深度学习模型之CNN(二十)使用Pytorch搭建EfficientNetV2网络
工程目录
1 | ├── Test11_efficientnetV2 |
model.py
1 | from collections import OrderedDict |
DropPath类
直接调用drop_path函数,原理和上节课一致,如下文所述。
EfficientNet网络中的Dropout与前期所有网络结构的Dropout不全一样,例如原始的Dropout参数丢弃比例为0.2,但EfficientNet中给出Dropout = 0.2的参数表示该网络在0~0.2的丢弃比例下逐渐失活。引用论文为:Deep Networks with Stochastic Depth
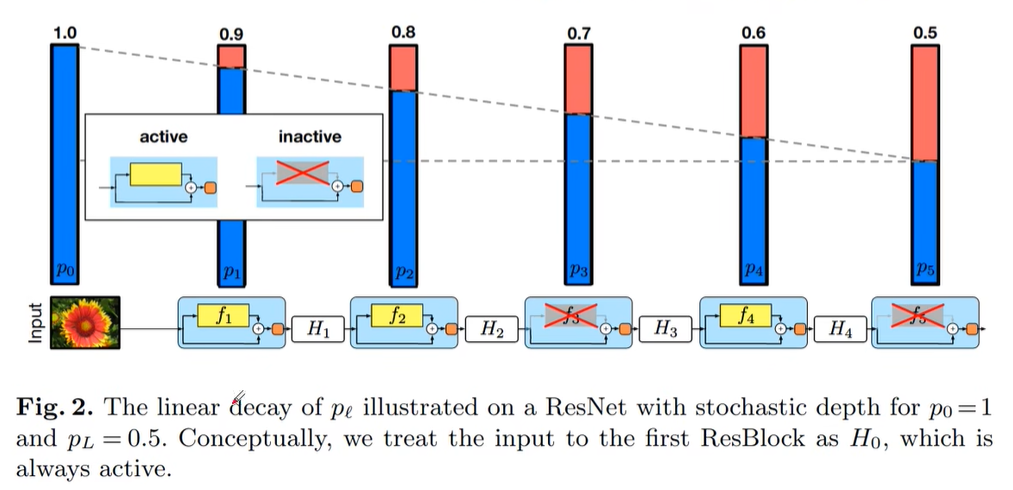
下图可以理解为正向传播过程中将输入的特征矩阵经历了一个又一个block,每一个block都可以认为是一个残差结构。例如主分支通过$f$函数进行输出,shortcut直接从输入引到输出,在此过程中,会以一定的概率来对主分支进行丢弃(直接放弃整个主分支,相当于直接将上一层的输出引入到下一层的输入,相当于没有这一层)。即Stochastic Depth(随即深度,指的是网络的depth,因为会随机丢弃任意一层block)。
