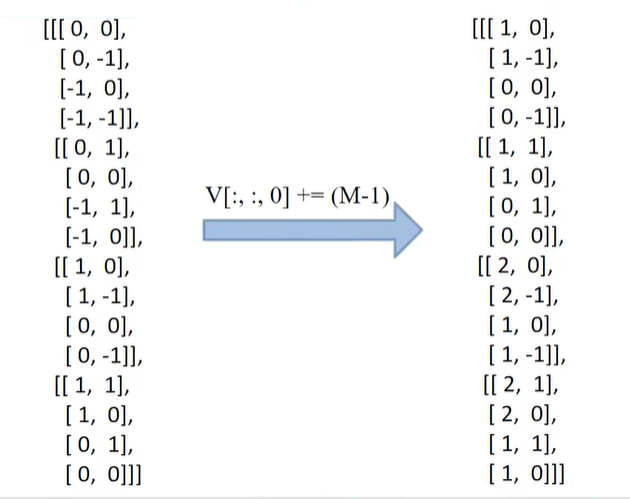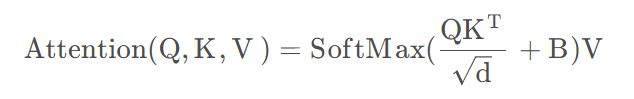工程目录
1 2 3 4 5 6 7 8 9 10 ├── swin_transformer ├── model.py(模型文件) ├── my_dataset.py(数据处理文件) ├── train.py(调用模型训练,自动生成class_indices.json,swin transformer.pth文件) ├── predict.py(调用模型进行预测) ├── utils.py(工具文件,用得上就对了) ├── tulip.jpg(用来根据前期的训练结果来predict图片类型) └── swin_tiny_patch4_window7_224.pth(迁移学习,提前下载好swin_tiny_patch4_window7_224.pth权重脚本) └── data_set └── data数据集
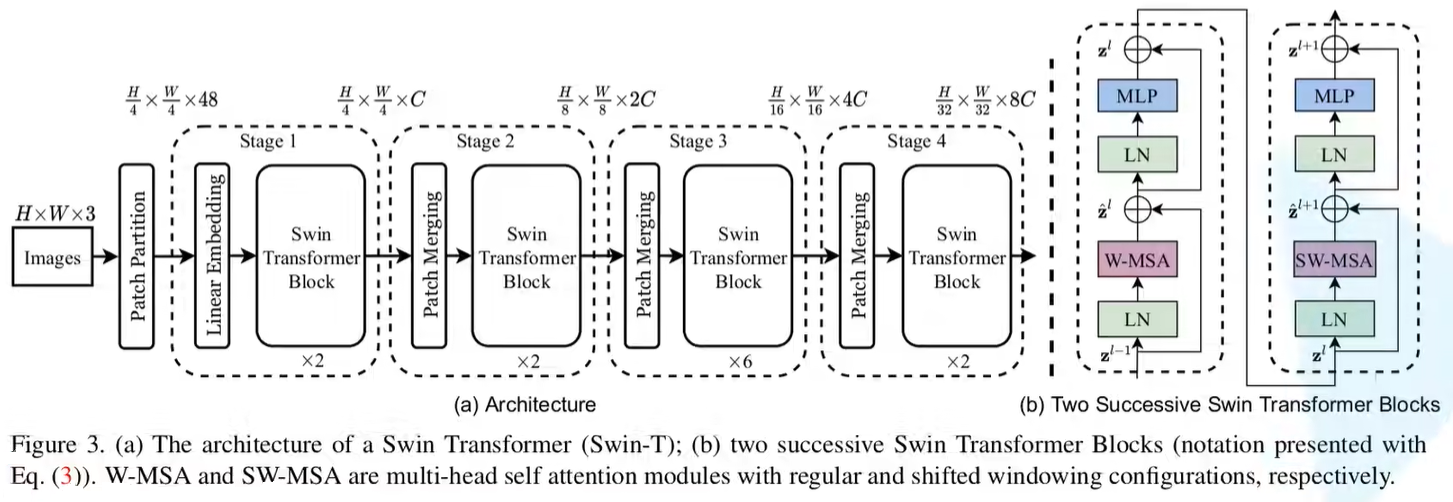
Swin-T网络结构
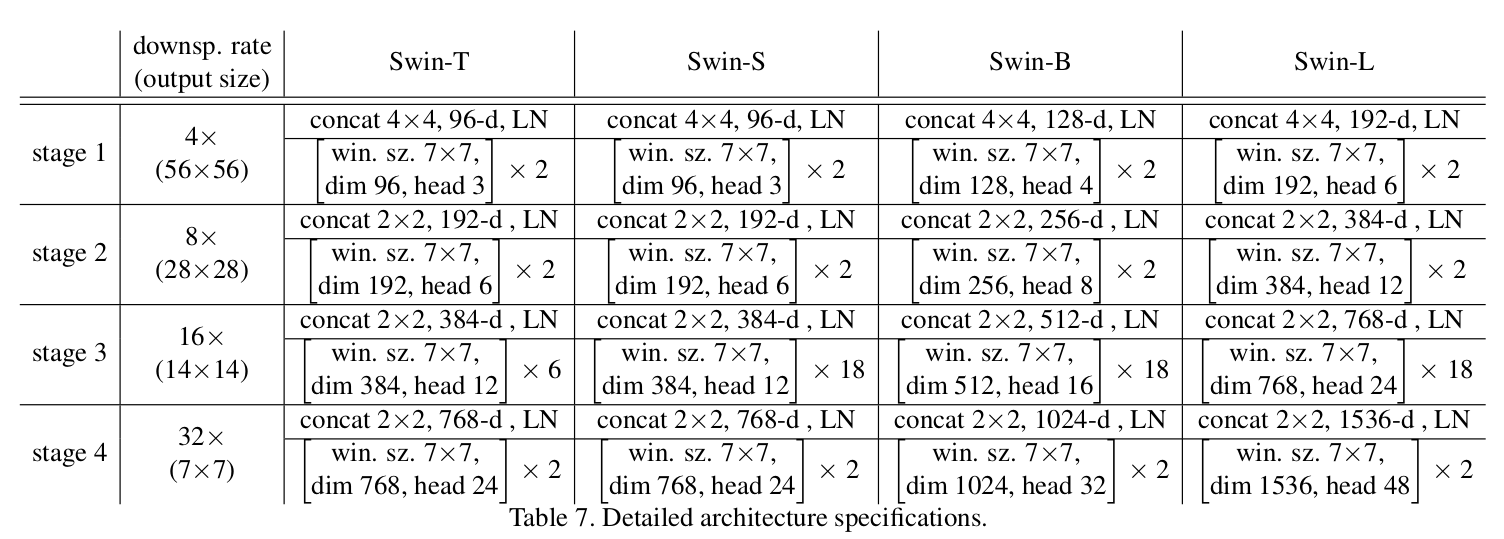
Swin Transformer网络参数表
模型文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 """ Swin Transformer A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` - https://arxiv.org/pdf/2103.14030 Code/weights from https://github.com/microsoft/Swin-Transformer """ import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.utils.checkpoint as checkpointimport numpy as npfrom typing import Optional def drop_path_f (x, drop_prob: float = 0. , training: bool = False ): class DropPath (nn.Module): def __init__ (self, drop_prob=None ): def forward (self, x ): def window_partition (x, window_size: int ): def window_reverse (windows, window_size: int , H: int , W: int ): class PatchEmbed (nn.Module): def __init__ (self, patch_size=4 , in_c=3 , embed_dim=96 , norm_layer=None ): def forward (self, x ): class PatchMerging (nn.Module): def __init__ (self, dim, norm_layer=nn.LayerNorm ): def forward (self, x, H, W ): class Mlp (nn.Module): def __init__ (self, in_features, hidden_features=None , out_features=None , act_layer=nn.GELU, drop=0. ): def forward (self, x ): class WindowAttention (nn.Module): def __init__ (self, dim, window_size, num_heads, qkv_bias=True , attn_drop=0. , proj_drop=0. ): def forward (self, x, mask: Optional [torch.Tensor] = None ): class SwinTransformerBlock (nn.Module): def __init__ (self, dim, num_heads, window_size=7 , shift_size=0 , mlp_ratio=4. , qkv_bias=True , drop=0. , attn_drop=0. , drop_path=0. , act_layer=nn.GELU, norm_layer=nn.LayerNorm ): def forward (self, x, attn_mask ): class BasicLayer (nn.Module): def __init__ (self, dim, depth, num_heads, window_size, mlp_ratio=4. , qkv_bias=True , drop=0. , attn_drop=0. , drop_path=0. , norm_layer=nn.LayerNorm, downsample=None , use_checkpoint=False ): def create_mask (self, x, H, W ): def forward (self, x, H, W ): class SwinTransformer (nn.Module): def __init__ (self, patch_size=4 , in_chans=3 , num_classes=1000 , embed_dim=96 , depths=(2 , 2 , 6 , 2 3 , 6 , 12 , 24 window_size=7 , mlp_ratio=4. , qkv_bias=True , drop_rate=0. , attn_drop_rate=0. , drop_path_rate=0.1 , norm_layer=nn.LayerNorm, patch_norm=True , use_checkpoint=False , **kwargs ): def _init_weights (self, m ): def forward (self, x ): def swin_tiny_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): def swin_small_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): def swin_base_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): def swin_base_patch4_window12_384 (num_classes: int = 1000 , **kwargs ): def swin_base_patch4_window7_224_in22k (num_classes: int = 21841 , **kwargs ): def swin_base_patch4_window12_384_in22k (num_classes: int = 21841 , **kwargs ): def swin_large_patch4_window7_224_in22k (num_classes: int = 21841 , **kwargs ): def swin_large_patch4_window12_384_in22k (num_classes: int = 21841 , **kwargs ):
SwinTransformer类继承来自于官方的nn.Module父类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class SwinTransformer (nn.Module): r""" Swin Transformer A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` - https://arxiv.org/pdf/2103.14030 Args: patch_size (int | tuple(int)): Patch size. Default: 4 in_chans (int): Number of input image channels. Default: 3 num_classes (int): Number of classes for classification head. Default: 1000 embed_dim (int): Patch embedding dimension. Default: 96 depths (tuple(int)): Depth of each Swin Transformer layer. num_heads (tuple(int)): Number of attention heads in different layers. window_size (int): Window size. Default: 7 mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4 qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True drop_rate (float): Dropout rate. Default: 0 attn_drop_rate (float): Attention dropout rate. Default: 0 drop_path_rate (float): Stochastic depth rate. Default: 0.1 norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm. patch_norm (bool): If True, add normalization after patch embedding. Default: True use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False """
初始化函数 传入的参数:
patch_size:在Swin Transformer网络架构图中,经过Stage1前面的Patch Partition之后下采样多少倍 ,根据网络架构图,为下采样4倍,也就是高度和宽度都下采样4倍,因此patch_size = 4;in_chans:输入图片的深度,该处输入的为RGB彩色图像,因此in_chans = 3;num_classes:分类类别数;embed_dim:指通过Stage1的Linear Embedding之后映射得到的,即Swin Transformer网络架构图中的C ,因此在通过Stage1的Linear Embedding之后的搭配的C为96,且之后的Stage输出的channel直接翻倍即可;depths:对应每一个Stage当中重复使用Swin Transformer Block的次数 ,例如对应Swin-T此处为(2,2,6,2);num_heads:在Swin Transformer Block中所采用的Muti-Head self-Attention的head个数 ,对应Swin-T的网络参数表的head个数为(3,6,12,24);window_size:对应W-MSA和SW-MSA所采用window的大小;mlp_ratio:在Mlp模块当中,第一个全连接层将channel给翻多少倍;qkv_bias:在Muti-Head self-Attention模块当中是否使用偏置;drop_rate:第一个drop_rate除了在pos_drop中使用到,还在mlp以及其他地方使用到;attn_drop_rate:对应在Muti-Head self-Attention模块当中所采用的drop_rate;drop_path_rate:对应每一个Swin Transformer Block所采用的drop_rate(注意:drop_path_rate在Swin Transformer Block当中是递增的 );norm_layer:默认使用LayerNorm;patch_norm:如果使用的话,会在patch embedding之后使用;use_checkpoint:官方给出介绍是使用的话会减少内存的,但官方代码False;
