深度学习模型之CNN(十六)使用Pytorch搭建ShuffleNetv2
工程目录
1 | ├── Test7_shufflenet |
tips:
- 下载好数据集,代码中默认使用的是花分类数据集,下载地址: 花分类数据集, 如果下载不了的话可以通过百度云链接下载: 花分类数据集 提取码:58p0
- 在
train.py脚本中将--data-path设置成解压后的flower_photos文件夹绝对路径 - 下载预训练权重,在
model.py文件中每个模型都有提供预训练权重的下载地址,根据自己使用的模型下载对应预训练权重 - 在
train.py脚本中将--weights参数设成下载好的预训练权重路径 - 设置好数据集的路径
--data-path以及预训练权重的路径--weights就能使用train.py脚本开始训练了(训练过程中会自动生成class_indices.json文件) - 在
predict.py脚本中导入和训练脚本中同样的模型,并将model_weight_path设置成训练好的模型权重路径(默认保存在weights文件夹下) - 在
predict.py脚本中将img_path设置成你自己需要预测的图片绝对路径 - 设置好权重路径
model_weight_path和预测的图片路径img_path就能使用predict.py脚本进行预测了 - 如果要使用自己的数据集,请按照花分类数据集的文件结构进行摆放(即一个类别对应一个文件夹),并且将训练以及预测脚本中的
num_classes设置成你自己数据的类别数
model.py
