深度学习模型之CNN(十八)使用Pytorch搭建EfficientNet网络
回顾
EfficientNet-B0网络结构
EfficientNet网络结构基本上分为9个Stage,第一个Stage是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish);第二至第八的Stage 都是使用MBConv,也就是在MobileNetv3所使用到的InvertedResidualBlock结构。
每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。
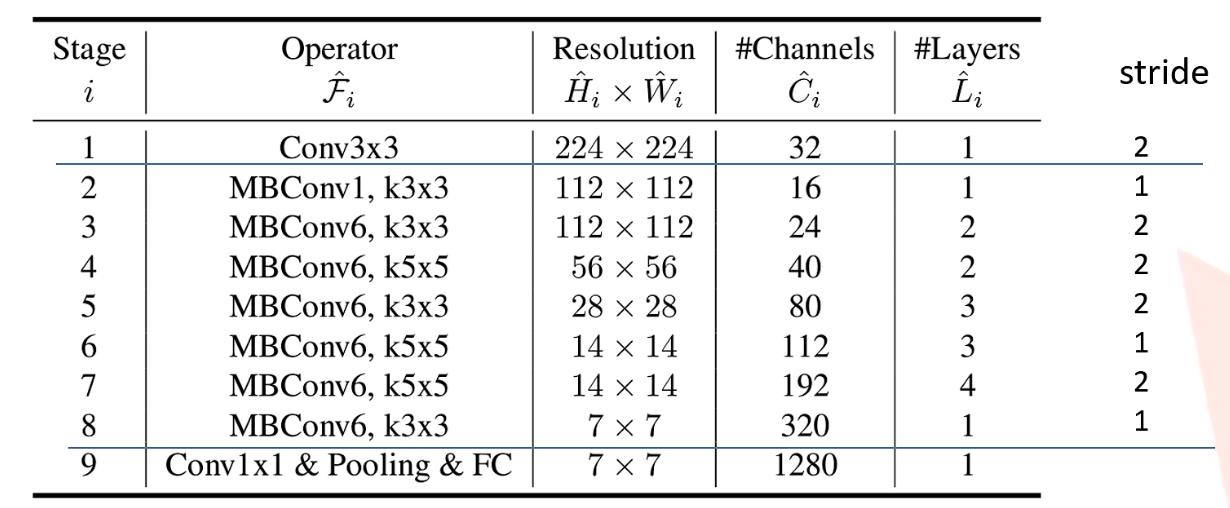
MBConv结构
MBConv结构主要由一个1x1的普通卷积(升维作用,包含BN和Swish),一个kxk的Depthwise Conv卷积(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的普通卷积(降维作用,包含BN),一个Droupout层构成。
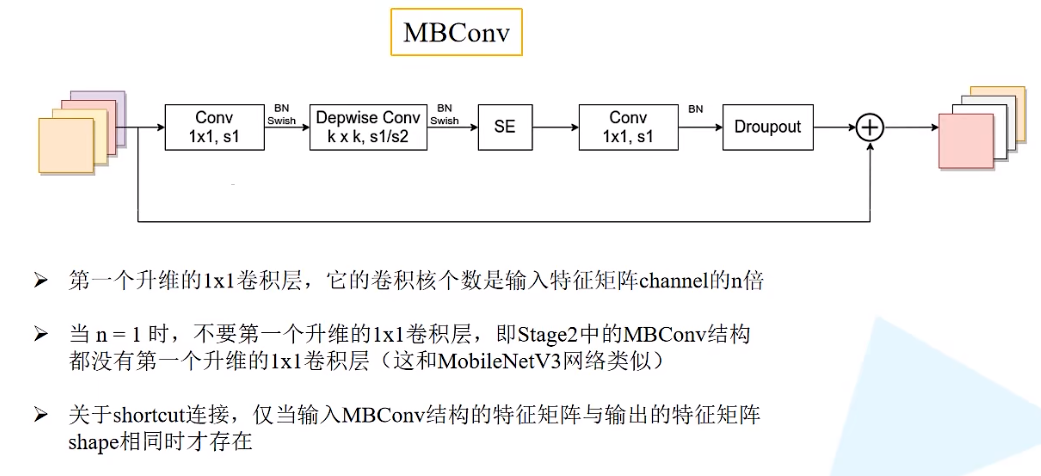
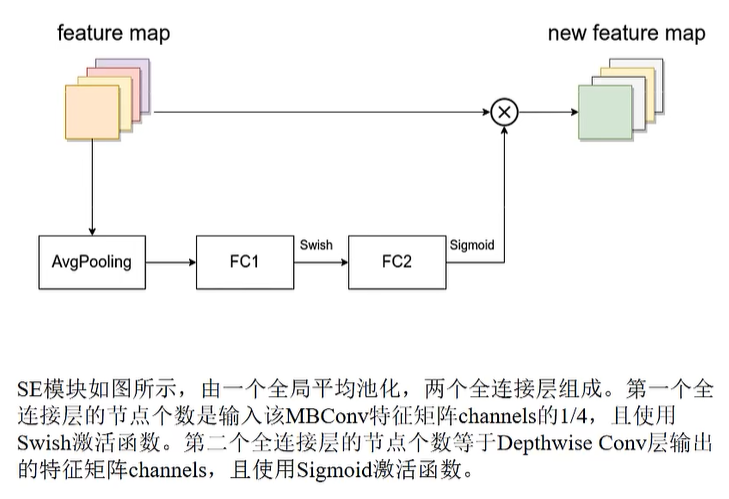
SE模块
工程目录
1 | ├── Test9_efficientnet |
搭建网络结构
代码框架
1 | import math |
_make_divisible函数
是为了将卷积核个数(输出的通道个数ch)调整为输入divisor参数的整数倍。搭建中采用divisor=8,也就是要将卷积核的个数设置为8的整数倍。
目的:为了更好的调用硬件设备,比如多GPU变形运算,或者多机器分布式运算
ch:传入的卷积核个数(输出特征矩阵的channel)divisor:传入round_nearest基数,即将卷积核个数ch调整为divisor的整数倍min_ch:最小通道数,如果为None,就将min_ch设置为divisornew_ch:即将卷积核个数调整为离它最近的8的倍数的值- 之后进行判断new_ch是否小于传入ch的0.9倍,如果小于,则加上一个divisor(为了确保new_ch向下取整的时候,不会减少超过10%)
1 | def _make_divisible(ch, divisor=8, min_ch=None): |
ConvBNActivation类
在MBConv结构中,基本上的组成都是卷积+BN+Swish激活函数(尽管第二次1x1卷积之后没有激活函数)
group:用来分辨是使用普通卷积还是dw卷积norm_layer:在EfficientNet中相当于BN结构activation_layer:BN结构之后的激活函数,当传入为nn.identity,指不做任何处理的方法nn.SiLU:实际上和Swish函数一样(只有官方torch版本≥1.7的时候,才有该激活函数)
1 | class ConvBNActivation(nn.Sequential): |
SE模块
input_c:对应的是MBConv模块输入特征矩阵的channel;expand_c:对应的是MBConv模块中第一个1x1的卷积层升维之后所输出的特征矩阵channel