代码语句解释:
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1)):stage4输出特征矩阵的channels = C * 2^3 = 8C;
self.patch_embed = PatchEmbed(...):将图片划分为一个个没有重叠的patches,对应的是Stage1前面的Patch Partition以及STage1的Patch Embedding(具体实现方式可看后文PatchEmbed类);
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]:关于drop_path_rate的设置,对于一系列Swin Transformer Block当中,所采用的drop_rate是从0慢慢增长到所指定的drop_path_rate。此处直接使用官方的linspace方法,指定初始的数值0,以及末尾的数值drop_path_rate,和步数sum(depths),即会自动生成针对每一个Swin Transformer Block所采用的drop_rate;
创建一个self.layers = nn.ModuleList(),将会通过一个循环来遍历生成每个Stage;
注意:代码与Swub-T的网络结构图有些差异 。
在图中每个Stage是先进行Patch Merging之后接着一个Swin Transformer Block (Stage1是先进行Linear Embedding之后接着一个Swin Transformer Block),也就是图中虚线的部分。
但在源码中,在通过循环来遍历生成每个Stage中,是先进行Swin Transformer Block,后接着一个Patch Merging (在Stage4的Swin Transformer Block后已经没有Patch Merging,所以只有Swin Transformer Block),等于是将图中的虚线向右平移了一个模块。
1 2 3 4 5 6 7 8 9 10 11 12 layers = BasicLayer(dim=int (embed_dim * 2 ** i_layer), depth=depths[i_layer], num_heads=num_heads[i_layer], window_size=window_size, mlp_ratio=self.mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[sum (depths[:i_layer]):sum (depths[:i_layer + 1 ])], norm_layer=norm_layer, downsample=PatchMerging if (i_layer < self.num_layers - 1 ) else None , use_checkpoint=use_checkpoint)
dim=int(embed_dim * 2 ** i_layer):对于每一个Stage而言,所传入的特征矩阵的dimension都是前一个Stage的dimension的2倍;depth=depths[i_layer]:在当前的Stage当中,要重复堆叠多少次Swin Transformer Block,即可在depths列表中取对应索引的元素;downsample=PatchMerging if (i_layer < self.num_layers - 1) else None:针对每一个Stage所包含的Patch Merging是接在Swin Transformer Block后面的(也就是前文提到的原码与网络结构图不相符的地方),因此进行了判断,如果当前在Stage1、2、3,则需要使用Patch Merging,如果是Stage4,则不需要使用 (详细可看后文的PatchMerging类详解);
对于之后的classifier分类层而言,还需通过一个norm层、自适应全局平均池化、全连接层进行输出。
self.apply(self._init_weights):之后通过apply方法调用_init_weights对模型进行权重初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def __init__ (self, patch_size=4 , in_chans=3 , num_classes=1000 , embed_dim=96 , depths=(2 , 2 , 6 , 2 3 , 6 , 12 , 24 window_size=7 , mlp_ratio=4. , qkv_bias=True , drop_rate=0. , attn_drop_rate=0. , drop_path_rate=0.1 , norm_layer=nn.LayerNorm, patch_norm=True , use_checkpoint=False , **kwargs ): super ().__init__() self.num_classes = num_classes self.num_layers = len (depths) self.embed_dim = embed_dim self.patch_norm = patch_norm self.num_features = int (embed_dim * 2 ** (self.num_layers - 1 )) self.mlp_ratio = mlp_ratio self.patch_embed = PatchEmbed( patch_size=patch_size, in_c=in_chans, embed_dim=embed_dim, norm_layer=norm_layer if self.patch_norm else None ) self.pos_drop = nn.Dropout(p=drop_rate) dpr = [x.item() for x in torch.linspace(0 , drop_path_rate, sum (depths))] self.layers = nn.ModuleList() for i_layer in range (self.num_layers): layers = BasicLayer(dim=int (embed_dim * 2 ** i_layer), depth=depths[i_layer], num_heads=num_heads[i_layer], window_size=window_size, mlp_ratio=self.mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[sum (depths[:i_layer]):sum (depths[:i_layer + 1 ])], norm_layer=norm_layer, downsample=PatchMerging if (i_layer < self.num_layers - 1 ) else None , use_checkpoint=use_checkpoint) self.layers.append(layers) self.norm = norm_layer(self.num_features) self.avgpool = nn.AdaptiveAvgPool1d(1 ) self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() self.apply(self._init_weights)
初始化权重函数
1 2 3 4 5 6 7 8 def _init_weights (self, m ): if isinstance (m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02 ) if isinstance (m, nn.Linear) and m.bias is not None : nn.init.constant_(m.bias, 0 ) elif isinstance (m, nn.LayerNorm): nn.init.constant_(m.bias, 0 ) nn.init.constant_(m.weight, 1.0 )
正向传播函数 首先对于传入的x先进行patch_embed方法对图像进行下采样4倍,然后就得到输出特征矩阵和对应的H,W(此时x对应的通道排列顺序是[B, L, C])。
之后通过Dropout层按照一定的比例随机丢失一部分输入。
之后遍历初始化函数中创建的layers,也就是nn.ModuleList()。遍历之后就能将数据依次通过Stage1、2、3、4,对应每一个Stage将x和当前的H,W传入,就能得到该Stage之后得到的x输出以及H,W,然后再传入到下一个Stage当中。
当得到Stage4的输出之后,进行一个LayerNorm层(此时x对应的通道排列顺序是[B, L, C])。通过transpose方法将L和C互换位置(此时x对应的通道排列顺序是[B, C, L]),通过自适应的平均池化avgpool,将L池化为1(此时x对应的通道排列顺序是[B, C, 1])。
再通过flatten方法从C维度开始向后展平(此时x对应的通道排列顺序是[B, C]),最后再通过一个head全连接层得到输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 def forward (self, x ): x, H, W = self.patch_embed(x) x = self.pos_drop(x) for layer in self.layers: x, H, W = layer(x, H, W) x = self.norm(x) x = self.avgpool(x.transpose(1 , 2 )) x = torch.flatten(x, 1 ) x = self.head(x) return x
PatchEmbed类
patch_size:下采样的倍率;in_c:输入图像的深度;embed_dim:通过Stage1的Linear Embedding之后映射得到的深度;norm_layer:传入的LayerNorm
初始化函数
创建一个卷积层,下采样其实就是通过卷积层实现的,因此输入特征矩阵的channel为in_c,输出特征矩阵的channel为embed_dim,卷积核大小为patch_size,步距也为patch_size。
如果有传入norm_layer则直接使用传入的,如果没有传入则直接做线性映射(指不做处理)
正向传播函数
首先获取传入图像的高宽,之后进行判断(如果图像的高度或者宽度不是patch_size的整数倍,则需要进行padding)。如果pad_input = True的话,也就是说明高或者宽不是patch_size的整数倍,需要进行padding,则直接使用官方的pad方法对x进行padding。
1 2 3 4 5 x = F.pad(x, (0 , self.patch_size[1 ] - W % self.patch_size[1 ], 0 , self.patch_size[0 ] - H % self.patch_size[0 ], 0 , 0 ))
会对宽度方向的右侧以及高度方向的底部padding
经过padding之后H,W即为patch_size的整数倍,则可以直接使用下采样层(也就是卷积层)。下采样之后,记录以下此刻的H,W。再对x进行维度2上开始展平处理(即flatten: [B, C, H, W] -> [B, C, HW]),再通过transpose将位置1,2上的数据进行交换(即transpose: [B, C, HW] -> [B, HW, C])。
