深度学习模型之CNN(十四)使用pytorch搭建MobileNetV2V3并基于迁移学习训练
MobileNet v2v3网络搭建
工程目录
1 | ├── Test6_mobilenet |
model_v2.py
1 | from torch import nn |
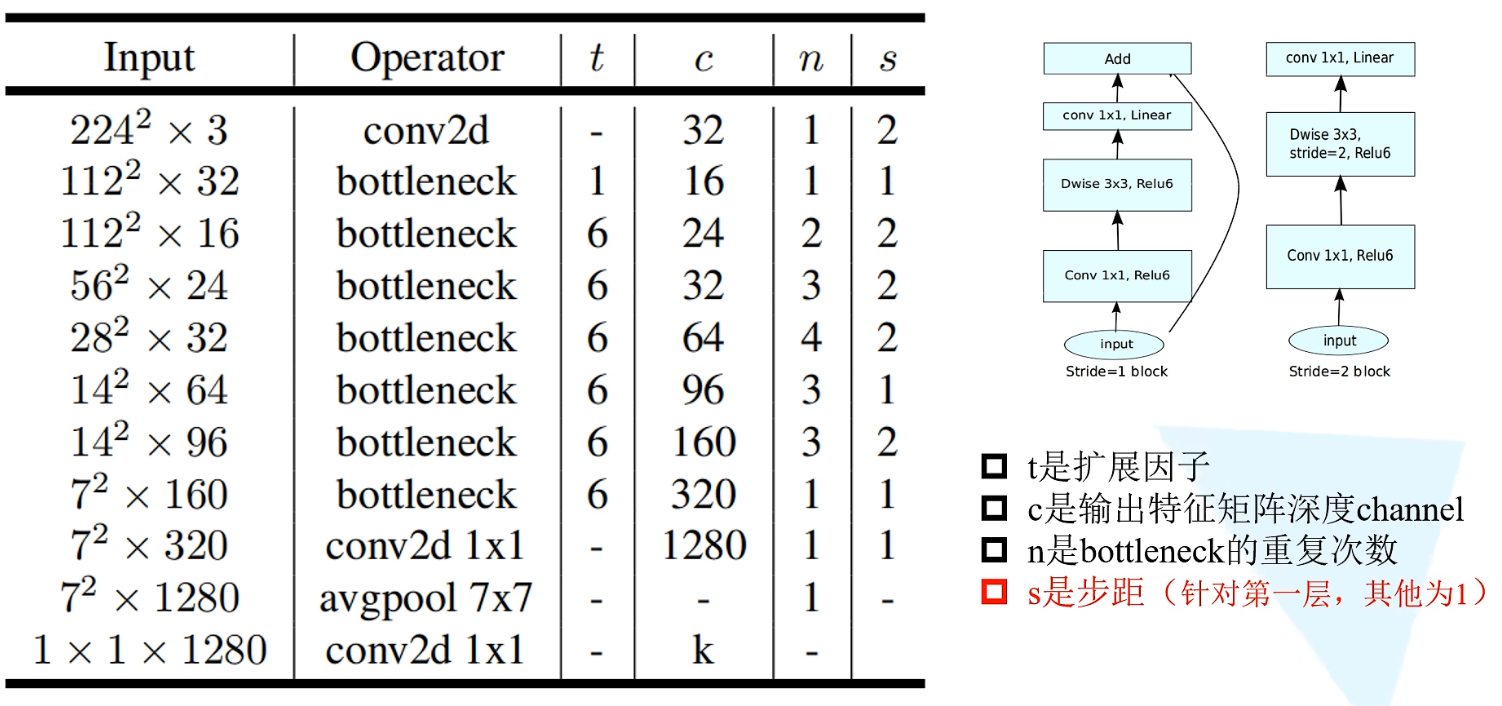
网络结构参数
先通过普通卷积,之后进行一个Inverted residual结构(n:倒残差结构重复几遍),一直重复倒残差结构,再通过1x1的普通卷积操作,紧接着平均池化下采样,最后是通过1x1卷积得到最终输出(作用同全连接层)
搭建该网络重点在于搭建好Inverted residual结构
ConvBNReLU类
ConvBNReLU类是包含conv、BN和ReLU6激活函数的组合层。在MNv2网络中,所有卷积层以及上节课所讲的DW卷积操作,基本上都是由卷积+BN+ReLU6激活函数组成的。
唯一不同的是在Inverted residual结构中的第三层,也就是使用1x1的卷积对特征矩阵进行降维处理,这里使用线性激活函数,其他地方就都是通过卷积+BN+ReLU6激活函数组成。
因此创建ConvBNReLU类,继承来自nn.Sequential父类(nn.Sequential不需要写forward函数,此处参照pytorch的官方实现)
1 | class ConvBNReLU(nn.Sequential): |
Inverted residual结构
类似于ResNet中的残差结构,只不过普通的ResNet的残差结构是两头粗中间细的结构,但倒残差结构是两头细中间粗的结构。
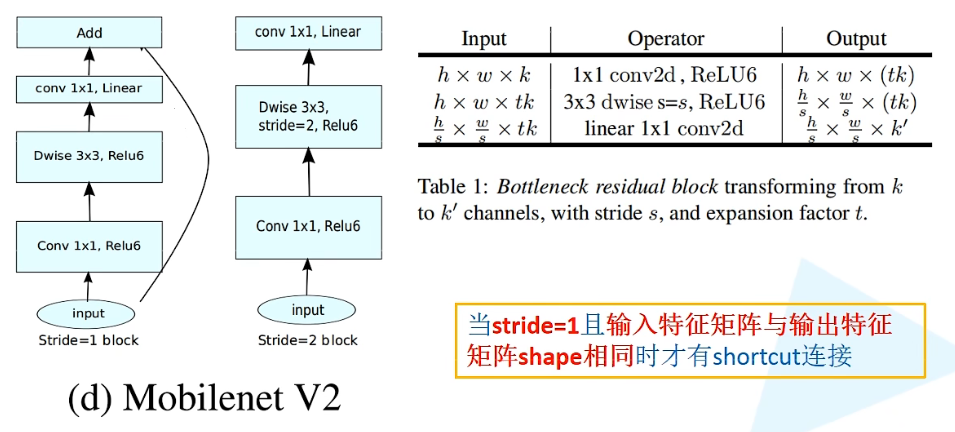
第一层:普通卷积层,卷积核大小为1x1,激活函数是ReLU6,采用卷积核个数为tk(t是倍率因子,用来扩大特征矩阵深度);
第二层:DW卷积,卷积核大小为3x3,步距stride = s(传入参数),激活函数是ReLU6,卷积核个数 = 输入特征矩阵深度 = 输出特征矩阵深度,缩减高宽;
第三层:普通1x1卷积层,采用线性激活函数,卷积核个数为k‘(人为设定)
__init__函数
- 初始化函数传入参数
expand_ratio:拓展因子,即上图表中的t - 定义隐层
