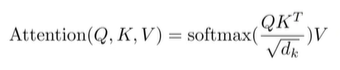""" original code from rwightman: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py """ from functools import partial from collections import OrderedDict
defdrop_path(x, drop_prob: float = 0., training: bool = False): """ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument. """ if drop_prob == 0.ornot training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output
classDropPath(nn.Module): """ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). """ def__init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob
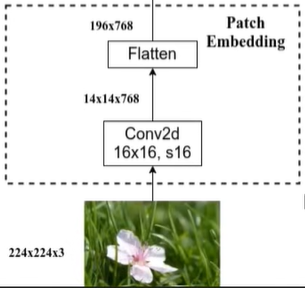
defforward(self, x): # batch,3,224,224 B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
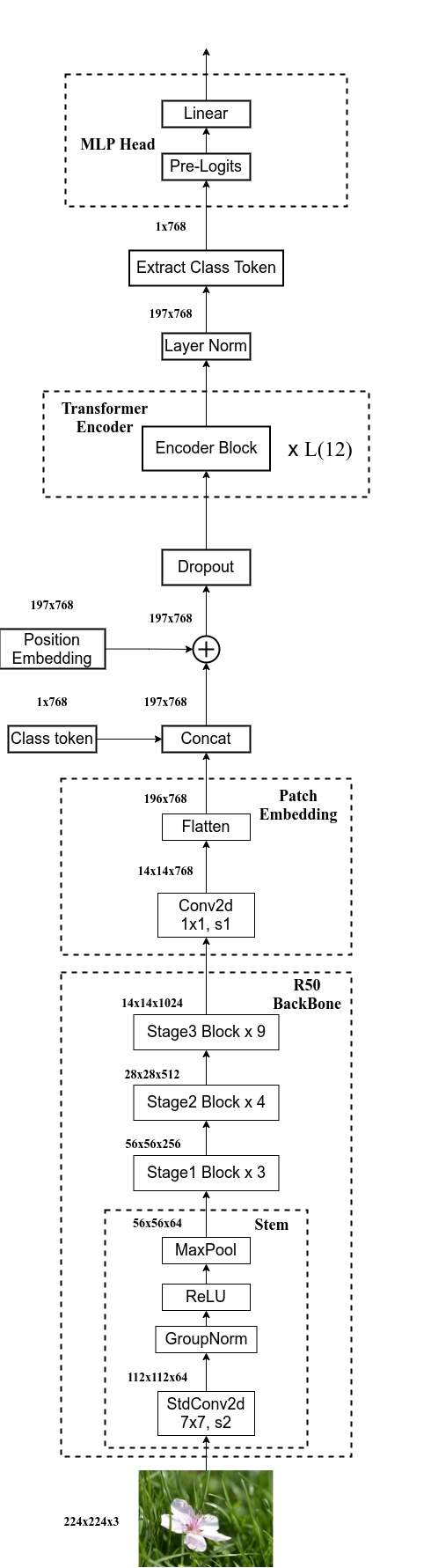
classVisionTransformer(nn.Module): def__init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True, qk_scale=None, representation_size=None, distilled=False, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None, act_layer=None): """ Args: img_size (int, tuple): input image size patch_size (int, tuple): patch size in_c (int): number of input channels num_classes (int): number of classes for classification head embed_dim (int): embedding dimension depth (int): depth of transformer num_heads (int): number of attention heads mlp_ratio (int): ratio of mlp hidden dim to embedding dim qkv_bias (bool): enable bias for qkv if True qk_scale (float): override default qk scale of head_dim ** -0.5 if set representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set distilled (bool): model includes a distillation token and head as in DeiT models drop_ratio (float): dropout rate attn_drop_ratio (float): attention dropout rate drop_path_ratio (float): stochastic depth rate embed_layer (nn.Module): patch embedding layer norm_layer: (nn.Module): normalization layer """ super(VisionTransformer, self).__init__() self.num_classes = num_classes self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models self.num_tokens = 2if distilled else1 norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) act_layer = act_layer or nn.GELU
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)]:根据传入的drop_path_ratio构建一个等差序列,范围是从0到drop_path_ratio,这个序列当中总共由depth个元素。也就是说,在Transformer Encoder当中,每一个Encoder Block所采用的drop_path方法所使用的drop_path_ratio是递增的。此刻默认为0;
1 2 3 4
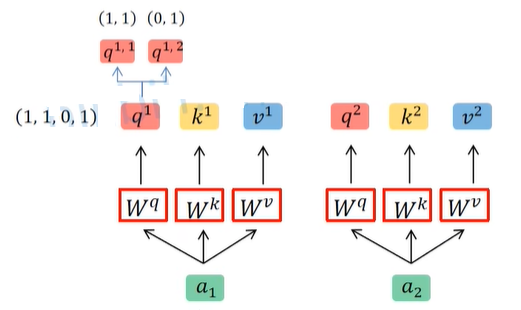
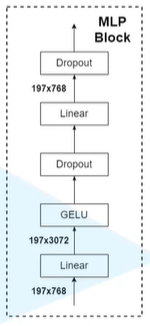
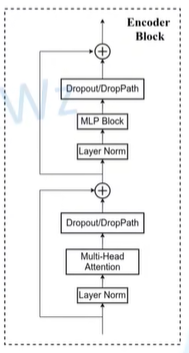
self.blocks = nn.Sequential(*[ Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer) for i inrange(depth) ])
x = self.pos_drop(x + self.pos_embed) x = self.blocks(x) x = self.norm(x) if self.dist_token isNone: return self.pre_logits(x[:, 0]) else: return x[:, 0], x[:, 1]
defforward(self, x): x = self.forward_features(x) if self.head_dist isnotNone: x, x_dist = self.head(x[0]), self.head_dist(x[1]) if self.training andnot torch.jit.is_scripting(): # during inference, return the average of both classifier predictions return x, x_dist else: return (x + x_dist) / 2 else: x = self.head(x) return x
defvit_base_patch16_224(num_classes: int = 1000): """ ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=768, depth=12, num_heads=12, representation_size=None, num_classes=num_classes) return model
defvit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=768, depth=12, num_heads=12, representation_size=768if has_logits elseNone, num_classes=num_classes) return model
defvit_base_patch32_224(num_classes: int = 1000): """ ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=768, depth=12, num_heads=12, representation_size=None, num_classes=num_classes) return model
defvit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=768, depth=12, num_heads=12, representation_size=768if has_logits elseNone, num_classes=num_classes) return model