最后再用LayerNorm层对channel维度做LayerNorm的处理之后,返回此时的特征矩阵,以及通过下采样之后的H,W。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class PatchEmbed (nn.Module): """ 2D Image to Patch Embedding """ def __init__ (self, patch_size=4 , in_c=3 , embed_dim=96 , norm_layer=None ): super ().__init__() patch_size = (patch_size, patch_size) self.patch_size = patch_size self.in_chans = in_c self.embed_dim = embed_dim self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward (self, x ): _, _, H, W = x.shape pad_input = (H % self.patch_size[0 ] != 0 ) or (W % self.patch_size[1 ] != 0 ) if pad_input: x = F.pad(x, (0 , self.patch_size[1 ] - W % self.patch_size[1 ], 0 , self.patch_size[0 ] - H % self.patch_size[0 ], 0 , 0 )) x = self.proj(x) _, _, H, W = x.shape x = x.flatten(2 ).transpose(1 , 2 ) x = self.norm(x) return x, H, W
PatchMerfing类
初始化函数
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False):创建全连接层,输入的dimension是4倍的dim,输出的dimension是2倍的dim
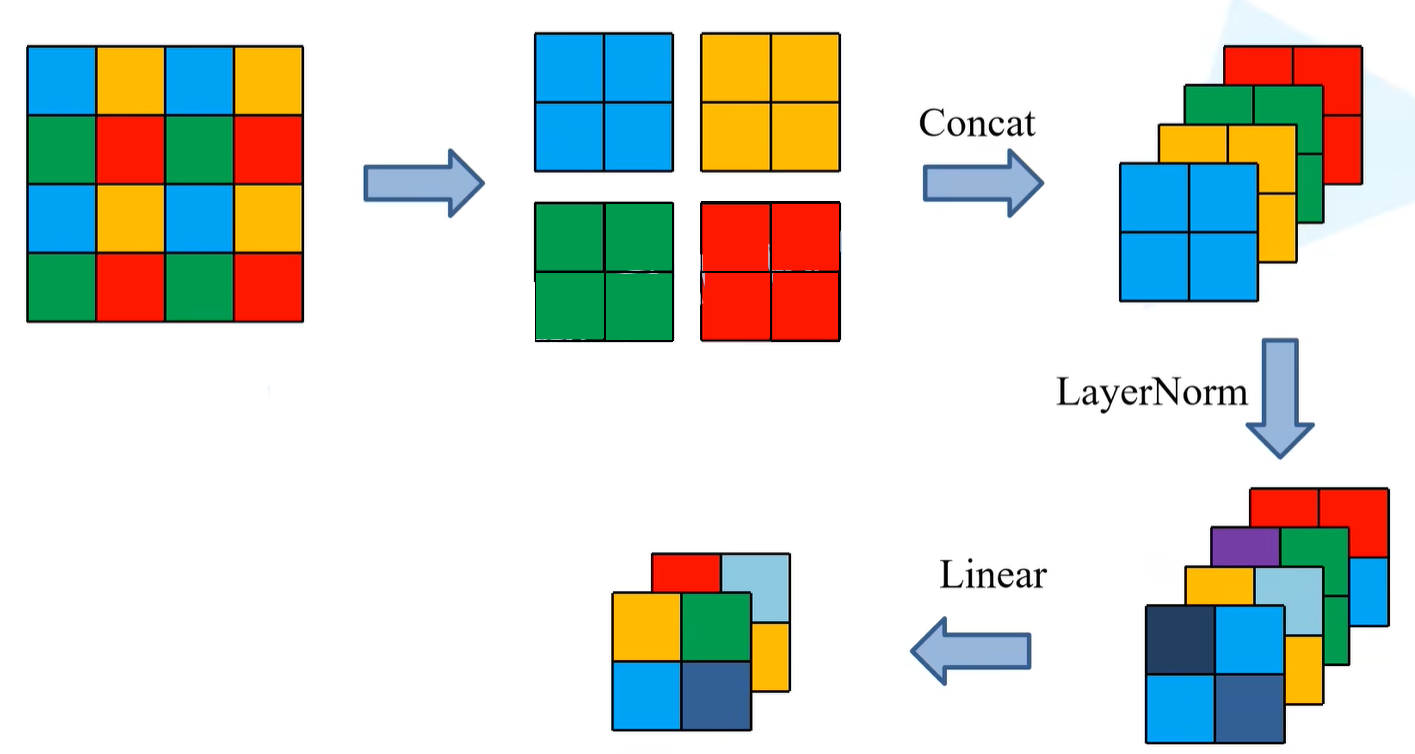
如上图所示,在Patch Merging中,首先是把输入的feature map每2x2做一个窗口进行分割,分割之后同样位置上的元素进行拼接得到4个特征矩阵(上图(上中)),再通过channel方向进行concat拼接(上图(上右)),拼接之后在channel方向进行LayerNorm处理(上图(下右)),最后再通过全连接Linear层做一个线性的映射(上图(下中))。
对于全连接层而言,输入特征矩阵的channel = 最原始(上图(上左))的feature map的channel = 4,因此设置为4*dim。输出的特征矩阵channel是将上图(下右)的特征矩阵channel减半,也就是从4*dim变为2*dim。
self.norm = norm_layer(4 * dim):对应的是上图(下右),因此使用4*dim。
正向传播函数
forward(self, x, H, W):x为输入的数据,H,W为记录输入当前特征矩阵的高宽。因为当前输入的特征矩阵的通道排列顺序是x: B, H*W, C,所以只知道高和宽的乘积,并不知道分别的数是多少;
pad_input = (H % 2 == 1) or (W % 2 == 1):因为在PatchMerfing当中是需要下采样2倍的,如果传入的x的高和宽不是2的整数倍的话,需要进行padding;
如果H或者W不是2的整数倍的话,pad_input = True,则需要进行padding。注意此时x的通道排列顺序是[B,H,W,C],pad方法是pad最后三个维度,也就是这里的H,W,C。
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2)):这里给出的参数,是从最后一个维度向前设置的。也就是说(0, 0, 0, W % 2, 0, H % 2)最前面的0,0是针对C维度上的padding的参数,后面两个0, W % 2是针对在W方向上padding的参数(宽度方向的右侧补一列0),0, H % 2是针对在H方向上padding的参数(高度方向的底部补一行0)。
即保证H,W是2的整数倍,就可以进行下采样了。
因为是要把输入的feature map分成一个个窗口,再将相同位置处拼接在一起(此时x的通道排列顺序是[B,H,W,C] )。以上文x0为例,batch维度取所有值,在高度和宽度方向首先都从0开始,所对应的就是上图(上左)中蓝色区域的位置,在高度和宽度方向上都是以2为间隔进行采样的,在channel维度上也是取所有值,因此x0 = x[:, 0::2, 0::2, :],于是就可以构建上图(上中)蓝色的feature map。
x1 = x[:, 1::2, 0::2, :]:在x1中对应的的绿色的区域,高度1,宽度0,在高度和宽度方向上都是以2为间隔进行采样的,拼接之后输出为[B, H/2, W/2, C];x2 = x[:, 0::2, 1::2, :]:在x2中对应的的黄色的区域,高度0,宽度1,在高度和宽度方向上都是以2为间隔进行采样的,拼接之后输出为[B, H/2, W/2, C];x3 = x[:, 1::2, 1::2, :]:在x3中对应的的红色的区域,高度1,宽度1,在高度和宽度方向上都是以2为间隔进行采样的,拼接之后输出为[B, H/2, W/2, C];
x = torch.cat([x0, x1, x2, x3], -1):之后就可以在channel维度上进行concat拼接了,-1指的是最后一个维度,最后一个维度也就是深度channel维度,拼接之后输出为[B, H/2, W/2, 4*C]。
x = x.view(B, -1, 4 * C):再通过view函数进行展平处理,展平之后输出为[B, H/2*W/2, 4*C]
x = self.reduction(x):最后通过创建的全连接层,将[B, H/2*W/2, 4*C]->[B, H/2*W/2, 2*C]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class PatchMerging (nn.Module): r""" Patch Merging Layer. Args: dim (int): Number of input channels. norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__ (self, dim, norm_layer=nn.LayerNorm ): super ().__init__() self.dim = dim self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False ) self.norm = norm_layer(4 * dim) def forward (self, x, H, W ): """ x: B, H*W, C """ B, L, C = x.shape assert L == H * W, "input feature has wrong size" x = x.view(B, H, W, C) pad_input = (H % 2 == 1 ) or (W % 2 == 1 ) if pad_input: x = F.pad(x, (0 , 0 , 0 , W % 2 , 0 , H % 2 )) x0 = x[:, 0 ::2 , 0 ::2 , :] x1 = x[:, 1 ::2 , 0 ::2 , :] x2 = x[:, 0 ::2 , 1 ::2 , :] x3 = x[:, 1 ::2 , 1 ::2 , :] x = torch.cat([x0, x1, x2, x3], -1 ) x = x.view(B, -1 , 4 * C) x = self.norm(x) x = self.reduction(x) return x
BasicLayer类
在这个类当中就是实现每一个Stage,在这个类当中,有传入一系列参数,前文有提到,这里不再赘述。
注意:shift_size:比如说我们在使用SW-MSA模块时,要将窗口向右以及向下偏移多少个像素,所以这里是self.shift_size = window_size // 2(上篇文章有讲)。
创建一个nn.ModuleList的blocks,这里的blocks存储的是在当前Stage中所构建的所有的Swin Transformer Block。那么对于Swin Transformer Block有传入dim、num_heads、window_size、shift_size......。
(注意:对于Swin Transformer Block而言,需要依次使用上图(b)的两个block,W-MSA和SW-MSA,这二者间是成对使用的 ),因此shift_size=0 if (i % 2 == 0) else self.shift_size存在判断,通过循环遍历depth次for i in range(depth)。比如说对于Stage1而言,这里是2次的话,这里的range循环就是两次,就用i对2取余数。比如说当i == 0时,对2取余为0,就意味着当前这个block所采用的是W-MSA;当i == 1的时候,就会将self.shift_size定为它本身,之后会通过判断self.shift_size是否等于0来判断去判断使用的是W-MSA还是SW-MSA 。
downsample:对应的是patch merging类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class BasicLayer (nn.Module): """ A basic Swin Transformer layer for one stage. Args: dim (int): Number of input channels. depth (int): Number of blocks. num_heads (int): Number of attention heads. window_size (int): Local window size. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0 norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False. """ def __init__ (self, dim, depth, num_heads, window_size, mlp_ratio=4. , qkv_bias=True , drop=0. , attn_drop=0. , drop_path=0. , norm_layer=nn.LayerNorm, downsample=None , use_checkpoint=False ): super ().__init__() self.dim = dim self.depth = depth self.window_size = window_size self.use_checkpoint = use_checkpoint self.shift_size = window_size // 2 self.blocks = nn.ModuleList([ SwinTransformerBlock( dim=dim, num_heads=num_heads, window_size=window_size, shift_size=0 if (i % 2 == 0 ) else self.shift_size, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop, drop_path=drop_path[i] if isinstance (drop_path, list ) else drop_path, norm_layer=norm_layer) for i in range (depth)]) if downsample is not None : self.downsample = downsample(dim=dim, norm_layer=norm_layer) else : self.downsample = None def create_mask (self, x, H, W ): def forward (self, x, H, W ):
create_mask
为了防止传入的H和W不是window_size的整数倍,所以会首先将H和W分别除以self.window_size然后向上取整,之后再乘以self.window_size,得到新的H padding之后的值以及W padding之后的值(对于mask而言)。
之后创建一个img_mask,通过zero方法来初始化,shape为1,Hp,Wp,1,设备与传入的x的设备一致(设置为这样的shape是因为:在后面window partition方法中所要求传入的Tensor的shape是这样的)