hidden_channel:第一层卷积核的个数,即上图表中的tk self.use_shortcut:是一个bool变量,判断在正向传播过程中是否采用shortcut(只有当stride = 1且输入特征矩阵的shape与输出特征矩阵的shape保持一致市才能使用sortcut)- 定义层列表
layers:判断expand_ratio是否等于1(在v2网络结构参数表中的第一个bottleneck的第一层中,n = 1,s = 1,因此特征矩阵的shape都未发生变化,因此在搭建过程中进行跳过),当expand_ratio = 1时,跳过该处1x1卷积层。
假设此处expand_ratio!= 1,那么就需要在layers列表中添加一个卷积层,调用ConvBNReLU层结构(输入特征矩阵深度,hidden_channel,由上图(右表)得知第一层卷积核大小为1x1)。
- 调用
layers.extend函数:添加一系列层结构,实际上通过extend和append函数添加层结构是一样的,只不过extend函数能够实现一次性批量插入多个元素。
对于Inverted residual结构,第二层是DW卷积,因此此处调用定义好的ConvBNReLU层结构,输入特征矩阵深度为上一层的输出特征矩阵深度hidden_channel,输出深度同样为hidden_channel(因为DW卷积层的输入特征矩阵深度和输出特征矩阵深度是一样的)
stride是传入的参数,group默认为1时是普通卷积,当传入与输入特征矩阵深度相同的个数的话,就是DW卷积。而此处输入特征矩阵的深度是hidden_channel,因此此处groups=hidden_channel。
第三层是1x1的普通卷积,所采用的的激活函数是线性激活函数(y = x),不能使用定义好的ConvBNReLU,因此使用原始的Conv2d,输入特征矩阵深度为上一层输出特征矩阵深度,输出特征矩阵深度为传入参数out_channel,卷积核大小为1
最后使用Batch Normalization标准化处理。
注意:因为第三层使用线性激活函数y = x,等于不对输入做任何处理,因此不需要再额外定义一个激活层函数,因为不添加激活层函数,就等于linear激活函数
- 最后通过nn.Sequential类将*layers参数传入进去(*用于将层列表解包为位置参数,这使我们能够像船体单个参数一样将层列表传递给Sequential模块
1 | class InvertedResidual(nn.Module): |