1 | from typing import List, Callable |
channel_shuffle函数
将输入进来的特征矩阵channel平均分为group组(大组),平分之后再将每组内的channel平均分为group组(小组),之后在每组(大组)中索引相同的数据挪到一起,便实现了经过channel_shuffle操作之后,每一组中的数据都包含之前划分group组之后每一组的数据。
备注:2022年的pytorch中自带channel_shuffle函数,但自带的函数不能用GPU训练,推荐自己写一个。
1 | def channel_shuffle(x: Tensor, groups: int) -> Tensor: |
假设:num_channels = 6,groups = 3,view函数作用可如下图理解,将channel为6的数据划分为3个组。
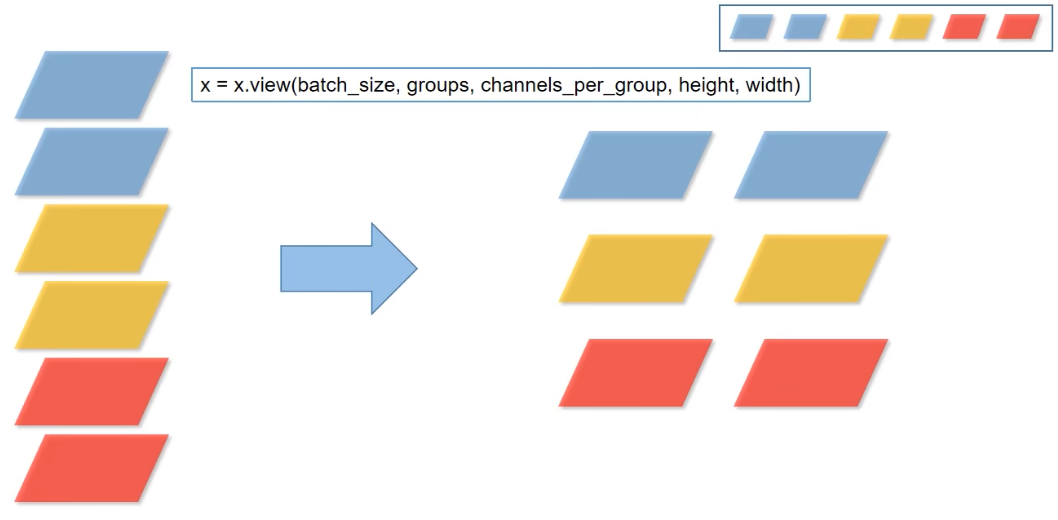
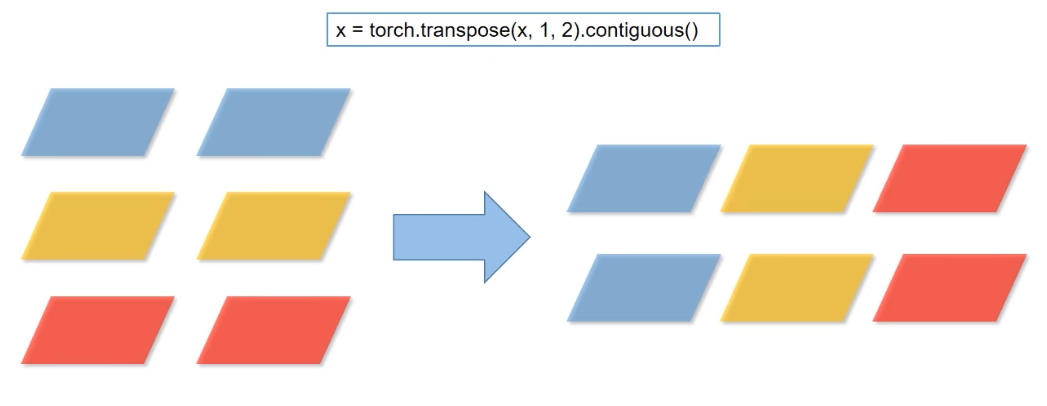
transpose方法:将维度1和维度2的数据进行调换(可以理解为转置)。contiguous:将Tensor数据转化为内存中连续的数据。
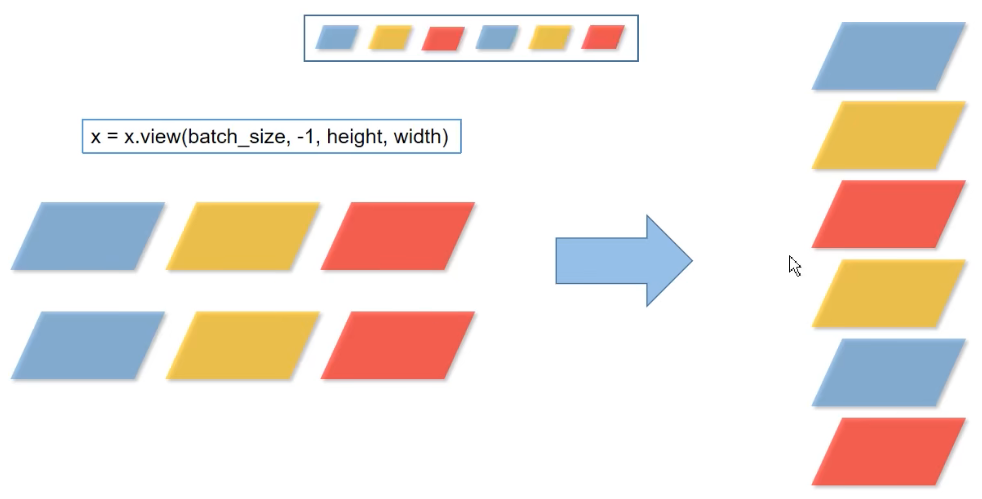
再通过view将transpose之后的数据进行展开**(view重塑张量,此处张量的元素个数为6,batch_size = 6,-1指元素排列形状的列数即为1)**
InvertedResidual类