下图中表示存活概率从1.0至0.5,一个渐变的过程。但在EfficientNetV2中采用drop_prob是0~0.2的丢弃比例(提升训练速度,小幅提升准确率)。
注意:这里的dropout层仅指Fused-MBConv模块以及MBConv模块中的dropout层,不包括最后全连接前的dropout层
1 | def drop_path(x, drop_prob: float = 0., training: bool = False): |
ConvBNAct类
1 | class ConvBNAct(nn.Module): |
SqueezeExcite类
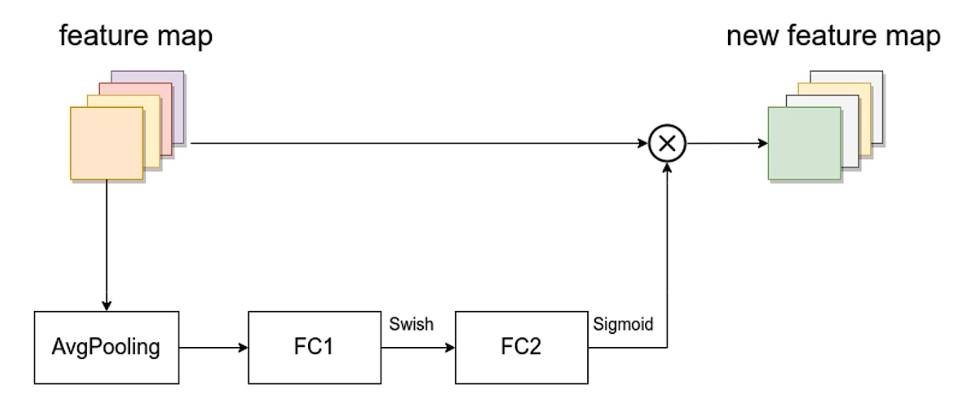
SE模块如下图所示,由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
1 | class SqueezeExcite(nn.Module): |
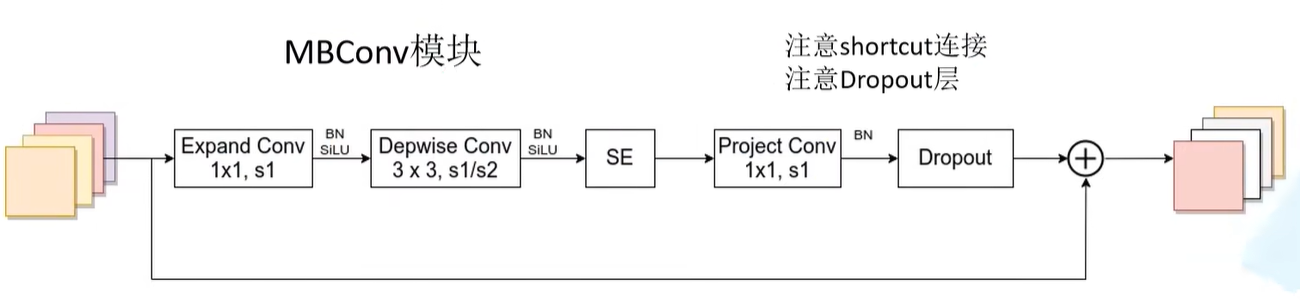
MBConv类
1 | class MBConv(nn.Module): |
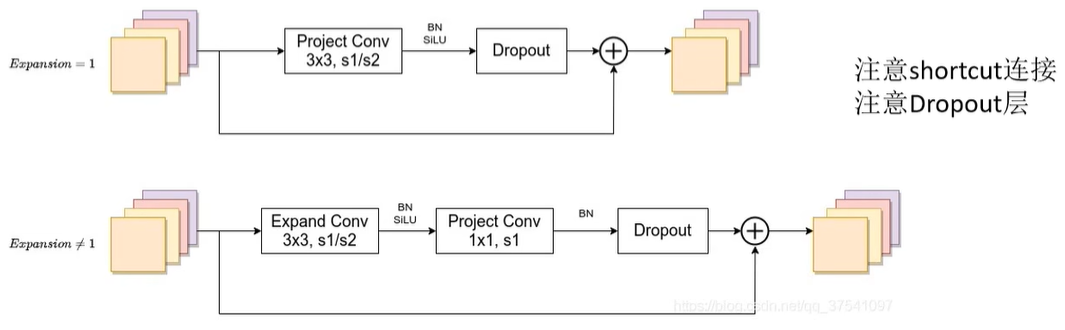
FusedMBConv类
1 | class FusedMBConv(nn.Module): |