forward函数
x为输入特征矩阵
首先进行判断,是否使用shortcut,如果使用即返回特征矩阵与shortcut相加之后的输出特征矩阵;如果不使用shortcut,则直接返回主分支上的输出特征矩阵。
1 | def forward(self, x): |
_make_divisible函数
是为了将卷积核个数(输出的通道个数)调整为输入round_nearest参数的整数倍。搭建中采用round_nearest=8,也就是要将卷积核的个数设置为8的整数倍。
目的:为了更好的调用硬件设备,比如多GPU变形运算,或者多机器分布式运算
ch:传入的卷积核个数(输出特征矩阵的channel)divisor:传入round_nearest基数,即将卷积核个数ch调整为divisor的整数倍min_ch:最小通道数,如果为None,就将min_ch设置为divisornew_ch:即将卷积核个数调整为离它最近的8的倍数的值- 之后进行判断new_ch是否小于传入ch的0.9倍,如果小于,则加上一个divisor(为了确保new_ch向下取整的时候,不会减少超过10%)
1 | def _make_divisible(ch, divisor=8, min_ch=None): |
定义MNv2网络
block:将前面定义的InvertedResidual类传给blockinput_channel:是第一层卷积层所采用的卷积核的个数,也就是下一层输出特征矩阵的深度,为8的倍数last_channel:指的是参数表中1x1的卷积核,输出特征矩阵深度为1280inverted_residual_setting:根据参数表创建list列表,列表中的元素对应着参数表中每一行的参数t(拓展因子)、c(输出channel)、n(倒残差结构重复次数)、s(每一个block第一层卷积层的步距)features:在其中先添加第一个卷积层,输入channel即彩色图片
通过循环定义一系列的Inverted residual结构。将每一层output_channel通过_make_divisible函数进行调整,再进行n次的Inverted residual(在循环中除了列表中的stride = s,其他都是 = 1)
在经过一系列Inverted residual处理后,接下来的是一个1x1的卷积层,直接使用ConvBNReLU
-