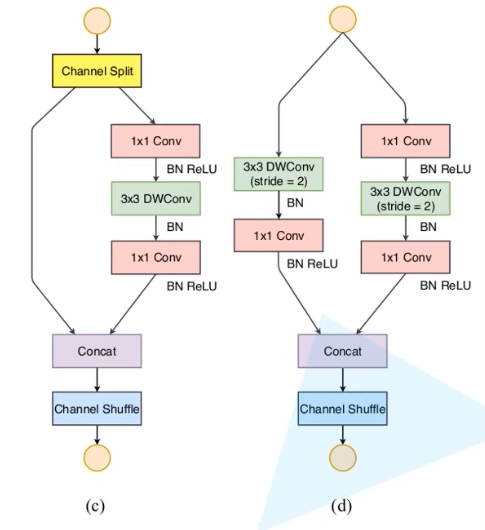
初始化函数
input_c:输入特征矩阵的channeloutput_c:输出特征矩阵的channelstride:DW卷积的步距branch1:(c)和(d)左边的分支,(c)分支stride = 1,特征矩阵(前面以及经过channel split)保持不变,(d)分支stride = 2,先经过3x3的DW卷积将深度变为原来的一半,再通过1x1的普通卷积;branch2:(c)和(d)右边的分支,且处理一致。先通过1x1的普通卷积((c)中深度保持不变,(d)中深度为原先的一半),再通过3x3的dw卷积,以及1x1的普通卷积;
1 | class InvertedResidual(nn.Module): |
depthwise_conv函数
1 | def depthwise_conv(input_c: int, |
forward函数
当self.stride == 1时,通过chunk函数将x在dim = 1的维度上进行2分处理(通道位**[ batch, channel, height, width ]**),再通过torch.cat函数将x1(stride = 1时左分支不做处理)与经过self.branch2函数处理的x2进行concat拼接得到输出特征矩阵;
在另一种stride == 2的情况下,直接将x带入self.branch1和self.branch2函数,并将输出特征矩阵进行拼接,得到最终特征矩阵;
之后将输出特征矩阵在深度上分成2组进行channel_shuffle处理