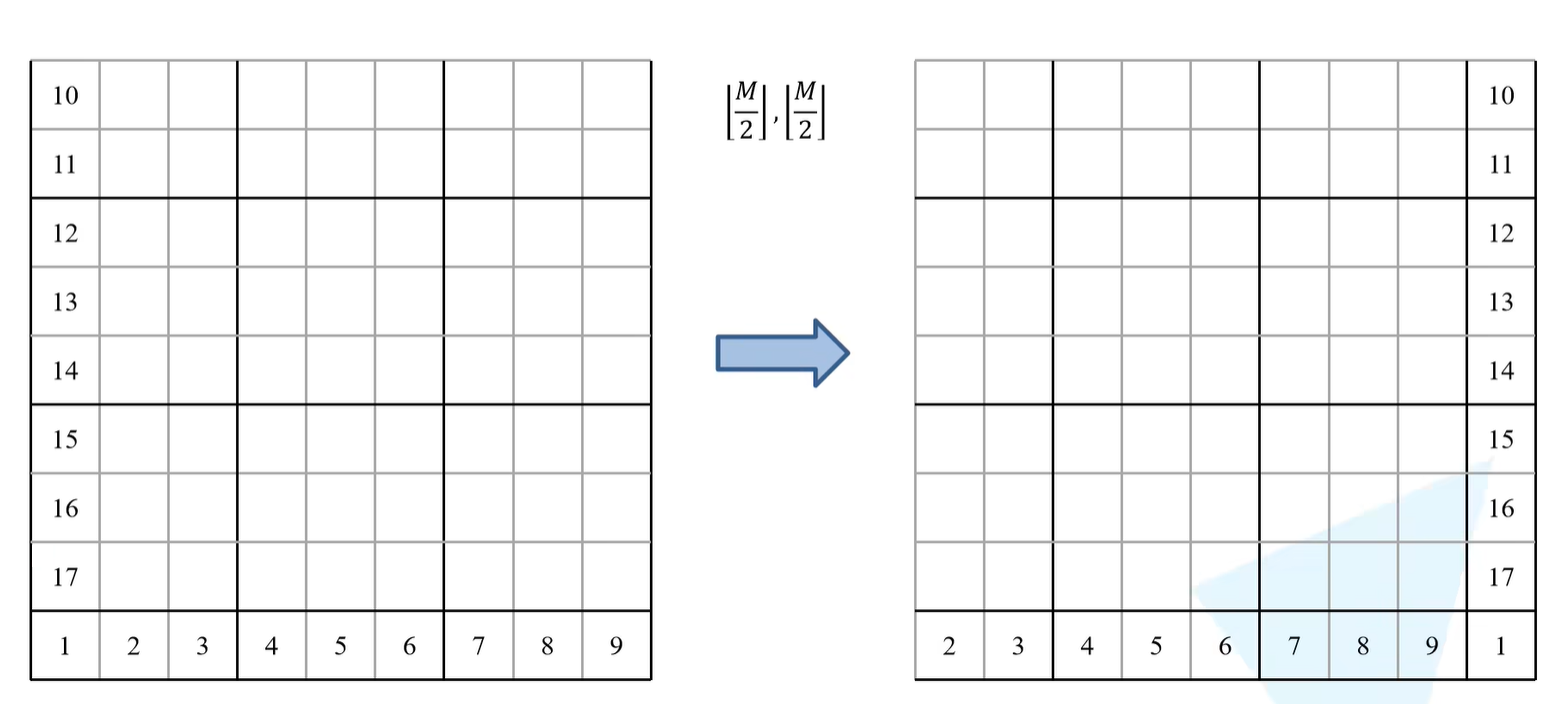
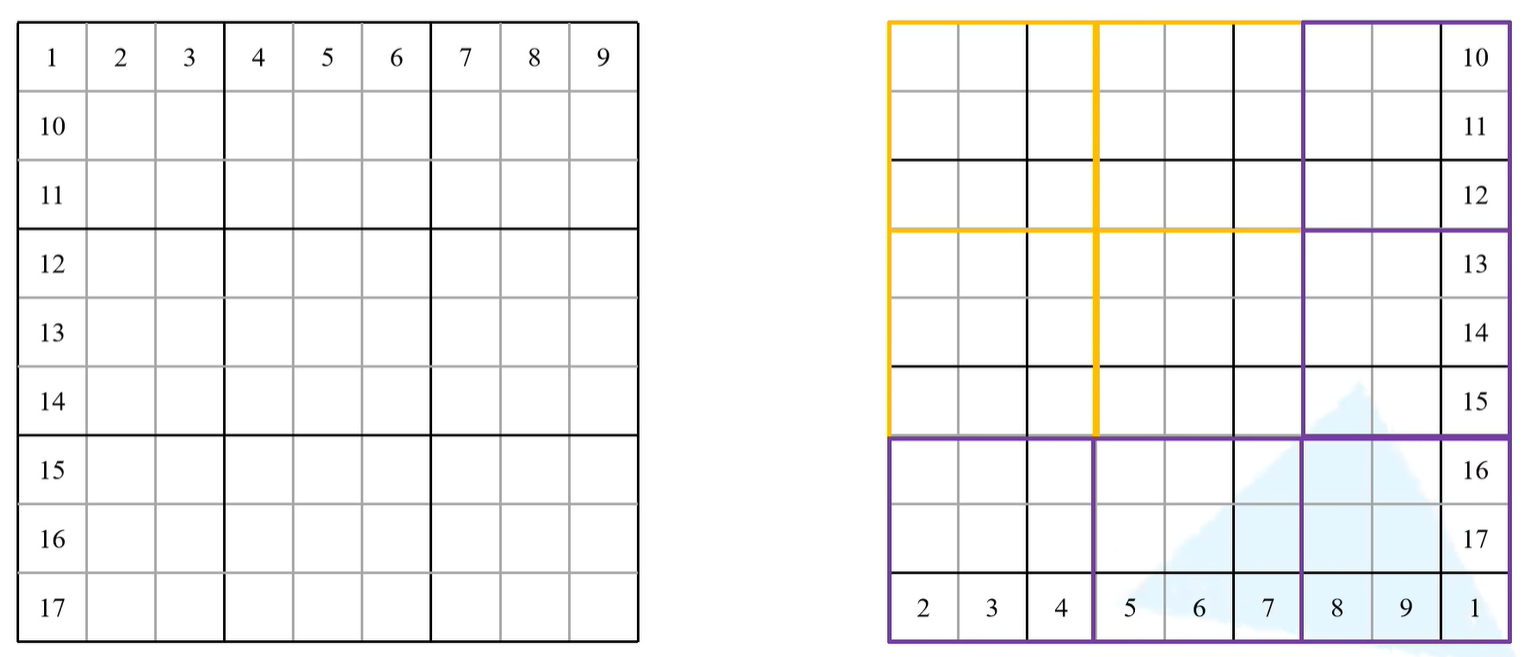
接下来是h_slices和w_slices,二者是一样的,以h_slices为例子。首先通过slice(切片)方法,以上图为例,假设输入的是9x9的feature map,窗口是3x3的,假设需要使用一个shifted window的话,首先用m/2向下取整,再通过指定的window去重新划分window(下图所示)。
由代码来看,一共由3个切片,slice(a,b),a取b不取 。
以h_slices举例:
第一个切片是从0到-window_size。对于下图的例子而言window_size = 3,也就是从0到-3,从下图来看,0是第一行第一列,-1是第一列最后一行,-2是第一列倒数第二行,-3是第一列倒数第三行,因此需要取黄色区域就是0到-3;
第二个切片是从-window_size到-self.shift_size,shift_size也就是m/2向下取整,对于下图例子而言,也就是-3到-1,也就是-3是第一列倒数第三行,-1是第一列最后一行,即紫色区域;
第三个切片是从-shift_size到None(末尾),对于下图例子而言,也就是-1到最后,即绿色区域;
w_slices同理,对应的区域就是下图中横着的大括号区域。
1 2 3 4 5 6 h_slices = (slice (0 , -self.window_size), slice (-self.window_size, -self.shift_size), slice (-self.shift_size, None )) w_slices = (slice (0 , -self.window_size), slice (-self.window_size, -self.shift_size), slice (-self.shift_size, None ))
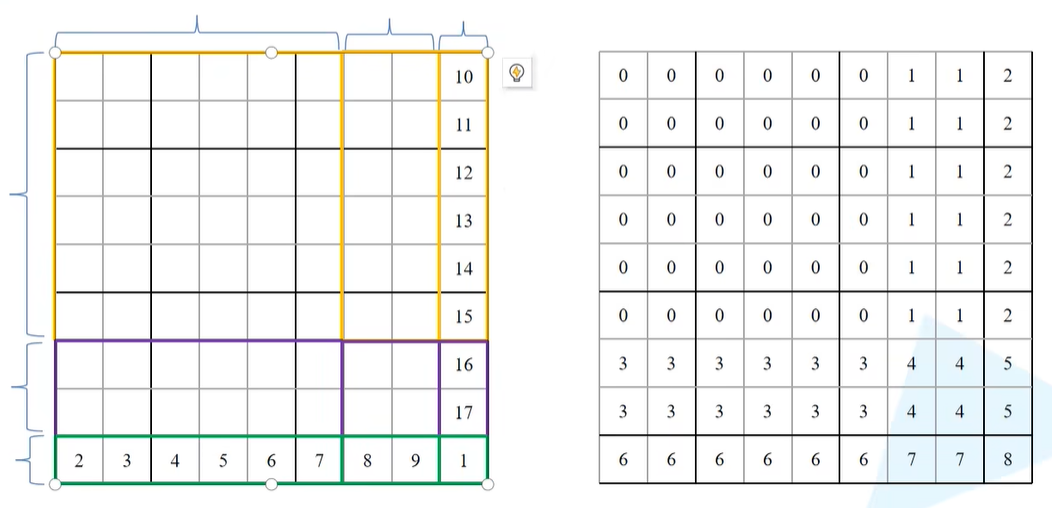
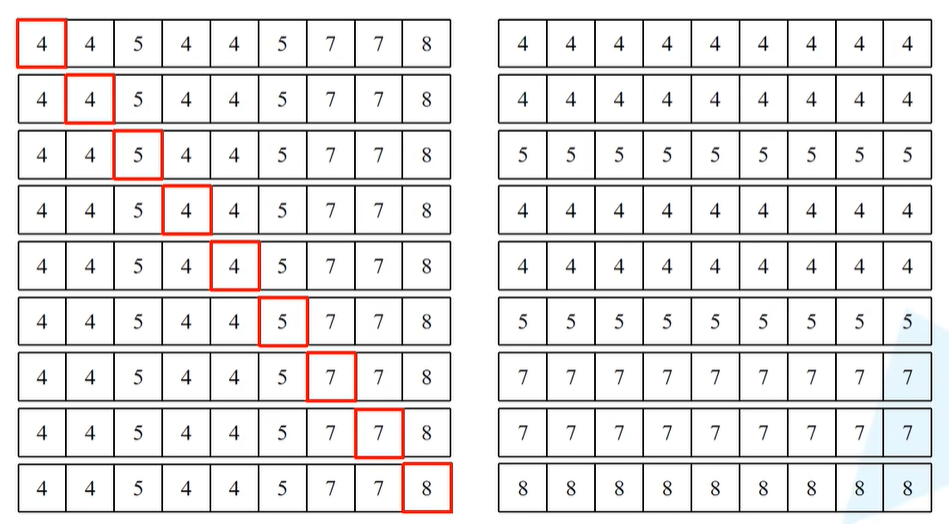
之后进入一个循环,首先将cnt设置为0,然后遍历h_slices,当h为第一个切片的时候(0到-window_size,对应上图竖着的最大的大括号),再遍历w_slices(0到-window_size,对应上图横着的最大的大括号),那么在对应img_mask给定的h和w切片设置为cnt的数值,最开始cnt=0,当进行完一个区域的循环之后,会进行cnt+1。
因此,经过上一段对切片循环的操作,可以给同一块区域的格子赋值为同一个数字,又可以保证不同区域的数值不一样,也就是上图(右)所示(相同的数字对应的是连续的区域 )。
mask_windows = window_partition(img_mask, self.window_size):接下来通过window_partition方法对img_mask划分为一个一个窗口,这里除了传入img_mask之外,还传入了window_size,也就是窗口的尺寸。
通过window_partition函数之后就将根据mask按照所指定的window_size划分成一个个窗口了,也就是下图中,将其划分为一个个窗口的形式。例子中是大小3x3的窗口尺寸,因此这里有9个window。
因为刚刚通过window_partition处理输出的通道排列顺序是[nW, Mh, Mw, 1],因为window_partition所返回的第一个维度是batch*num_windows,又因为这里的batch = 1,所以这里第一个维度就是对应的num_windows,之后对应的是窗口的高度,窗口的宽度,和最后的维度1。
所以接下来进行view处理,将后三个维度展平成一个维度,即[nW, Mh, Mw, 1]->[nW, Mh*Mw],第一个维度自己去推理,第二个维度就是window_size*window_size,即Mh*Mw。
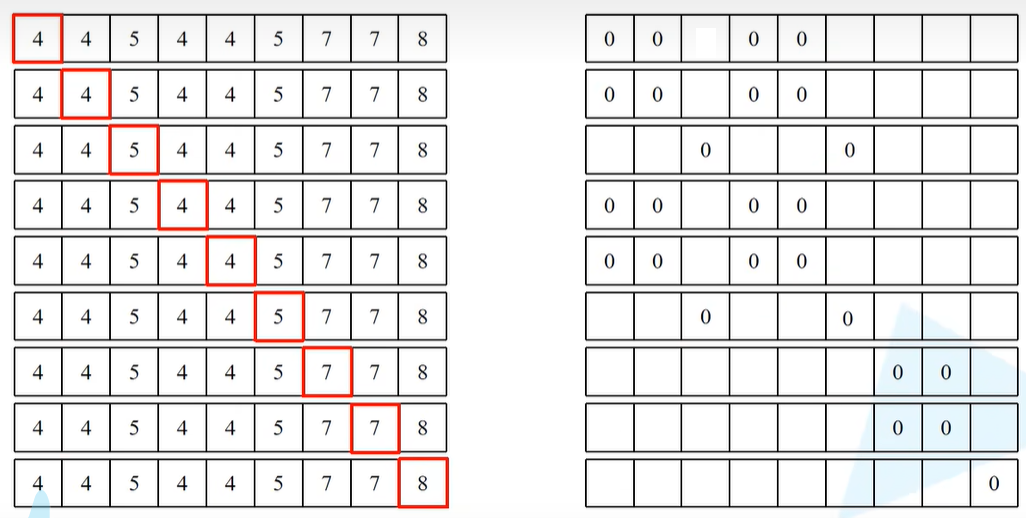
接下来再将mask_windows用unsqueeze方法在维度1上新加一个维度,也就是在nW和Mh*Mw之间新增一个维度。然后减去mask_windows.unsqueeze(2),也就是在Mh*Mw后面这个地方新增一个维度。然后让这两个数据进行相减,得到attn_mask。
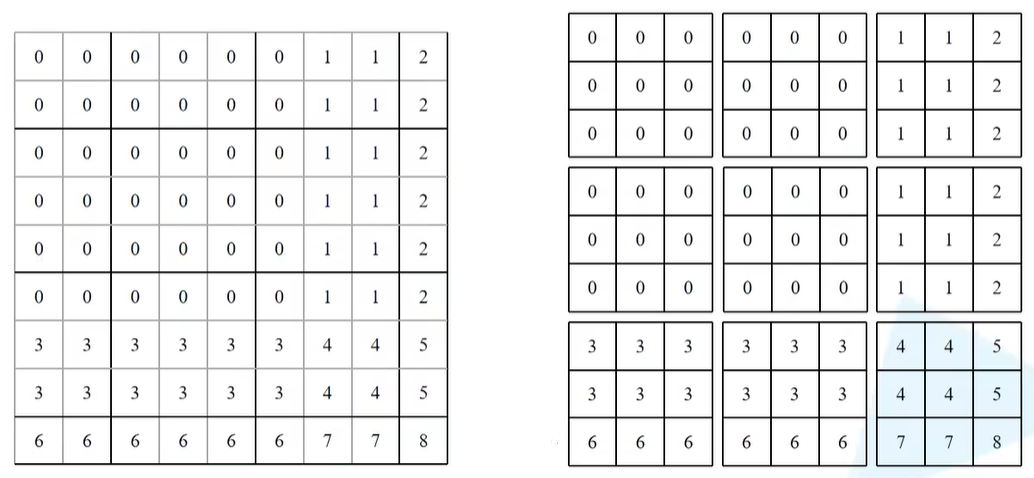
以下图来作解释。在刚刚以及划分了9个窗口,再通过mask_windows = mask_windows.view(-1, self.window_size * self.window_size)之后是将高度宽度全部展平,因此以及将每一个window全部展平了(下图右),按行展平得到1-9个行向量。
对于第一个特征矩阵mask_windows.unsqueeze(1),shape对应的是[nW, 1, Mh*Mw],对于第二个特征矩阵mask_windows.unsqueeze(2),shape对应的是[nW, Mh*Mw, 1],这二者相减就会设计一个广播机制了 。
对于第一个矩阵而言,会将[nW, 1, Mh*Mw]最后这个维度给复制Mh*Mw次,相当于将下图每一个行向量给复制Mh*Mw次(即一个窗口内像素的个数,例子中为9) ,对于第二个矩阵,会在[nW, Mh*Mw, 1]最后这个维度给复制Mh*Mw次。
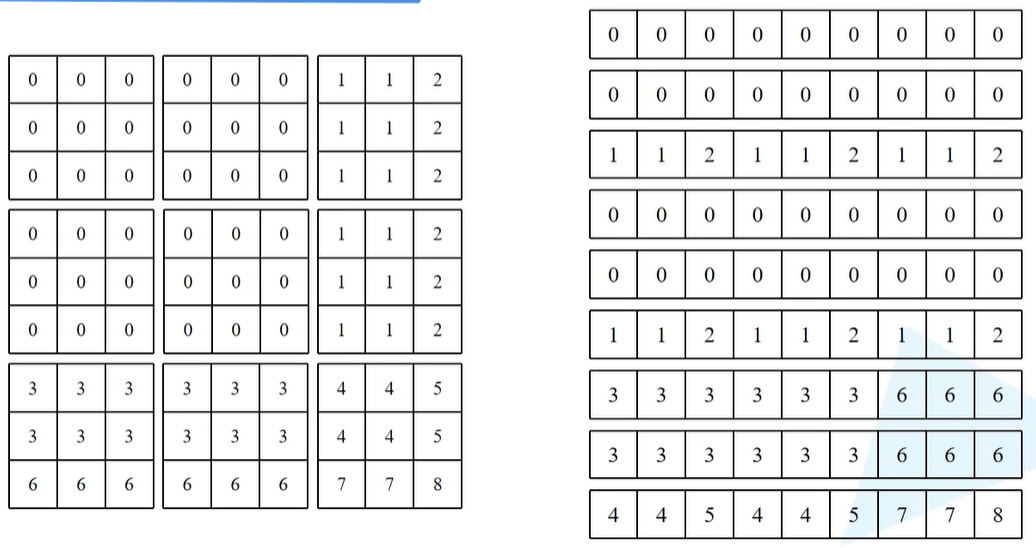
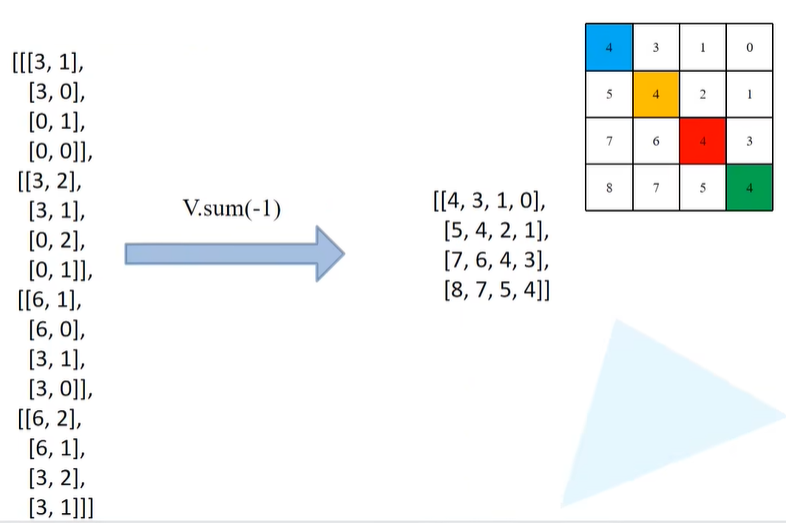
以上图最后一个行向量为例(最复杂),下图为已经将最后一行行向量复制9次了,下图右为对应第二个特征矩阵mask_windows.unsqueeze(2),将下图(左)红色框内复制9次(其实就是将1行9列的tensor按行复制9次,将9行1列的tensor按列复制9次,再相减 )
之后将上图左边的矩阵减去上图右边的矩阵,第一行而言,其实就是对第一个元素进行Attention的求解,相同数字对应的同一块区域,所以做Attention其实就是想和所有数字为4的去做一个Attention。因此在第一行,会让所有数字-4。相减之后将所有数字相减成功后会得到下图的结果。
也就是说,同一个区域的就是用0来表示,不同的区域就是一些非零的数字。
之后会用masked_fill来进一步处理,对于不等于0的区域,会填入-100,对于等于0的区域,直接写入0。比如对于上图第一行,标0的就是和当前mask同区域的元素,非0都会设置为-100。上图(右)每一行对应的就是当前这个窗口当中对应某一个像素的计算Attention时所采用的mask蒙版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def create_mask (self, x, H, W ): Hp = int (np.ceil(H / self.window_size)) * self.window_size Wp = int (np.ceil(W / self.window_size)) * self.window_size img_mask = torch.zeros((1 , Hp, Wp, 1 ), device=x.device) h_slices = (slice (0 , -self.window_size), slice (-self.window_size, -self.shift_size), slice (-self.shift_size, None )) w_slices = (slice (0 , -self.window_size), slice (-self.window_size, -self.shift_size), slice (-self.shift_size, None )) cnt = 0 for h in h_slices: for w in w_slices: img_mask[:, h, w, :] = cnt cnt += 1 mask_windows = window_partition(img_mask, self.window_size) mask_windows = mask_windows.view(-1 , self.window_size * self.window_size) attn_mask = mask_windows.unsqueeze(1 ) - mask_windows.unsqueeze(2 ) attn_mask = attn_mask.masked_fill(attn_mask != 0 , float (-100.0 )).masked_fill(attn_mask == 0 , float (0.0 )) return attn_mask
正向传播函数
传入x和其对应的高和宽。
attn_mask = self.create_mask(x, H, W) :这里首先会根据传入的x,H,W去创建create_mask,create_mask就是在使用SW-MSA时所采用的mask蒙版。
因为对于一个Stage而言,假设看Stage3,会重复堆叠Swin Transformer Block6次,又因为W-MSA和SW-MSA是成对使用的,也就是说在Stage3当中会使用3次W-MSA和3次SW-MSA 。又由于Swin Transformer Block不会改变特征矩阵的高宽,所以当前Stage中所使用的W-MSA和SW-MSA的mask都是一样的,所以对于当前的Stage只需要创建一次即可。
此处attn_mask = self.create_mask(x, H, W)放的位置和作者源码放的不一样,因为如果输入不同尺寸的图像的话,是可以根据传入的x,H,W取重新生成mask蒙版的。但是对于源码而言,有一个input resolution,会根据这个参数一开始就将mask固定了,如果后面像传入一个其他尺寸的图片的话就会报错。因此为了解决多尺寸图片问题,就将该条代码的位置调整到这来了。
通过遍历初始化函数创建的blocks列表,对应的是Swin Transformer Block。
blk.H, blk.W = H, W:那么通过遍历它,首先将当前这个block添加一个高度和宽度的属性,也就是这里的H,W。
之后进行判断,如果当前不是scripting模式并且使用这个checkpoint方法的话,就会使用pytorch官方使用的checkpoint方法(默认不使用)。直接到x = blk(x, attn_mask),将传入的x以及刚刚创建的mask给传入进去,即能得到当前block的输出了。
通过遍历,能够将输入传递给每一个Swin Transformer Block得到对应的输出。
接着再判断downsample是否为None,如果不为None的话,就进行下采样操作,也就是Patch merging层(Stage4为None)
通过下采样之后特征矩阵的高度和宽度就是下采样的2倍,所以需要重新计算H和W,H, W = (H + 1) // 2, (W + 1) // 2(这里是为了防止H或者W如果是奇数的话,是要进行padding的。所以如果是奇数的话,进行+1操作再除以2就刚好等于新的H,W ,如果是偶数的话,+1之后再除以2向下取整还是原来的一半)
1 2 3 4 5 6 7 8 9 10 11 12 13 def forward (self, x, H, W ): attn_mask = self.create_mask(x, H, W) for blk in self.blocks: blk.H, blk.W = H, W if not torch.jit.is_scripting() and self.use_checkpoint: x = checkpoint.checkpoint(blk, x, attn_mask) else : x = blk(x, attn_mask) if self.downsample is not None : x = self.downsample(x, H, W) H, W = (H + 1 ) // 2 , (W + 1 ) // 2 return x, H, W
window_partition
将feature map或者说时刚刚的img_mask按照window_size划分为一个个没有重叠的window。