由于MBConv模块中的dw卷积是不会对特征矩阵channel做变化的,因此dw卷积之后的特征矩阵channel与 = 第一层1x1卷积层之后的特征矩阵channel = expand_c
squeeze_factor:第一个全连接层的结点个数 = input_c // squeeze_factor(第一个全连接层原理上特别注意:是input_c除以4)
1 | class SqueezeExcitation(nn.Module): |
InvertedResidualConfig类
类似于MobileNetv3中的InvertedResidualConfig,在EfficientNet中,对应的是每一个MBConv模块中的配置参数。
-
kernel:每一层MBConv模块使用的kernel_size(即DW卷积中的卷积核大小,3x3 or 5x5); -
input_c:输入MBConv模块的特征矩阵channel; -
out_c:MBConv模块输出特征矩阵的channel; -
expanded_ratio:对应MBConv模块中1x1卷积层,用来调节每一个卷积层所使用channel的倍率因子; -
stride:指的是DW卷积所对应的步距; -
use_se:是否使用SE注意力机制; -
drop_rate:随机失活比例; -
index:记录当前MBConv模块的名称,用来方便后期分析; -
width_coefficient:关于网络宽度width上的倍率因子(实际上指特征矩阵的channel)。@staticmethod:静态方法(可以不实例化类就直接调用,主要是类显得不重要的时候用)
1 | class InvertedResidualConfig: |
InvertedResidual类(MBConv模块)
同MobileNetv3一致(从pytorch搭建MobileNetv3复制过来的)
cnf:前文提到的InvertedResidualConfig配置文件;norm_layer:对应的在卷积后接的BN层cnf.stride:判断步距是否为1或2,因为在网络参数表中,步距只有1和2两种情况,当出现第三种情况时,就是不合法的步距情况;再判断self.use_res_connect:是否使用shortcut连接,shortcut只有在stride == 1且input_c == output_c时才有;activation_layer:判断使用ReLU或者H-Swish激活函数(官方是在1.7及以上版本中才有官方实现的H-Swish和H-Sigmoid激活函数,如果需要使用MNv3网络的话,得把pytorch版本更新至1.7及以上)- expand区域指在InvertedResidual结构中的第一个1x1卷积层进行升维处理,因为第一个block存在输入特征矩阵的channel和输出特征矩阵的channel相等,因此可以跳过,所以会进行判断cnf.expanded_c != cnf.input_c;
- depthwise区域为dw卷积区域
groups:由于DW卷积是针对每一个channel都单独使用一个channel为1的卷积核来进行卷及处理,所以groups和channel的个数是保持一致的,所以groups=cnf.expanded_c
