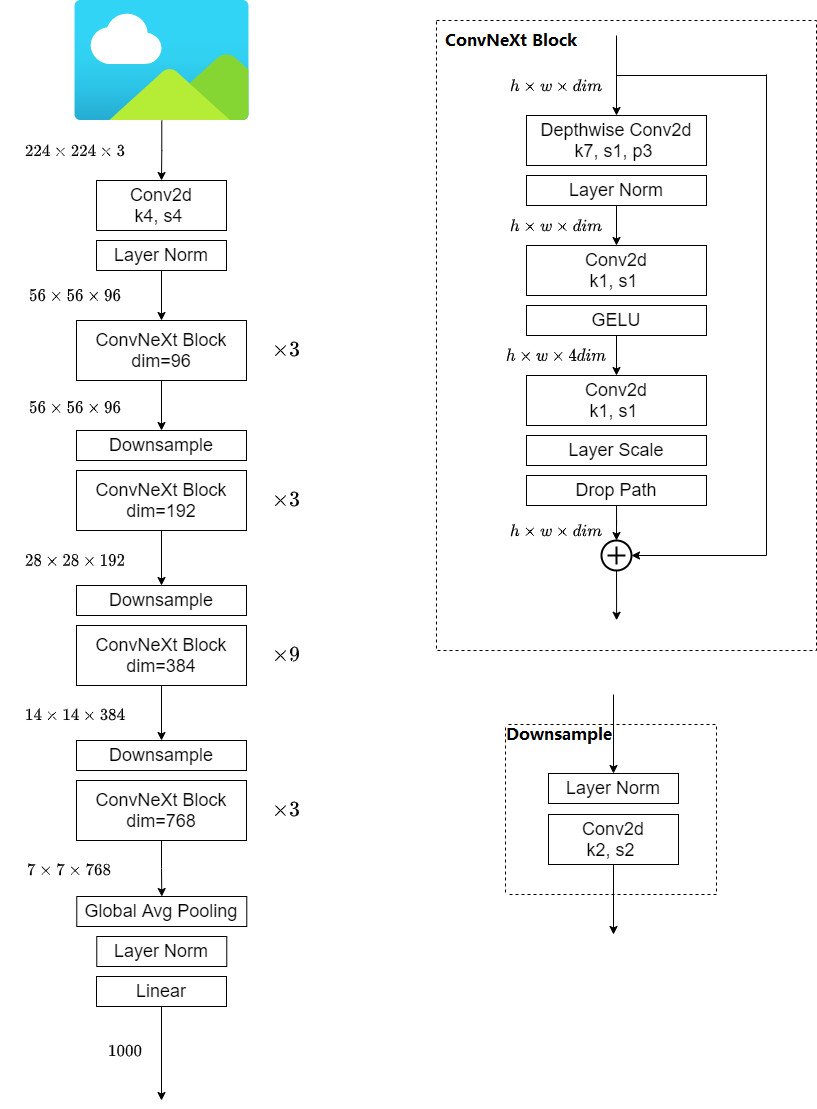
classConvNeXt(nn.Module): r""" ConvNeXt A PyTorch impl of : `A ConvNet for the 2020s` - https://arxiv.org/pdf/2201.03545.pdf Args: in_chans (int): Number of input image channels. Default: 3 num_classes (int): Number of classes for classification head. Default: 1000 depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3] dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768] drop_path_rate (float): Stochastic depth rate. Default: 0. layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6. head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1. """ def__init__(self, in_chans: int = 3, num_classes: int = 1000, depths: list = None, dims: list = None, drop_path_rate: float = 0., layer_scale_init_value: float = 1e-6, head_init_scale: float = 1.): super().__init__() self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4), LayerNorm(dims[0], eps=1e-6, data_format="channels_first")) self.downsample_layers.append(stem)
# 对应stage2-stage4前的3个downsample for i inrange(3): downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"), nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2)) self.downsample_layers.append(downsample_layer)
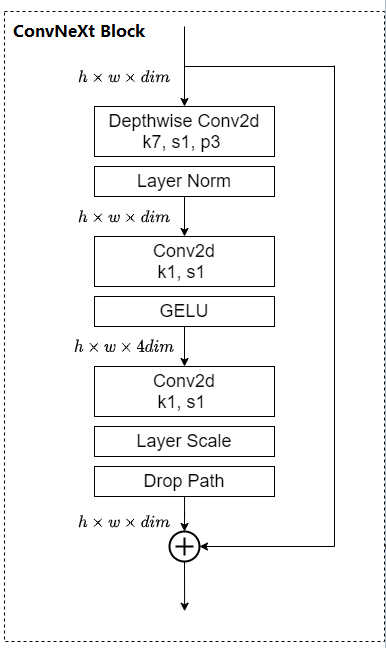
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple blocks # 等差数列 dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0 # 构建每个stage中堆叠的block for i inrange(4): stage = nn.Sequential( *[Block(dim=dims[i], drop_rate=dp_rates[cur + j], layer_scale_init_value=layer_scale_init_value) for j inrange(depths[i])] ) self.stages.append(stage) # cur代表在当前Stage之前构建好了的block的个数 cur += depths[i]
import torch import torch.optim as optim from torch.utils.tensorboard import SummaryWriter from torchvision import transforms
from my_dataset import MyDataSet from model import convnext_tiny as create_model from utils import read_split_data, create_lr_scheduler, get_params_groups, train_one_epoch, evaluate
defmain(args): device = torch.device(args.device if torch.cuda.is_available() else"cpu") print(f"using {device} device.")
if os.path.exists("./weights") isFalse: os.makedirs("./weights")
model = create_model(num_classes=args.num_classes).to(device)
if args.weights != "": assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights) weights_dict = torch.load(args.weights, map_location=device)["model"] # 删除有关分类类别的权重 for k inlist(weights_dict.keys()): if"head"in k: del weights_dict[k] print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers: for name, para in model.named_parameters(): # 除head外,其他权重全部冻结 if"head"notin name: para.requires_grad_(False) else: print("training {}".format(name))
# pg = [p for p in model.parameters() if p.requires_grad] pg = get_params_groups(model, weight_decay=args.wd) optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=args.wd) lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True, warmup_epochs=1)