首先获取传入进来x的shape,对应的维度是(B, H, W, C)
通过view方法将(B, H, W, C)变为[B, H//Mh, Mh, W//Mw, Mw, C] ,也就是batch,高度除上窗口高度,窗口高度,宽度除以窗口宽度,窗口宽度,channel。
接下来再通过permute方法调换2和3这两个维度的数据,因此 [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]。因为通过permute之后数据不再连续,所以需要调用contiguous将数据再变为内存连续的数据。之后再通过view方法(-1, window_size, window_size, C),第一个维度让其自动推理,因此[B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
发现H//Mh乘上W//Mw正好等于window的个数,因此通过view之后,就将前三个维度划分在一起了,即变成了B*num_windows,之后的M,M,C分别对应的是窗口的高度、窗口的高度、channel,精确的写法为Mh和Mw
根据如上处理后,得到的就是指定的window_size划分为一个个窗口之后的数据,并且num_windows和batch是放在一起的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def window_partition (x, window_size: int ): """ 将feature map按照window_size划分成一个个没有重叠的window Args: x: (B, H, W, C) window_size (int): window size(M) Returns: windows: (num_windows*B, window_size, window_size, C) """ B, H, W, C = x.shape x = x.view(B, H // window_size, window_size, W // window_size, window_size, C) windows = x.permute(0 , 1 , 3 , 2 , 4 , 5 ).contiguous().view(-1 , window_size, window_size, C) return windows
window_reverse
这里将一个个窗口再还原为一个feature map。
传入的参数有windows,window_size,H,W。H和W对应的是分割之前feature map的H和W。
首先计算batch维度,在window_partition输出中,第一个维度将batch和num_windows放在一起了,也就是windows: (num_windows*B, window_size, window_size, C),所以如果要求B的话,需要使用windows.shape[0](num_windows*B)除以windows的个数(num_windows),那么$num_windows = H/window_size*W/window_size)$。
再通过view方法调整通道排列顺序:view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
再通过permute方法将2和3两个维度进行调换,即[B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C],同样需要通过contiguous方法将它变为内存连续的形式,在进行view,即[B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]。即与window_partition输入的shape是一样的,因此这两个函数是一个正向操作和一个反向操作的关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def window_reverse (windows, window_size: int , H: int , W: int ): """ 将一个个window还原成一个feature map Args: windows: (num_windows*B, window_size, window_size, C) window_size (int): Window size(M) H (int): Height of image W (int): Width of image Returns: x: (B, H, W, C) """ B = int (windows.shape[0 ] / (H * W / window_size / window_size)) x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1 ) x = x.permute(0 , 1 , 3 , 2 , 4 , 5 ).contiguous().view(B, H, W, -1 ) return x
构建每一个swin transformer block方法。
初始化函数
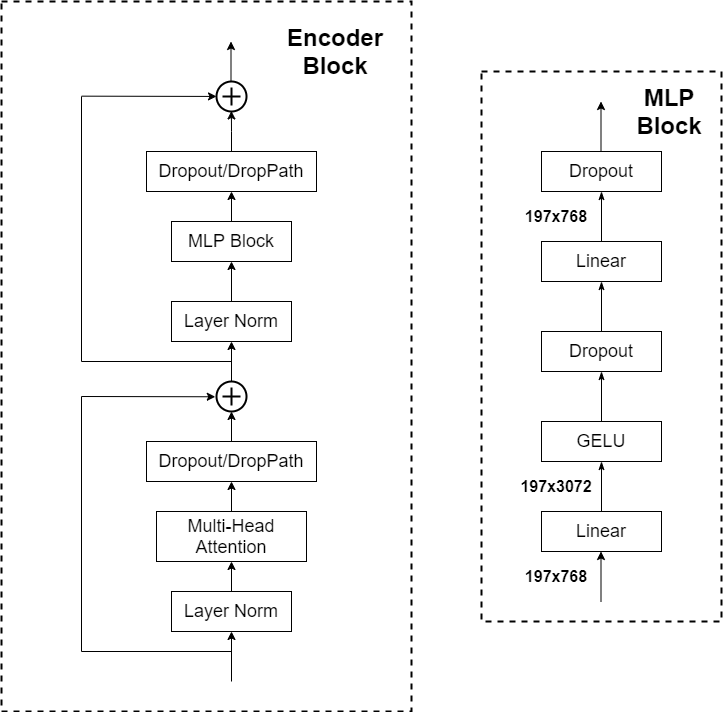
WindowAttention也就是对应的W-MSA或者SW-MSA。对于block而言,和下图的 Encoder Block是一样的,唯一不同在于将Muti-Head Attention换成了W-MSA或者SW-MSA 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class SwinTransformerBlock (nn.Module): r""" Swin Transformer Block. Args: dim (int): Number of input channels. num_heads (int): Number of attention heads. window_size (int): Window size. shift_size (int): Shift size for SW-MSA. mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True drop (float, optional): Dropout rate. Default: 0.0 attn_drop (float, optional): Attention dropout rate. Default: 0.0 drop_path (float, optional): Stochastic depth rate. Default: 0.0 act_layer (nn.Module, optional): Activation layer. Default: nn.GELU norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """ def __init__ (self, dim, num_heads, window_size=7 , shift_size=0 , mlp_ratio=4. , qkv_bias=True , drop=0. , attn_drop=0. , drop_path=0. , act_layer=nn.GELU, norm_layer=nn.LayerNorm ): super ().__init__() self.dim = dim self.num_heads = num_heads self.window_size = window_size self.shift_size = shift_size self.mlp_ratio = mlp_ratio assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size" self.norm1 = norm_layer(dim) self.attn = WindowAttention( dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop) self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int (dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
正向传播函数
正向传播过程中有传入x和attn_mask,首先取到当前输入的feature map的高宽,因为传入的x的shape是B、L、C,L对应的是H*W,因此有记录下H和W的值,也就是BasicLayer正向传播过程中的blk.H, blk.W = H, W。
接下来将x赋值给shortcut,之后进行self.norm1(x),对应上图中的第一个LayerNorm。
再对x进行view处理,即[B, L, C]->[B, H, W, C]
之后对传入的Hp和和Wp进行判断,对高度方向的下侧和宽度方向的右侧去判定是否要及逆行padding操作,因此先将pad_l = pad_t = 0,之后进行计算padding的数量。
_, Hp, Wp, _ = x.shape获取在经过padding之后新的Hp和Wp。
对shift_size进行判断,如果大于0,则进行SW-MSA,如果等于0,则进行W-MSA。
SW-MSA也就是需要将划分窗口之后的矩阵进行滑动窗口之后移动。
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))需要将最上侧移到最下侧,最左侧移到最右侧。因此此处传入x,将dimension设置为1和2(也就是H,W),从上往下移即-self.shift_size,从左往右移即-self.shift_size(如果是正的,就是从下往上和从右往左)。
移动之后通过window_partition发给发将shifted划分为一个个窗口,划分之后得到的通道排列顺序为[nW*B, Mh, Mw, C],再通过view方法,变为[nW*B, Mh*Mw, C]。
之后将W-MSA或者SW-MSA输入到sttn方法当中(Attention)进行正向传播,则得到输出Attention Window。
进行view处理,变回[nW*B, Mh, Mw, C],再通过window_reverse方法将一个个window拼回一个feature map。得到的通道为[B, H', W', C]
if self.shift_size > 0如果当前block使用了SW-MSA的话,需要将计算号的数据给还原回去,所以同样通过roll方法,再高度和宽度分别以shift_size行和shift_size列(因为是还原,将下侧移到上侧,将右侧移到左侧,所以为正数)。
if pad_r > 0 or pad_b > 0:如果有进行padding的话,也需要将pad的数给移除掉。所以只取这个feature map的前H行和前W列,再通过contiguous方法让它百年城内存中连续的一个数据来。
再通过view方法将通道变为[B, H * W, C](B,L,C)。
接下来将x通过drop_path和shortcut进行相加得到x,也就是对应上图block第一个shortcut相加。