defvit_large_patch16_224(num_classes: int = 1000): """ ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8 """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=1024, depth=24, num_heads=16, representation_size=None, num_classes=num_classes) return model
defvit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=1024, depth=24, num_heads=16, representation_size=1024if has_logits elseNone, num_classes=num_classes) return model
defvit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=1024, depth=24, num_heads=16, representation_size=1024if has_logits elseNone, num_classes=num_classes) return model
defvit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. NOTE: converted weights not currently available, too large for github release hosting. """ model = VisionTransformer(img_size=224, patch_size=14, embed_dim=1280, depth=32, num_heads=16, representation_size=1280if has_logits elseNone, num_classes=num_classes) return model
import torch import torch.optim as optim import torch.optim.lr_scheduler as lr_scheduler from torch.utils.tensorboard import SummaryWriter from torchvision import transforms
from my_dataset import MyDataSet from vit_model import vit_base_patch16_224_in21k as create_model from utils import read_split_data, train_one_epoch, evaluate
defmain(args): device = torch.device(args.device if torch.cuda.is_available() else"cpu")
if os.path.exists("./weights") isFalse: os.makedirs("./weights")
model = create_model(num_classes=args.num_classes, has_logits=False).to(device)
if args.weights != "": assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights) weights_dict = torch.load(args.weights, map_location=device) # 删除不需要的权重 del_keys = ['head.weight', 'head.bias'] if model.has_logits \ else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias'] for k in del_keys: del weights_dict[k] print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers: for name, para in model.named_parameters(): # 除head, pre_logits外,其他权重全部冻结 if"head"notin name and"pre_logits"notin name: para.requires_grad_(False) else: print("training {}".format(name))
import os import sys import json import pickle import random
import torch from tqdm import tqdm
import matplotlib.pyplot as plt
defread_split_data(root: str, val_rate: float = 0.2): random.seed(0) # 保证随机结果可复现 assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别 flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))] # 排序,保证各平台顺序一致 flower_class.sort() # 生成类别名称以及对应的数字索引 class_indices = dict((k, v) for v, k inenumerate(flower_class)) json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4) withopen('class_indices.json', 'w') as json_file: json_file.write(json_str)
for img_path in images: if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集 val_images_path.append(img_path) val_images_label.append(image_class) else: # 否则存入训练集 train_images_path.append(img_path) train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num))) print("{} images for training.".format(len(train_images_path))) print("{} images for validation.".format(len(val_images_path))) assertlen(train_images_path) > 0, "number of training images must greater than 0." assertlen(val_images_path) > 0, "number of validation images must greater than 0."
plot_image = False if plot_image: # 绘制每种类别个数柱状图 plt.bar(range(len(flower_class)), every_class_num, align='center') # 将横坐标0,1,2,3,4替换为相应的类别名称 plt.xticks(range(len(flower_class)), flower_class) # 在柱状图上添加数值标签 for i, v inenumerate(every_class_num): plt.text(x=i, y=v + 5, s=str(v), ha='center') # 设置x坐标 plt.xlabel('image class') # 设置y坐标 plt.ylabel('number of images') # 设置柱状图的标题 plt.title('flower class distribution') plt.show()