1 | def forward(self, x: Tensor) -> Tensor: |
ShuffleNetV2类
shufflenetv2网络结构
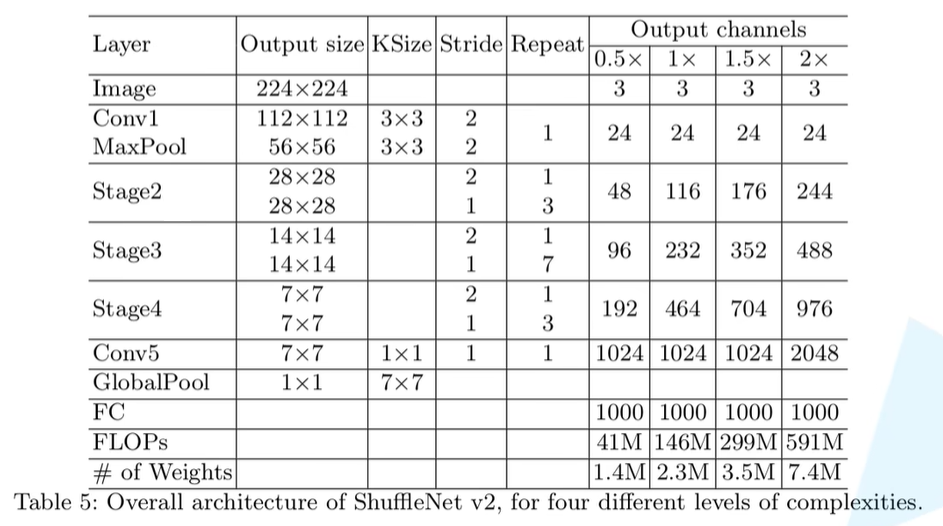
初始化函数
stages_repeats:shufflenet_v2_x1_0版本中,内容为[4, 8, 4];stages_out_channels:对应[ Conv1,Stage2,Stage3,Stage4,Conv5 ],shufflenet_v2_x1_0版本中,内容为[24, 116, 232, 464, 1024];self.stage2: nn.Sequential:表示声明self.stage2是通过nn.Sequential来实现的- 通过zip函数将
stage_names、stages_repeats和self._stage_out_channels列表打包成字典的形式(shufflenet_v2_x1_0版本中,self._stage_out_channels只到1024前一个,即464。因为前两个列表长度都为3),打包之后形式为
{stage_names:Stage2,stages_repeats:4,self._stage_out_channels:116}
setattr函数:给self设置一个变量,变量名称为{name},变量的值为nn.Sequential(*seq),即每一个Stage的每个block输出特征矩阵的列表值,所以构建好Stage的一系列层结构;
1 | class ShuffleNetV2(nn.Module): |