再将x通过norm2和drop_path再将x进行相加得到最终的输出(这一步相当于上图block的上半部分全部做完了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 def forward (self, x, attn_mask ): H, W = self.H, self.W B, L, C = x.shape assert L == H * W, "input feature has wrong size" shortcut = x x = self.norm1(x) x = x.view(B, H, W, C) pad_l = pad_t = 0 pad_r = (self.window_size - W % self.window_size) % self.window_size pad_b = (self.window_size - H % self.window_size) % self.window_size x = F.pad(x, (0 , 0 , pad_l, pad_r, pad_t, pad_b)) _, Hp, Wp, _ = x.shape if self.shift_size > 0 : shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1 , 2 )) else : shifted_x = x attn_mask = None x_windows = window_partition(shifted_x, self.window_size) x_windows = x_windows.view(-1 , self.window_size * self.window_size, C) attn_windows = self.attn(x_windows, mask=attn_mask) attn_windows = attn_windows.view(-1 , self.window_size, self.window_size, C) shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) if self.shift_size > 0 : x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1 , 2 )) else : x = shifted_x if pad_r > 0 or pad_b > 0 : x = x[:, :H, :W, :].contiguous() x = x.view(B, H * W, C) x = shortcut + self.drop_path(x) x = x + self.drop_path(self.mlp(self.norm2(x))) return x
Mlp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Mlp (nn.Module): """ MLP as used in Vision Transformer, MLP-Mixer and related networks """ def __init__ (self, in_features, hidden_features=None , out_features=None , act_layer=nn.GELU, drop=0. ): super ().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.drop1 = nn.Dropout(drop) self.fc2 = nn.Linear(hidden_features, out_features) self.drop2 = nn.Dropout(drop) def forward (self, x ): x = self.fc1(x) x = self.act(x) x = self.drop1(x) x = self.fc2(x) x = self.drop2(x) return x
WindowAttention
初始化函数
实现了W-MSA和SW-MSA的部分功能
self.scale = head_dim ** -0.5对应$1/\sqrt d$
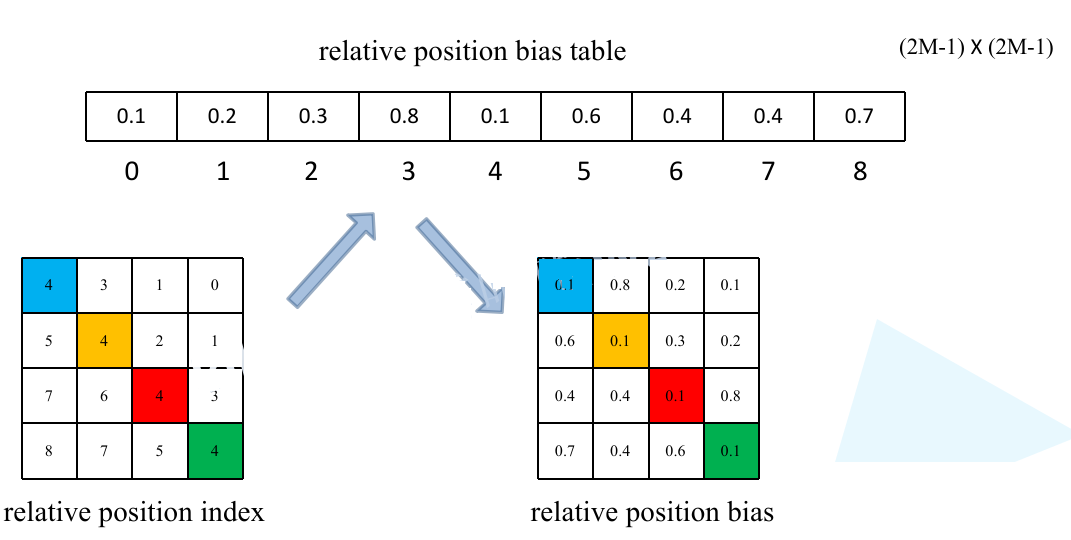
创建relative_position_bias_table,直接通过nn.Parameter来创建这个参数,其长度为(2M-1)X(2M-1),所以使用一个零矩阵来初始化relative_position_bias_table,因为长度很多,所以采用num_heads多头机制。也就是说针对每一个所采用的relative_position_bias_table都是不一样的
下面几行代码就是生成relative_position_index
1 2 3 4 5 6 7 8 9 10 11 12 coords_h = torch.arange(self.window_size[0 ]) coords_w = torch.arange(self.window_size[1 ]) coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij" )) coords_flatten = torch.flatten(coords, 1 ) relative_coords = coords_flatten[:, :, None ] - coords_flatten[:, None , :] relative_coords = relative_coords.permute(1 , 2 , 0 ).contiguous() relative_coords[:, :, 0 ] += self.window_size[0 ] - 1 relative_coords[:, :, 1 ] += self.window_size[1 ] - 1 relative_coords[:, :, 0 ] *= 2 * self.window_size[1 ] - 1 relative_position_index = relative_coords.sum (-1 )
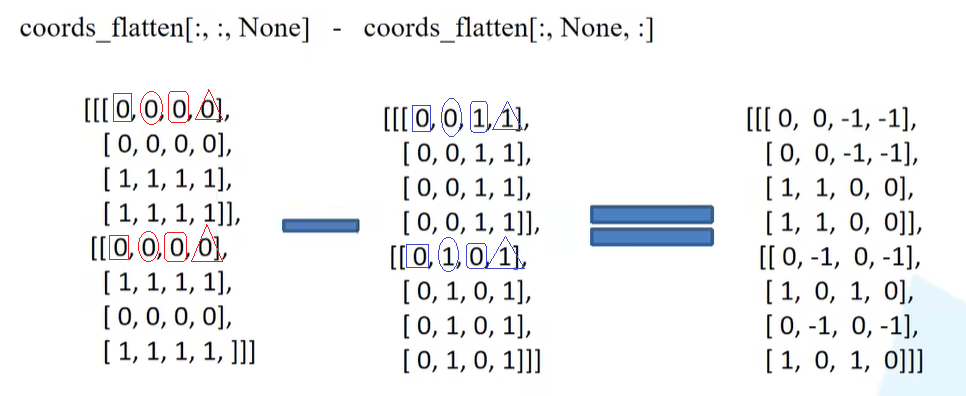
举个栗子,首先通过torch.arange方法传入window_size生成coords_h和coords_w。假设window_size = 2,则coords_h=[0,1],coords_w=[0,1]。再通过torch.meshgrid方法(生成网格的方法),第一个元素对应高度的范围,第二个元素对应宽度的范围,indexing="ij"也就是创建的这个网格所对应的坐标是以行和列的形式来表示的。meshgrid方法返回的是两个tensor,所以通过stack方法进行拼接之后就变成了[2, Mh, Mw]。
再对第一个维度开始展平,得到[2, Mh*Mw]。得到的形式为下图(最左),第一行像素对应的是feature map上每一个像素对应的行标,第二行圆度对应的是feature map上每一个像素对应的列标,对应的是绝对位置索引 。
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]对第一个矩阵在最后一个新加一个维度,对第二个矩阵在中间新增一个维度,二者相减得到[2, Mh*Mw, Mh*Mw],即下图(中和右)。
为了使二者之间能够进行相减,因此需要用到广播机制,也就是前者的1维度要复制4次()每一个行标复制4次),后者的1维度也要复制4次(每一个列标复制4次),箭头下方对应的就是分别复制4次之后的结果。
相减的过程怎么理解:想要构建相对位置索引的矩阵,假设以第一个像素为例的话,需要用它所对应的绝对索引去减去feature map每一个像素的绝对位置索引。
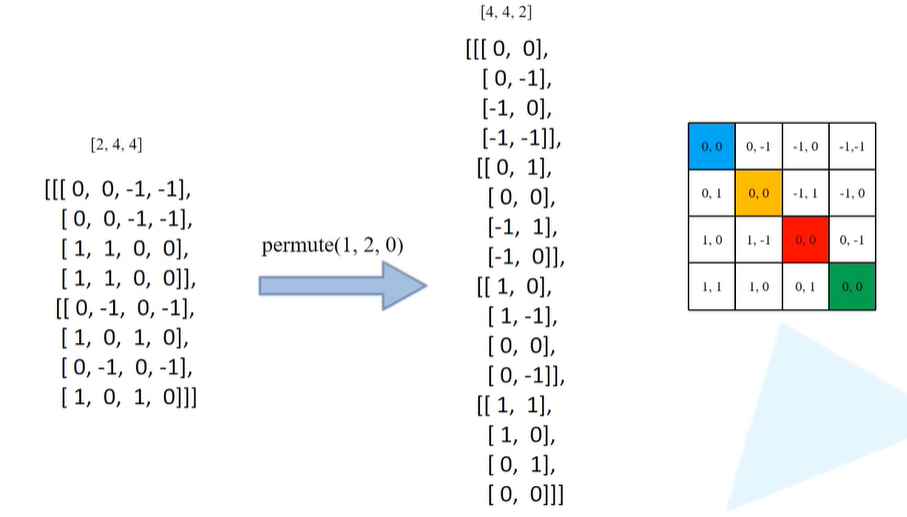
那么得到上面相减之后的矩阵之后,relative_coords = relative_coords.permute(1, 2, 0).contiguous()中进行permute处理,将0维度挪到最后,即[2, Mh*Mw, Mh*Mw]->[Mh*Mw, Mh*Mw, 2]。又通过contiguous变为内存连续的形式。
接下来就是将二元索引变为医院索引的过程。将行标加上window_size[0] - 1,列标加上window_size[1] - 1,行标乘上2倍的window_size[1]之后 - 1,之后在最后一个维度上求和,对应的是[Mh*Mw, Mh*Mw, 2]中2这个维度,也就是行标与列标相加
1 2 3 4 relative_coords[:, :, 0 ] += self.window_size[0 ] - 1 relative_coords[:, :, 1 ] += self.window_size[1 ] - 1 relative_coords[:, :, 0 ] *= 2 * self.window_size[1 ] - 1 relative_position_index = relative_coords.sum (-1 )
上面代码对应的就是将下图(左)矩阵首先通过permute来变成下图(中)的形式。以列表中index = 0的列表为例,指的就是下图(右)蓝色像素为参考点时所求得的相对位置索引,index = 1的列表对应的是以橙色像素为参考点时所求得的相对位置索引,依次为红色、绿色。
在行标加上M-1
列标加上M-1
对行标乘以(2M-1)
再将行标和列标相加,即得到下图(右)的结果,同上篇文举的例子最终结果一样。
relative_position_index = relative_coords.sum(-1)即为上图(右)得到的情况,构建好的相对位置索引。
self.register_buffer("relative_position_index", relative_position_index)通过register_buffer将relative_position_index放进模型的缓存当中。因为relative_position_index的参数是一个固定的值,一旦创建就不需要去修改了,真正需要训练修改的是relative position table。
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)通过Linear创建qkv,和vision transformer是一样的。
self.proj = nn.Linear(dim, dim)对应的是多头输出进行融合的过程
nn.init.trunc_normal_(self.relative_position_bias_table, std=.02):对relative_position_bias_table进行初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class WindowAttention (nn.Module): r""" Window based multi-head self attention (W-MSA) module with relative position bias. It supports both of shifted and non-shifted window. Args: dim (int): Number of input channels. window_size (tuple[int]): The height and width of the window. num_heads (int): Number of attention heads. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0 proj_drop (float, optional): Dropout ratio of output. Default: 0.0 """ def __init__ (self, dim, window_size, num_heads, qkv_bias=True , attn_drop=0. , proj_drop=0. ): super ().__init__() self.dim = dim self.window_size = window_size self.num_heads = num_heads head_dim = dim // num_heads self.scale = head_dim ** -0.5 self.relative_position_bias_table = nn.Parameter( torch.zeros((2 * window_size[0 ] - 1 ) * (2 * window_size[1 ] - 1 ), num_heads)) coords_h = torch.arange(self.window_size[0 ]) coords_w = torch.arange(self.window_size[1 ]) coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij" )) coords_flatten = torch.flatten(coords, 1 ) relative_coords = coords_flatten[:, :, None ] - coords_flatten[:, None , :] relative_coords = relative_coords.permute(1 , 2 , 0 ).contiguous() relative_coords[:, :, 0 ] += self.window_size[0 ] - 1 relative_coords[:, :, 1 ] += self.window_size[1 ] - 1 relative_coords[:, :, 0 ] *= 2 * self.window_size[1 ] - 1 relative_position_index = relative_coords.sum (-1 ) self.register_buffer("relative_position_index" , relative_position_index) self.qkv = nn.Linear(dim, dim * 3 , bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) nn.init.trunc_normal_(self.relative_position_bias_table, std=.02 ) self.softmax = nn.Softmax(dim=-1 )