- project区域是InvertedResidual结构中1x1卷积中的降维部分,activation_layer=nn.Identity中的Identity其实就是线性y = x,没有做任何处理;
1 | class InvertedResidual(nn.Module): |
EfficientNet类
width coeficient:代表channel维度上的倍率因子,比如在 EfcientNetB0中Stagel的3x3卷积层所使用的卷积核个数是32,那么在B6中就是 32 X 18=57.6接着取整到离它最近的8的整数倍即56,其它Stage同理。depth coeficient:代表depth维度上的倍率因子(仅针对Stage2到Stage8),比如在EcientNetB0中Stage7的L=4,那么在B6中就是 4 X 2.6=10.4,接着向上取整即11。drop_connect_rate:对应MBConv模块Dropout层的随机失活比例(并不是所有层的Dropout都是0.2,而是渐渐从0增长至0.2);dropout_rate:MBConv模块中最后一个全连接层前面的Dropout层的随机失活比例,对应EfficientNet网络中Stage9当中FC全连接层前面的一个Dropout层的随机失活比例。
| Model | input_size | width_coefficient | depth_coefficient | drop_connect_rate | dropout_rate |
|---|---|---|---|---|---|
| EfficientNetB0 | 224x224 | 1.0 | 1.0 | 0.2 | 0.2 |
| EfficientNetB1 | 240x240 | 1.0 | 1.1 | 0.2 | 0.2 |
| EfficientNetB2 | 260x260 | 1.1 | 1.2 | 0.2 | 0.3 |
| EfficientNetB3 | 300x300 | 1.2 | 1.4 | 0.2 | 0.3 |
| EfficientNetB4 | 380x380 | 1.4 | 1.8 | 0.2 | 0.4 |
| EfficientNetB5 | 456x456 | 1.6 | 2.2 | 0.2 | 0.4 |
| EfficientNetB6 | 528x528 | 1.8 | 2.6 | 0.2 | 0.5 |
| EfficientNetB7 | 600x600 | 2.0 | 3.1 | 0.2 | 0.5 |
default_cnf:存储网络中Stage2~Stage8之间的默认配置文件
1 | class EfficientNet(nn.Module): |
实例化EfficientNet-B0~B7
1 | def efficientnet_b0(num_classes=1000): |
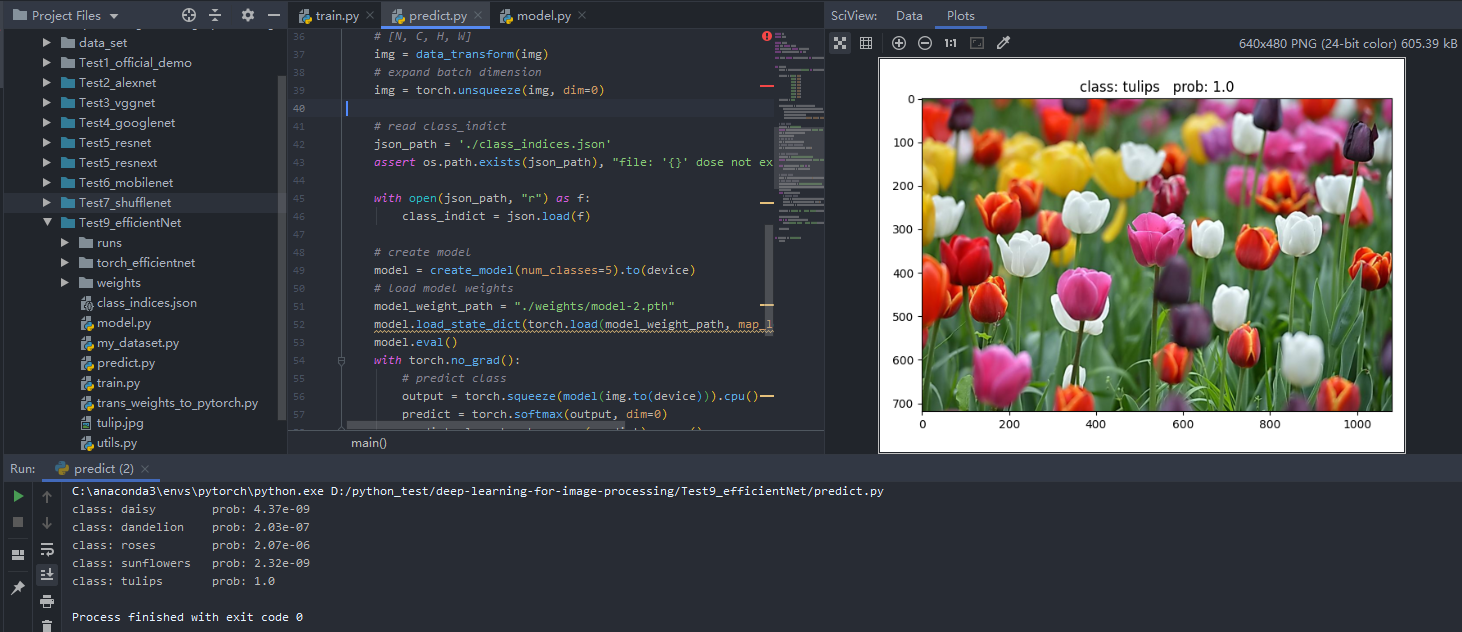
训练结果
注意:from model import efficientnet_b0 as create_model中的efficientnet_b0需要和`num_model = "B0"保持一致
1 | import os |
预测结果
1 | import os |