self.features:通常将以上一系列层结构统称为特征提取层,所以Sequential将刚刚定义好的一系列层结构通过位置参数的形式传入进去,打包成一个整体。 -
定义由
self.avgpool和self.classifier组成的分类器首先定义平均池化下采样层(采用自适应的平均池化下采样操作,给定输出特征矩阵的高宽为1)
再通过nn.Sequential将Dropout层和全连接层组合在一起
1 | class MobileNetV2(nn.Module): |
权重初始化
- 遍历每一个子模块,如果是卷积层,就对权重进行初始化,如果存在偏置,则将偏置设置为0;
- 如果子模块是一个BN层,则将方差设置为1,均值设置为0;
- 如果子模块是一个全连接层的话,对权重进行初始化,normal_函数为一个正态分布函数,将权重调整为均值为0.0,方差为0.01的正态分布;将偏置设置为0
1 | # weight initialization |
正向传播过程
首先将输入特征矩阵输入进特征提取部分,通过平均池化下采样得到输出,再对输出进行展平处理,最后通过分类器得到最终输出。
1 | def forward(self, x): |
model_v3.py
1 | from typing import Callable, List, Optional |
_make_divisible函数
同MobileNet v2中的_make_divisible作用一致,是为了将卷积核个数(输出的通道个数)调整为输入round_nearest参数的整数倍。搭建中采用round_nearest=8,也就是要将卷积核的个数设置为8的整数倍。
1 | def _make_divisible(ch, divisor=8, min_ch=None): |
ConvBNActivation类
ConvBNActivation类是包含conv、BN和激活函数的组合层。
in_planes:输入特征矩阵的深度out_planes:输出特征矩阵的深度,对应卷积核的个数norm_layer:对应的在卷积后接的BN层activation_layer:对应激活函数
1 | class ConvBNActivation(nn.Sequential): |
SqueezeExcitation模块
初始化函数
相当于两个全连接层。
- 对于第一个全连接层,此处的节点个数 = 该处输入的特征矩阵channel的1/4(在v3原论文中作者有给出)