正向传播函数
有传入x和mask。
首先获取x的shape,B_, N, C = x.shape对应的通道为[batch_size*num_windows, Mh*Mw, total_embed_dim]。
将x通过qkv这个Linear就得到qkv的数据,再进行reshape处理
qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
通过unbind方法分别获得q,k,v的值。
与在vision transformer不一样的是,这里的q先乘上scaleq = q * self.scale,之后再乘以k的转置attn = (q @ k.transpose(-2, -1))。
transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
@: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
1 2 self.relative_position_bias_table[self.relative_position_index.view(-1 )].view( self.window_size[0 ] * self.window_size[1 ], self.window_size[0 ] * self.window_size[1 ], -1 )
通过view函数将relative_position_index全部展平,展平之后就在relative_position_bias_table当中去取对应的参数,即relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
之后通过permute方法去调整一下数据的排列顺序[Mh*Mw,Mh*Mw,nH]->[nH, Mh*Mw, Mh*Mw]
attn = attn + relative_position_bias.unsqueeze(0)再通过Attention加上relative_position_bias,这一步对应的就是公式里加上B这个矩阵的过程。attn的通道排列顺序为[batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw],relative_position_bias的通道排列顺序为[Mh*Mw,Mh*Mw,nH],二者间相差一个Batch,因此这里会通过unsqueeze(0)来给relative_position_bias加上一个batch维度。这样就能通过广播机制进行相加。
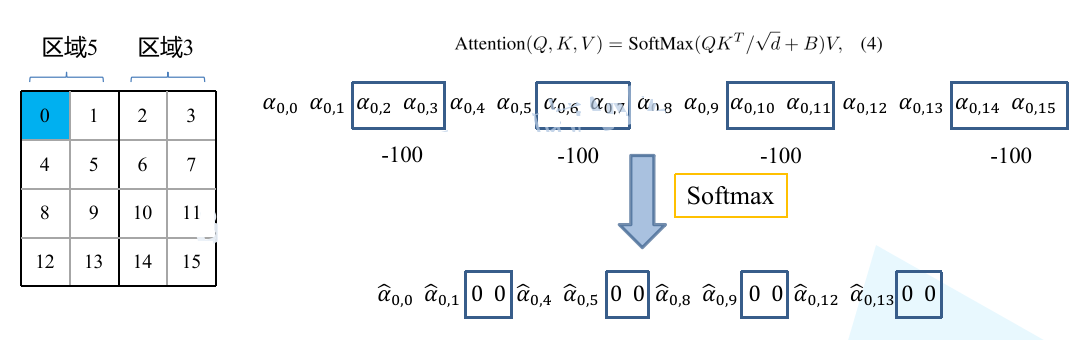
接下来判断mask是否为None,如果为None的话,即直接通过softmax处理;如果不为None的话,首先拿到mask的window个数nW = mask.shape[0]。
接着对attn进行view处理attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw],由于和mask的通道排列顺序不相对,所以给mask先再1处加入新的维度,之后又在加了维度的基础上再0的位置加入新的维度,即mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw],此时可以通过广播机制进行相加。
注意:构建mask时,在一个window内,对于相同区域的元素是用0来表示的,对于不同区域的是用-100表示的,所以当attn和mask相加之后,对于加上0(相同区域)的数值是没有任何影响的,但是对于不同区域的attn数值都加上-100之后就变成一个非常大的负数,接下来再通过softmax处理,对于不同区域的 权重就会全部变为0了。
再通过Dropout层,再将attn乘上V(这里对应的是上图公式里通过softmax处理之后乘上V的操作),接着通过transpose和reshape,即transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head],reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]。
最后通过proj也就是线性层对多个head的输出进行一个融合,融合之后再通过一个Dropout层,就得到最终Attention模块的输出了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def forward (self, x, mask: Optional [torch.Tensor] = None ): """ Args: x: input features with shape of (num_windows*B, Mh*Mw, C) mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None """ B_, N, C = x.shape qkv = self.qkv(x).reshape(B_, N, 3 , self.num_heads, C // self.num_heads).permute(2 , 0 , 3 , 1 , 4 ) q, k, v = qkv.unbind(0 ) q = q * self.scale attn = (q @ k.transpose(-2 , -1 )) relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1 )].view( self.window_size[0 ] * self.window_size[1 ], self.window_size[0 ] * self.window_size[1 ], -1 ) relative_position_bias = relative_position_bias.permute(2 , 0 , 1 ).contiguous() attn = attn + relative_position_bias.unsqueeze(0 ) if mask is not None : nW = mask.shape[0 ] attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1 ).unsqueeze(0 ) attn = attn.view(-1 , self.num_heads, N, N) attn = self.softmax(attn) else : attn = self.softmax(attn) attn = self.attn_drop(attn) x = (attn @ v).transpose(1 , 2 ).reshape(B_, N, C) x = self.proj(x) x = self.proj_drop(x) return x
实例化模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 def swin_tiny_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=7 , embed_dim=96 , depths=(2 , 2 , 6 , 2 ), num_heads=(3 , 6 , 12 , 24 ), num_classes=num_classes, **kwargs) return model def swin_small_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=7 , embed_dim=96 , depths=(2 , 2 , 18 , 2 ), num_heads=(3 , 6 , 12 , 24 ), num_classes=num_classes, **kwargs) return model def swin_base_patch4_window7_224 (num_classes: int = 1000 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=7 , embed_dim=128 , depths=(2 , 2 , 18 , 2 ), num_heads=(4 , 8 , 16 , 32 ), num_classes=num_classes, **kwargs) return model def swin_base_patch4_window12_384 (num_classes: int = 1000 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=12 , embed_dim=128 , depths=(2 , 2 , 18 , 2 ), num_heads=(4 , 8 , 16 , 32 ), num_classes=num_classes, **kwargs) return model def swin_base_patch4_window7_224_in22k (num_classes: int = 21841 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=7 , embed_dim=128 , depths=(2 , 2 , 18 , 2 ), num_heads=(4 , 8 , 16 , 32 ), num_classes=num_classes, **kwargs) return model def swin_base_patch4_window12_384_in22k (num_classes: int = 21841 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=12 , embed_dim=128 , depths=(2 , 2 , 18 , 2 ), num_heads=(4 , 8 , 16 , 32 ), num_classes=num_classes, **kwargs) return model def swin_large_patch4_window7_224_in22k (num_classes: int = 21841 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=7 , embed_dim=192 , depths=(2 , 2 , 18 , 2 ), num_heads=(6 , 12 , 24 , 48 ), num_classes=num_classes, **kwargs) return model def swin_large_patch4_window12_384_in22k (num_classes: int = 21841 , **kwargs ): model = SwinTransformer(in_chans=3 , patch_size=4 , window_size=12 , embed_dim=192 , depths=(2 , 2 , 18 , 2 ), num_heads=(6 , 12 , 24 , 48 ), num_classes=num_classes, **kwargs) return