forward函数
x = self.stage2(x):关联初始化函数的self.stage2: nn.Sequential,继续关联到setattr(self, name, nn.Sequential(*seq))mean方法:进行全局池化操作,[ 2, 3 ] 分别指高度和宽度两个维度进行求均值的操作
1 | def _forward_impl(self, x: Tensor) -> Tensor: |
实例化ShuffleNet
1 | def shufflenet_v2_x0_5(num_classes=1000): |
train.py
1 | import os |
此处使用迁移学习方法,除了最后的全连接层,前面参数都来自官方shufflenetv2_x1权重,如果想要自己训练模型,则需要进行两步:
parser.add_argument,default=‘shufflenetv2_x1.pth’ ==> default=‘’;default=True==> default = False
1 | if __name__ == '__main__': |
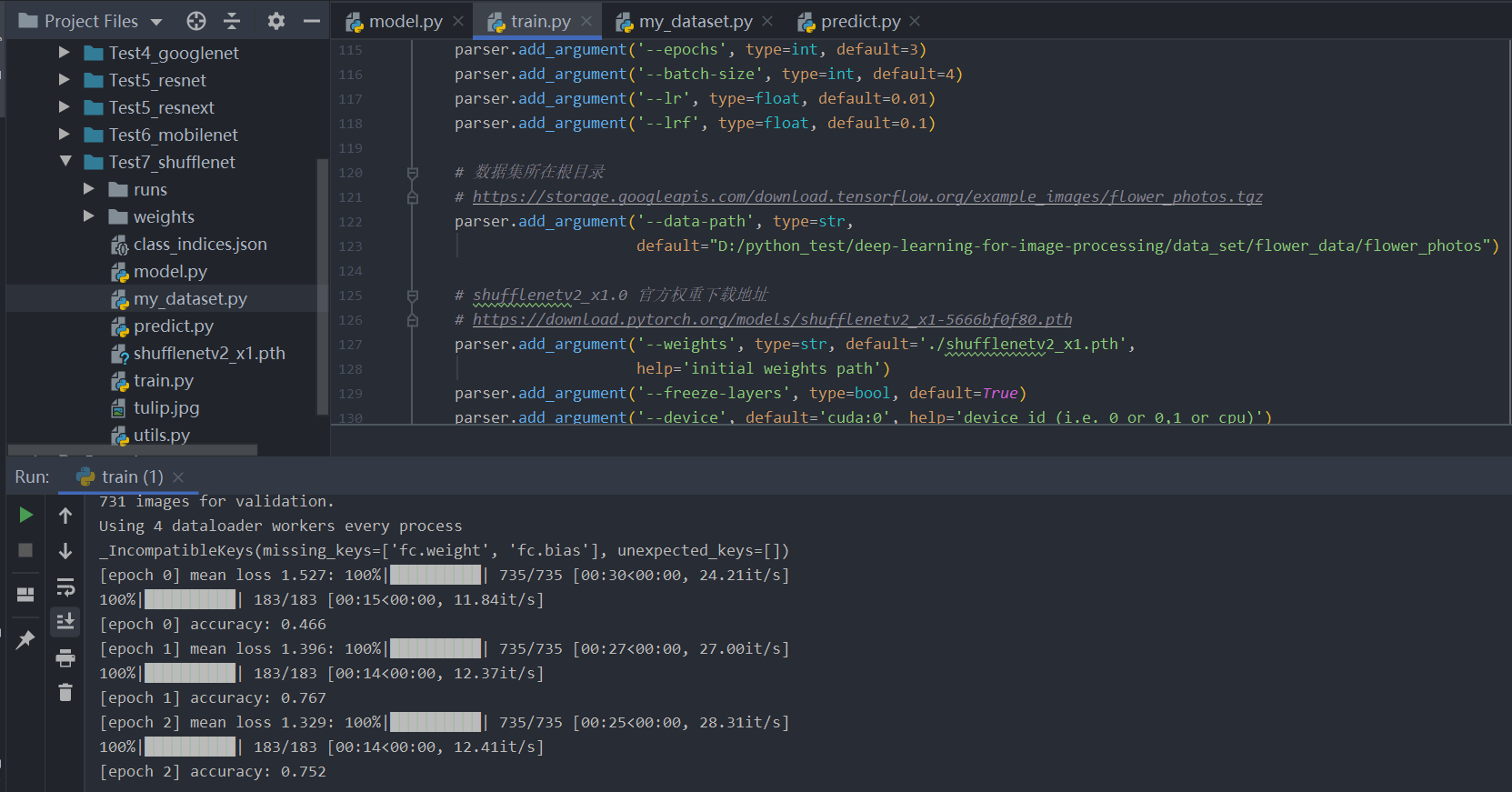
训练结果
predict.py
1 | import os |
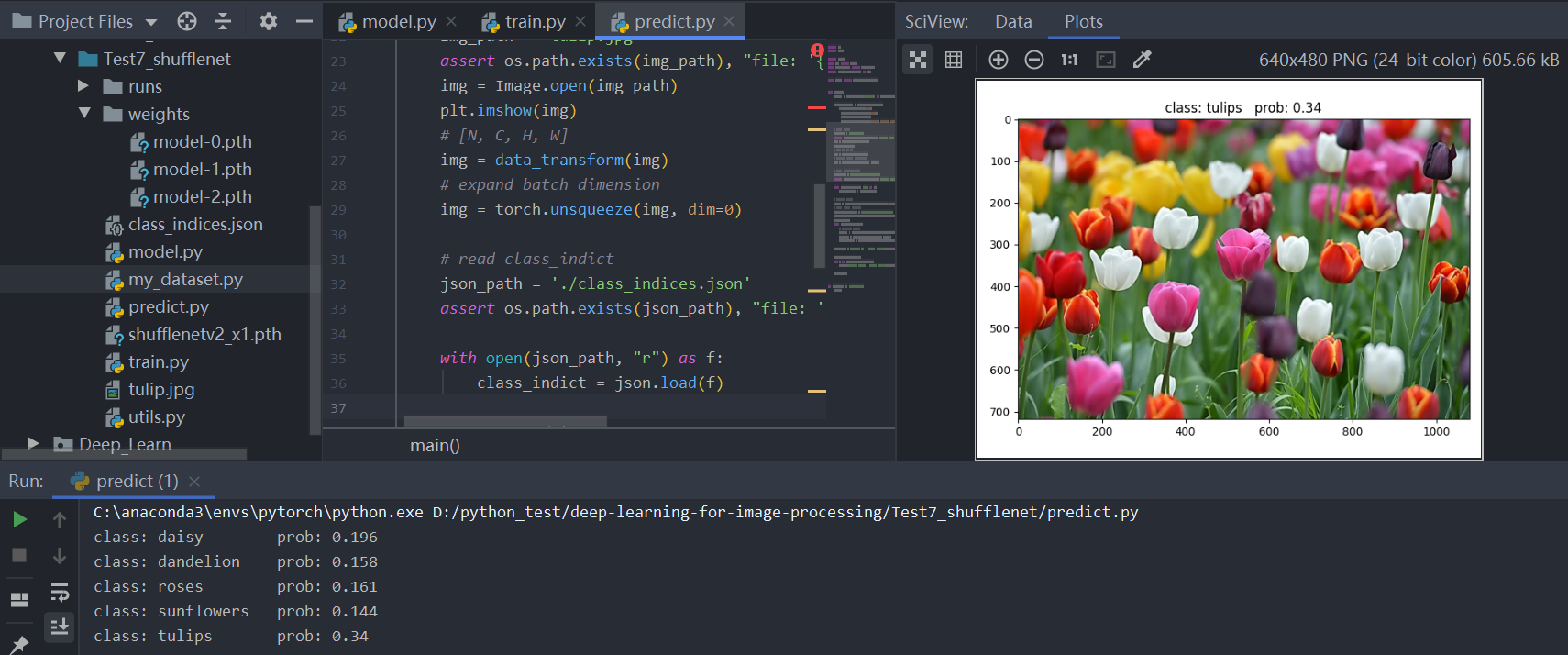
预测结果
utils.py
1 | import os |
my_dataset.py
1 | from PIL import Image |