- 第二层全连接层的节点个数 = 该处输入的特征矩阵channel
- 第一个全连接层的激活函数是ReLU,第二个全连接层的激活函数是hard-sigmoid
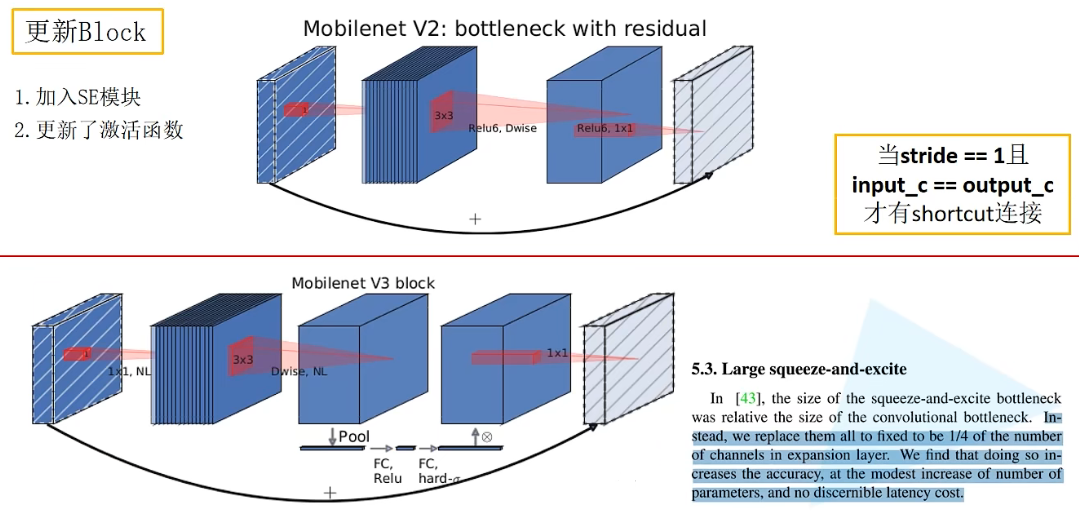
squeeze_factor:因为第一个全连接层的节点个数是输入的特征矩阵channel的1/4,所以这里存放的是分母4;squeeze_c:调用_make_divisible方法调整到离该数最近的8的整数倍的数字;self.fc1:使用卷积来作为全连接层,作用与全连接层一样self.fc2:输入channel是上一层的输出channel,所以是squeeze_c,又因为SE机制最终输出需要和输入特征矩阵的channel保持一致,所以输出channel为input_c
1 | class SqueezeExcitation(nn.Module): |
正向传播函数
如上图(下)第三个特征矩阵需要进行池化操作,因此进行自适应池化下采样操作,并且返回特征矩阵的高宽是1x1。再将拿到的输出通过全连接层,relu激活函数,第二层全连接层,和一个h-sigmoid激活函数,得到输出。这里的输出就是第二层全连接层的输出,也就是得到了不同channel对应的权重。
接下来需要将输出与原特征矩阵相乘,得到通过SE模块之后的输出。
1 | def forward(self, x: Tensor) -> Tensor: # 返回Tensor结构 |
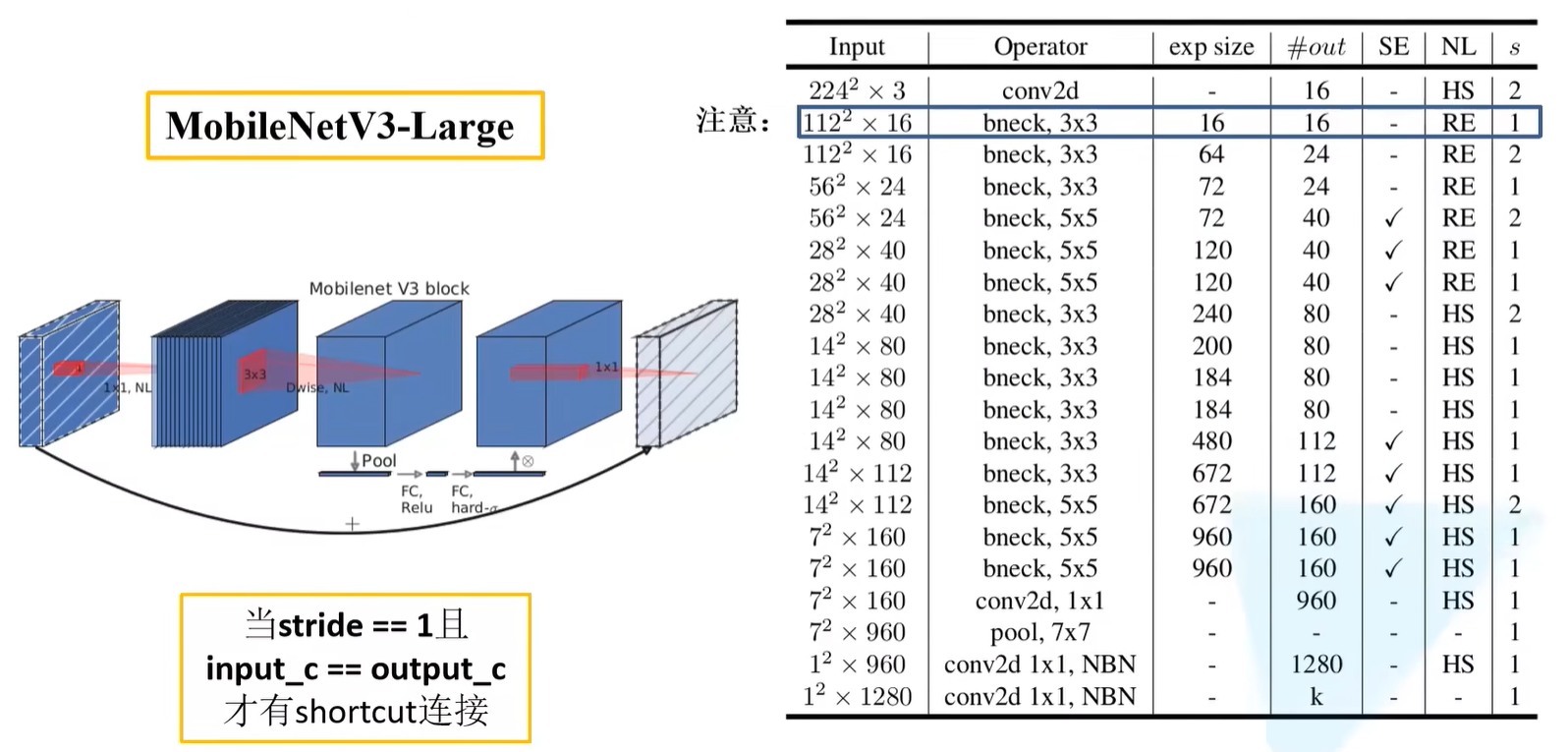
InvertedResidualConfig类
InvertedResidualConfig对应的是MobileNetV3中的每一个bneck结构的参数配置,其中有
input_c:输入特征矩阵的大小(主要指channel);kernel:每一层使用的kernel_size(即DW卷积中的卷积核大小);expanded_c:第一层卷积层所采用的的卷积核的个数;out_c:最后一层1x1的卷积层输出得到特征矩阵的channel;use_se:是否使用SE注意力机制;activation:采用的激活函数,RE表示采用ReLU激活函数,HS表示采用H-Swish激活函数;stride:指的是DW卷积所对应的步距;width_multi:就是MNv2中提到的$\alpha$参数,用来调节每一个卷积层所使用channel的倍率因子。