model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 import osimport argparseimport torchimport torch.optim as optimfrom torch.utils.tensorboard import SummaryWriterfrom torchvision import transformsfrom my_dataset import MyDataSetfrom model import swin_tiny_patch4_window7_224 as create_modelfrom utils import read_split_data, train_one_epoch, evaluatedef main (args ): device = torch.device(args.device if torch.cuda.is_available() else "cpu" ) if os.path.exists("./weights" ) is False : os.makedirs("./weights" ) tb_writer = SummaryWriter() train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path) img_size = 224 data_transform = { "train" : transforms.Compose([transforms.RandomResizedCrop(img_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485 , 0.456 , 0.406 ], [0.229 , 0.224 , 0.225 ])]), "val" : transforms.Compose([transforms.Resize(int (img_size * 1.143 )), transforms.CenterCrop(img_size), transforms.ToTensor(), transforms.Normalize([0.485 , 0.456 , 0.406 ], [0.229 , 0.224 , 0.225 ])])} train_dataset = MyDataSet(images_path=train_images_path, images_class=train_images_label, transform=data_transform["train" ]) val_dataset = MyDataSet(images_path=val_images_path, images_class=val_images_label, transform=data_transform["val" ]) batch_size = args.batch_size nw = min ([os.cpu_count(), batch_size if batch_size > 1 else 0 , 8 ]) print ('Using {} dataloader workers every process' .format (nw)) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True , pin_memory=True , num_workers=nw, collate_fn=train_dataset.collate_fn) val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False , pin_memory=True , num_workers=nw, collate_fn=val_dataset.collate_fn) model = create_model(num_classes=args.num_classes).to(device) if args.weights != "" : assert os.path.exists(args.weights), "weights file: '{}' not exist." .format (args.weights) weights_dict = torch.load(args.weights, map_location=device)["model" ] for k in list (weights_dict.keys()): if "head" in k: del weights_dict[k] print (model.load_state_dict(weights_dict, strict=False )) if args.freeze_layers: for name, para in model.named_parameters(): if "head" not in name: para.requires_grad_(False ) else : print ("training {}" .format (name)) pg = [p for p in model.parameters() if p.requires_grad] optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2 ) for epoch in range (args.epochs): train_loss, train_acc = train_one_epoch(model=model, optimizer=optimizer, data_loader=train_loader, device=device, epoch=epoch) val_loss, val_acc = evaluate(model=model, data_loader=val_loader, device=device, epoch=epoch) tags = ["train_loss" , "train_acc" , "val_loss" , "val_acc" , "learning_rate" ] tb_writer.add_scalar(tags[0 ], train_loss, epoch) tb_writer.add_scalar(tags[1 ], train_acc, epoch) tb_writer.add_scalar(tags[2 ], val_loss, epoch) tb_writer.add_scalar(tags[3 ], val_acc, epoch) tb_writer.add_scalar(tags[4 ], optimizer.param_groups[0 ]["lr" ], epoch) torch.save(model.state_dict(), "./weights/model-{}.pth" .format (epoch)) if __name__ == '__main__' : parser = argparse.ArgumentParser() parser.add_argument('--num_classes' , type =int , default=5 ) parser.add_argument('--epochs' , type =int , default=10 ) parser.add_argument('--batch-size' , type =int , default=4 ) parser.add_argument('--lr' , type =float , default=0.0001 ) parser.add_argument('--data-path' , type =str , default="D:/python_test/deep-learning-for-image-processing/data_set/flower_data/flower_photos" ) parser.add_argument('--weights' , type =str , default='./swin_tiny_patch4_window7_224.pth' , help ='initial weights path' ) parser.add_argument('--freeze-layers' , type =bool , default=False ) parser.add_argument('--device' , default='cuda:0' , help ='device id (i.e. 0 or 0,1 or cpu)' ) opt = parser.parse_args() main(opt)
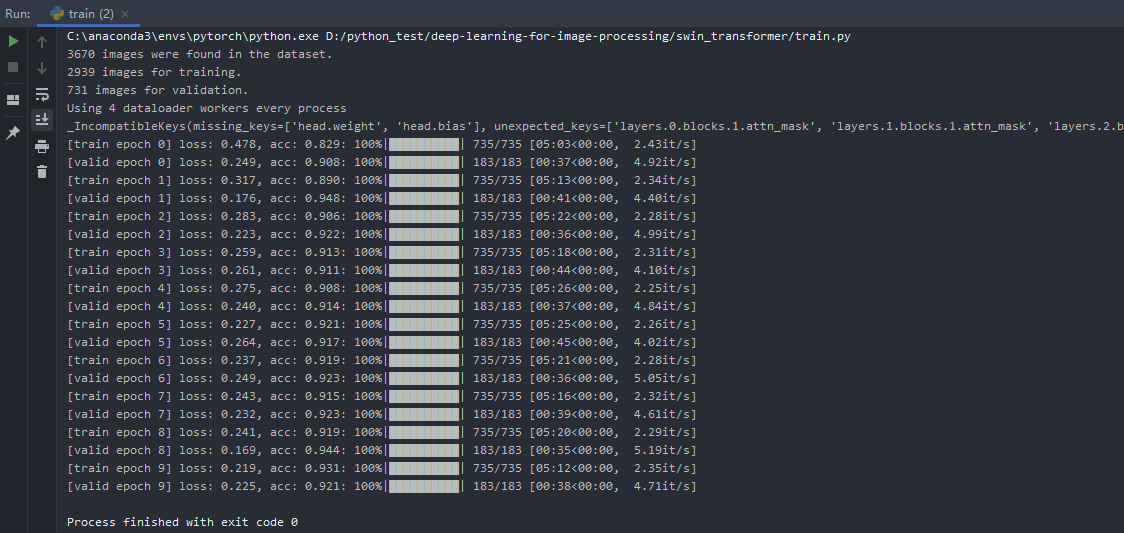
训练结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import osimport jsonimport torchfrom PIL import Imagefrom torchvision import transformsimport matplotlib.pyplot as pltfrom model import swin_tiny_patch4_window7_224 as create_modeldef main (): device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" ) img_size = 224 data_transform = transforms.Compose( [transforms.Resize(int (img_size * 1.14 )), transforms.CenterCrop(img_size), transforms.ToTensor(), transforms.Normalize([0.485 , 0.456 , 0.406 ], [0.229 , 0.224 , 0.225 ])]) img_path = "tulip.jpg" assert os.path.exists(img_path), "file: '{}' dose not exist." .format (img_path) img = Image.open (img_path) plt.imshow(img) img = data_transform(img) img = torch.unsqueeze(img, dim=0 ) json_path = './class_indices.json' assert os.path.exists(json_path), "file: '{}' dose not exist." .format (json_path) with open (json_path, "r" ) as f: class_indict = json.load(f) model = create_model(num_classes=5 ).to(device) model_weight_path = "./weights/model-9.pth" model.load_state_dict(torch.load(model_weight_path, map_location=device)) model.eval () with torch.no_grad(): output = torch.squeeze(model(img.to(device))).cpu() predict = torch.softmax(output, dim=0 ) predict_cla = torch.argmax(predict).numpy() print_res = "class: {} prob: {:.3}" .format (class_indict[str (predict_cla)], predict[predict_cla].numpy()) plt.title(print_res) for i in range (len (predict)): print ("class: {:10} prob: {:.3}" .format (class_indict[str (i)], predict[i].numpy())) plt.show() if __name__ == '__main__' : main()
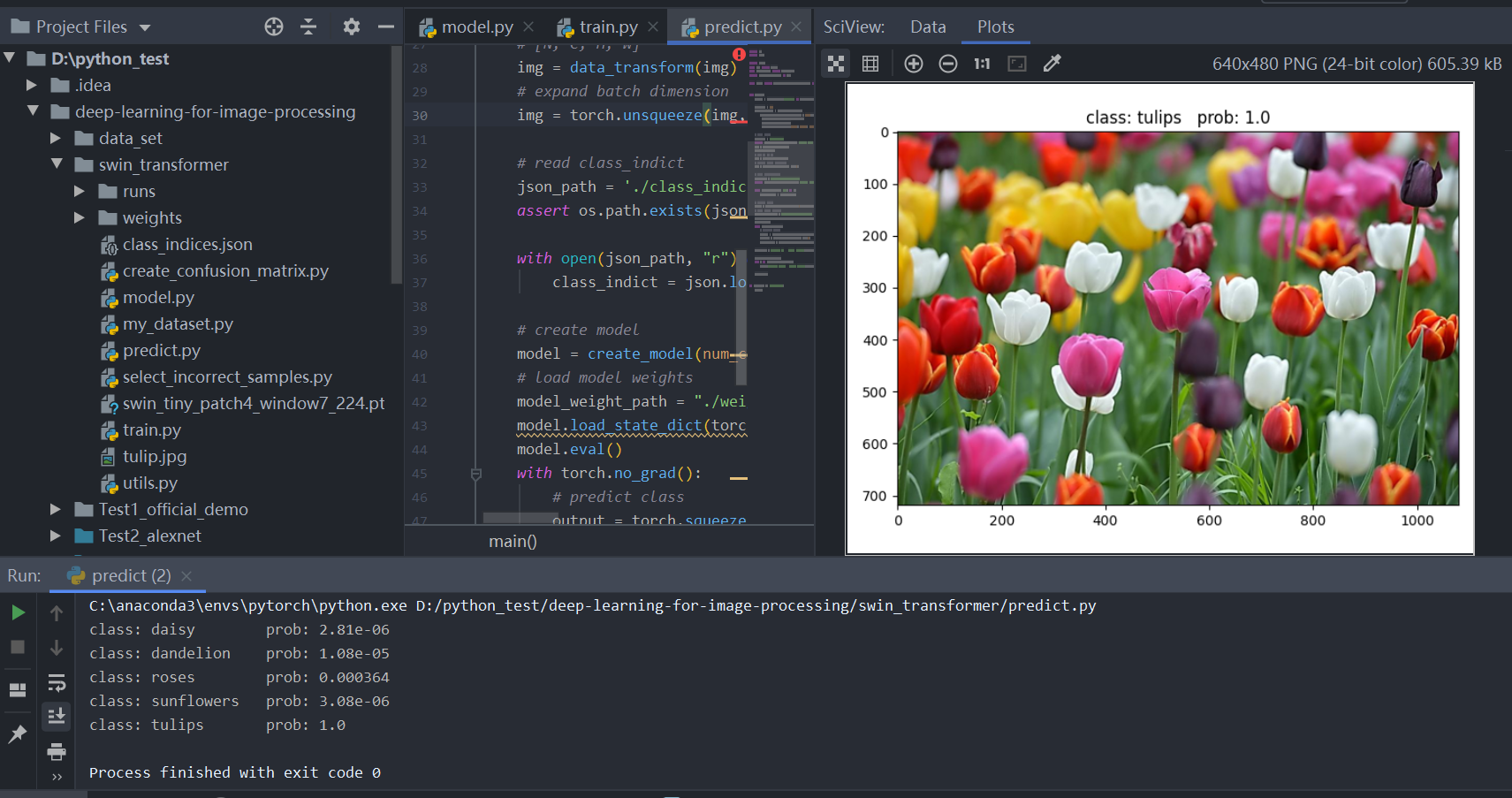
预测结果