EfficientNetV2类
1 | class EfficientNetV2(nn.Module): |
实例化efficientnetv2类
r代表当前Stage中Operator重复堆叠的次数;k代表kernel_size;s代表步距stride;e代表expansion ratio;i代表input channels;o代表output channels;c代表conv_type,1代表Fused-MBConv,0代表MBConv(默认为MBConv);se代表使用SE模块,以及se_ratio
1 | #################### EfficientNet V2 configs #################### |
按照配置文件实例化
1 | def efficientnetv2_s(num_classes: int = 1000): |
train.py
1 | import os |
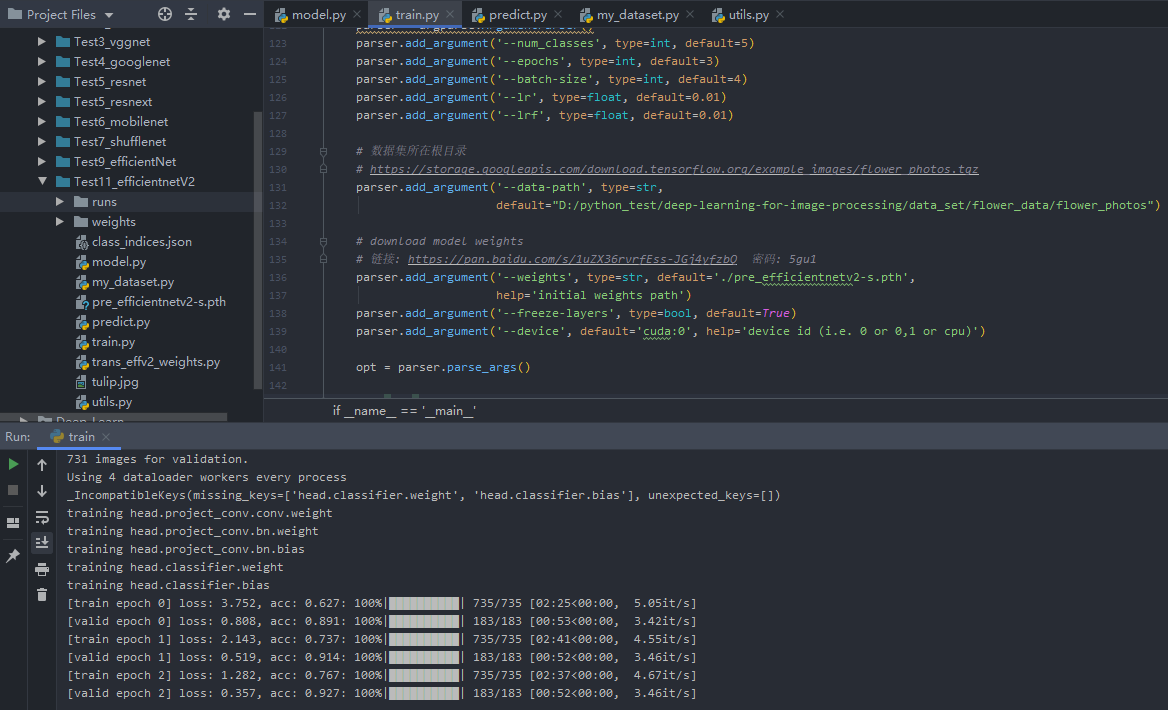
训练结果
predict.py
1 | import os |
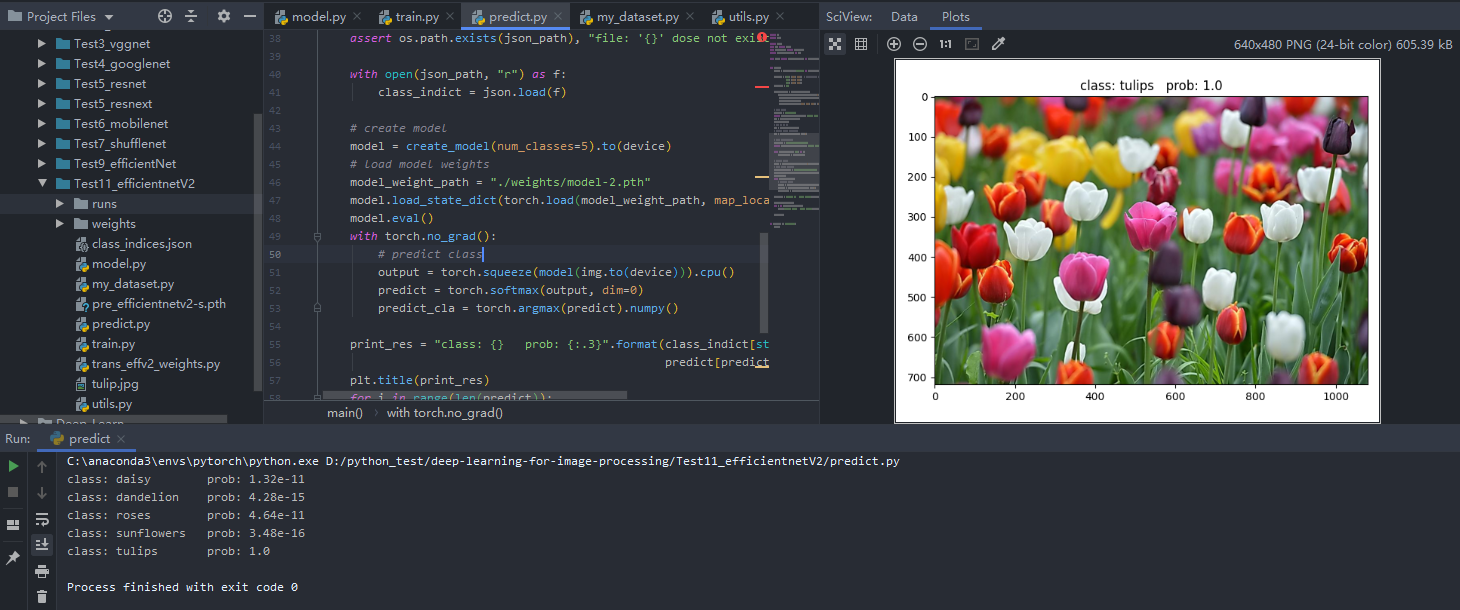
预测结果
utils.py
1 | import os |
my_dataset.py
1 | from PIL import Image |