1 | class InvertedResidualConfig: |
adjust_channels函数
是一个静态方法,其实也是直接调用了_make_divisible方法,传入参数为channel和$\alpha$倍率因子,最终得到channel和$\alpha$的乘积离8最近的整数倍的值。
1 |
|
InvertedResidual类
初始化函数
cnf:前文提到的InvertedResidualConfig配置文件;norm_layer:对应的在卷积后接的BN层cnf.stride:判断步距是否为1或2,因为在网络参数表中,步距只有1和2两种情况,当出现第三种情况时,就是不合法的步距情况;再判断self.use_res_connect:是否使用shortcut连接,shortcut只有在stride == 1且input_c == output_c时才有;activation_layer:判断使用ReLU或者H-Swish激活函数(官方是在1.7及以上版本中才有官方实现的H-Swish和H-Sigmoid激活函数,如果需要使用MNv3网络的话,得把pytorch版本更新至1.7及以上)- expand区域指在InvertedResidual结构中的第一个1x1卷积层进行升维处理,因为第一个kneck存在输入特征矩阵的channel和输出特征矩阵的channel相等,因此可以跳过,所以会进行判断cnf.expanded_c != cnf.input_c;
- depthwise区域为dw卷积区域
groups:由于DW卷积是针对每一个channel都单独使用一个channel为1的卷积核来进行卷及处理,所以groups和channel的个数是保持一致的,所以groups=cnf.expanded_c
- project区域是InvertedResidual结构中1x1卷积中的降维部分,activation_layer=nn.Identity中的Identity其实就是线性y = x,没有做任何处理;
1 | class InvertedResidual(nn.Module): |
正向传播函数
将特征矩阵传入block方法得到主分支输出特征矩阵,再经过判断是否有shortcut,如果有则相加,无则直接输出主分支特征矩阵。
1 | def forward(self, x: Tensor) -> Tensor: |
定义MNv3类
初始化函数
inverted_residual_setting:对应一系列bneck结构参数的列表;last_channel:对应是MNv3网络参数表中倒数第二个全连接层的输出节点的个数;block:就是之前定义的InvertedResidual模块;norm_layer:对应的在卷积后接的BN层;
当inverted_residual_setting为空或者不是一个list的话都会报错。
building first layer创建第一层conv2d
firstconv_output_c获取第一个bneck结构的输入特征矩阵的channel,所对应的是第一个卷积层输出的channel;
ConvBNActivation对应的是第一个conv2d,无论是v3-Large还是v3-Small,第一个都是3x3的卷积层。所以先创建了一个3x3的卷积层。
building inverted residual blocks创建block模块
遍历每一个bneck结构,将每一层的配置文件和norm_layer都传给block,将创建好的每一个block结构,也就是InvertedResidual模块给填进layers当中。
building last several layers创建平均池化下采样层和几个卷积层
lastconv_input_c:最后一个bneck模块的输出特征矩阵channel;
lastconv_output_c:无论是v3-Large还是v3-Small,lastconv_output_c都是lastconv_input_c的6倍
1 | class MobileNetV3(nn.Module): |
正向传播函数
将输入特征矩阵依次通过特征提取、平均池化、展平和classifier处理得到输出结果
1 | def _forward_impl(self, x: Tensor) -> Tensor: |
定义mobilenet_v3_large
width_multi:$\alpha$超参数,用来调整channel;bneck_conf:同样使用partial方法,给InvertedResidualConfig方法传入默认参数width_multi,即$\alpha$超参数;adjust_channels:即InvertedResidualConfig类中的adjust_channels方法,使用partial方法,给InvertedResidualConfig.adjust_channels方法传入默认参数width_multi,即$\alpha$超参数;reduce_divider:对应最后三层bneck结构,对卷积的channel进行了调整,这里默认为False,指不做调整,如果设置为True,可以减少一些参数。
1 | def mobilenet_v3_large(num_classes: int = 1000, |
定义mobilenet_v3_small
1 | def mobilenet_v3_small(num_classes: int = 1000, |
train.py
下载官方权重文件:输入import torchvision.model.mobilenet,ctrl+左键进入函数当中,会有显示下载链接
该训练脚本与前期使用的AlexNet、VGG、GooglNet以及ResNet所使用的训练脚本基本一致。
1 | import os |
**需要注意的不同点:**模型权重加载部分
首先实例化模型,将类别个数设置为5;
通过torch.load函数载入预训练参数,载入进之后是一个字典类型。因为官方是在ImageNet数据集上进行预训练,所以最后一层全连接层的节点个数 = 1000,而我们这最后一层节点个数 = 5,所以最后一层不能用。
因此首先遍历权重字典,查找权重名称中是否含有classifier参数,如果有这个参数,说明是最后一层全连接层的参数。如果没有classifier,则直接保存进pre_dict字典变量当中。
再通过net.load_state_dict函数将不包含classifier全连接层的权重字典全部载入进去。
之后冻结特征提取部分的所有权重,通过遍历net.features下的所有参数,将参数的requires_grad全部设置为False,这样就不会对其进行求导及参数更新
1 | # create model |
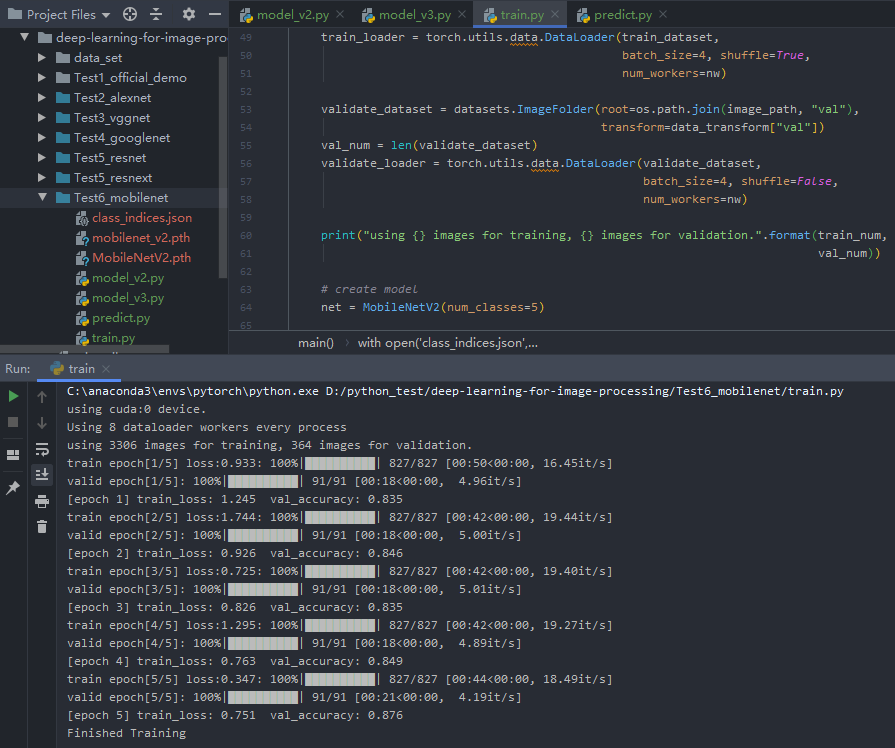
MNv2训练结果
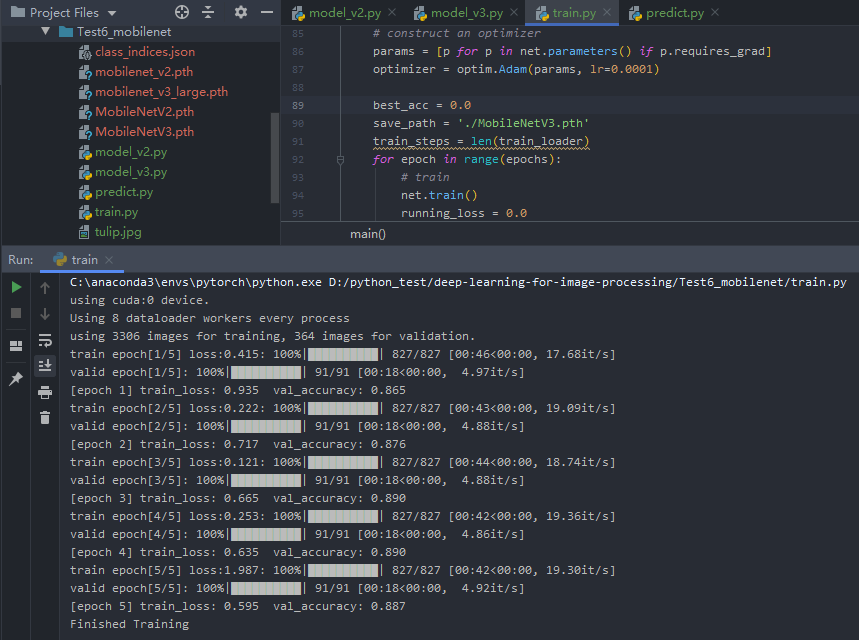
MNv3-Large训练结果
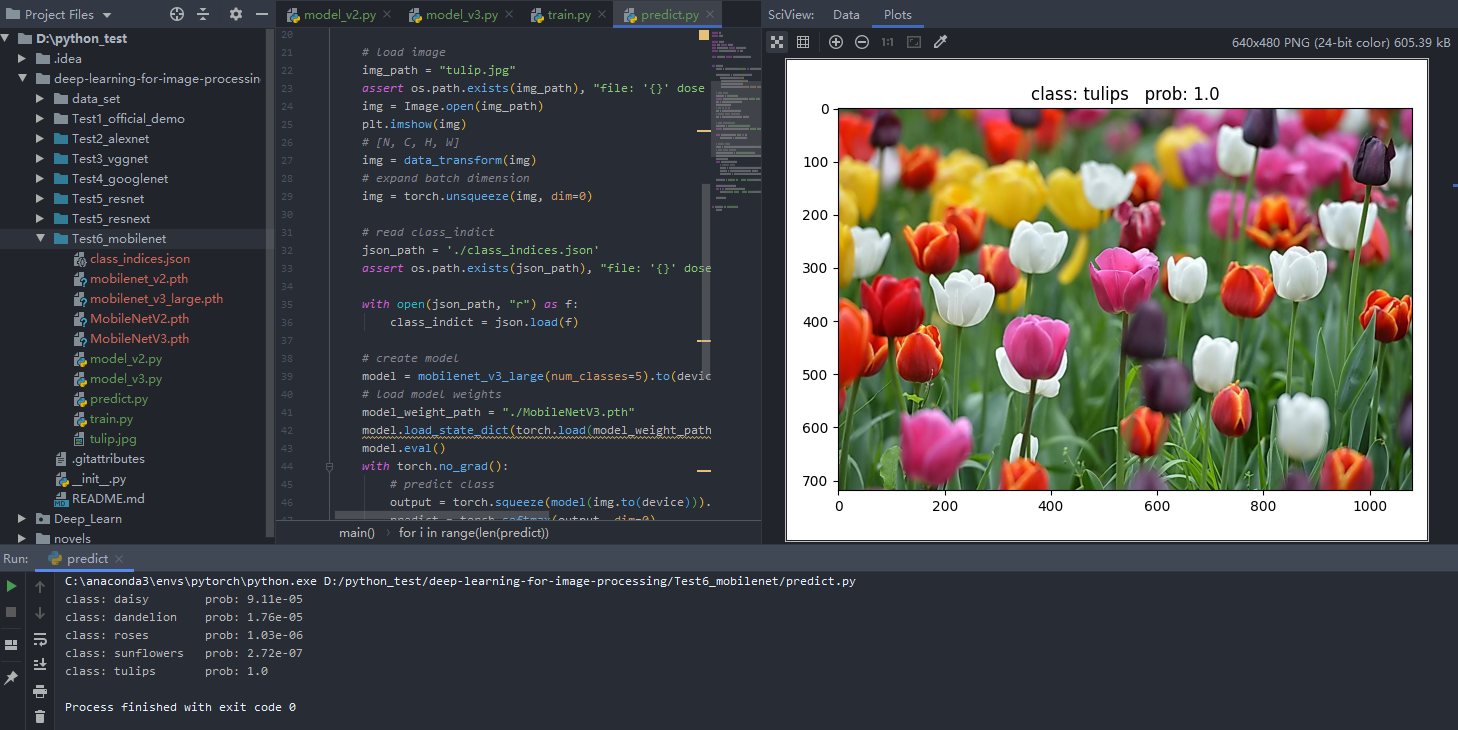
predict.py
1 | import json |
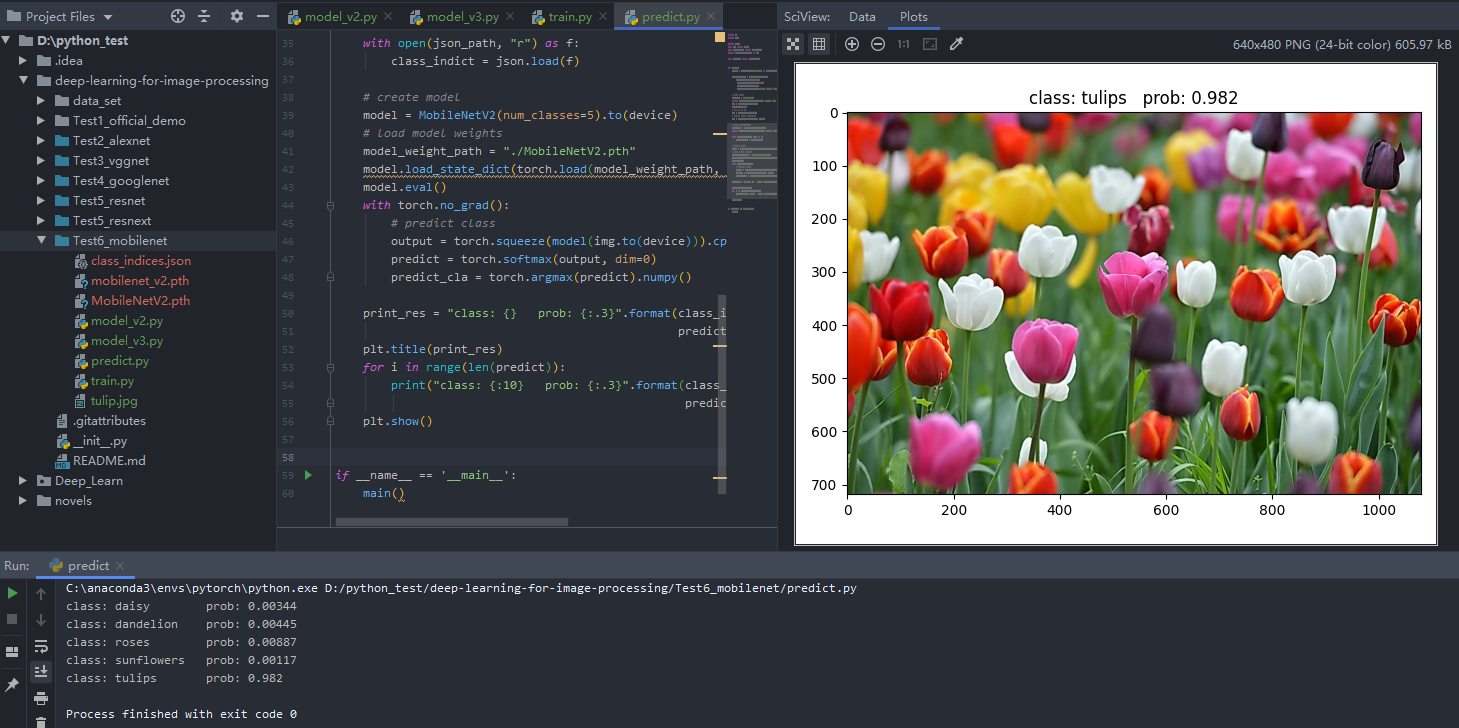
MNv2预测结果
MNv3-Large预测结果