深度学习模型之CNN(十二)使用pytorch搭建ResNeXt并基于迁移学习训练
ResNet-50与ResNeXt-50(32x4d)
参数.png)
ResNet网络结构中的较深层结构(50层及以上结构)所采用的是上图(最左侧)的block结构,在ResNeXt网络结构中所对应采用的是上图(中间)的block结构。
区别在于结构显示中的第二层的3x3卷积层,对于普通的block结构(如最左侧),采用普通的3x3进行卷积,而对于ResNeXt的block(如中间),第二层是group conv。
ResNet-50和ResNeXt结构
相同点:
- 整体框架一致。首先经过一个7x7的卷积层将输入的特征矩阵深度从3变为64,高宽不变;之后经过3x3的最大池化下采样层,深度不变,高宽从112变为56;之后重复堆叠block,且堆叠次数一致,图中都是 [ 3,4,6,3 ];之后是平均池化、全连接层,最后是softmax概率输出。
- 在每一个网络结构相对应的block中,输出的特征矩阵的深度是一致的。
不同点:
以conv2为例,在ResNet网络结构中第一层采用1x1卷积层的个数是64,但在对应ResNeXt网络结构中的个数是普通block结构中采用卷积核个数的2倍,在下一层3x3的卷积层中,ResNet采用64个卷积核,而ResNeXt中分成了32group,每个group采用4个卷积核,所以ResNeXt第二层中采用128个卷积核。
因此,在每一层block结构中,ResNeXt的第1、2层的卷积核个数的都是ResNet中对应block层数的2倍。
工程目录
1 | ├── Test5_resnext |
model.py
修改Bottleneck类
在初始化函数中参数传递加入groups和width_per_group
- groups:分组数(例如上图中的32)
- width_per_group:(例如上图conv2中的4:指每个group中卷积核的个数)
1 | def __init__(self, in_channel, out_channel, stride=1, downsample=None, |
其中:当group和width_per_group采用默认值时,width输出值为out_channel。当采用ResNeXt结构时,以conv2为例,groups= 32,width_per_group = 128,则width = ( 4 * ( 128 / 64 ))* 32 = 256。
因此本句代码意义为在ResNeXt结构中,输出特征矩阵的channel是输入特征矩阵channel的2倍,因此可以通过本条语句,得出ResNet和ResNeXt网络结构在block中第1,2层卷积层所采用的卷积核的个数。
1 | width = int(out_channel * (width_per_group / 64.)) * groups |
注意:在conv3中的out_channels=out_channel*self.expansion,以conv2为例,上一层out_channels = 64,因此在本语句中总体依旧是输出特征矩阵是上一层(block上一层)的4倍。
1 | self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion, |
实例化Bottleneck
ResNet网络结构
1 | def resnet50(num_classes=1000, include_top=True): |
ResNeXt网络结构
1 | def resnext50_32x4d(num_classes=1000, include_top=True): |
修改ResNet类
初始化函数及_make_layer函数的参数传递加入groups和width_per_group
1 | class ResNet(nn.Module): |
train.py
修改调用model.py函数
1 | from model import resnext50_32x4d |
修改调用迁移学习权重路径
1 | model_weight_path = "./resnext50_32x4d.pth" |
另:因为机器撑不住,所以我这把batch_size改为4
1 | train_loader = torch.utils.data.DataLoader(train_dataset, |
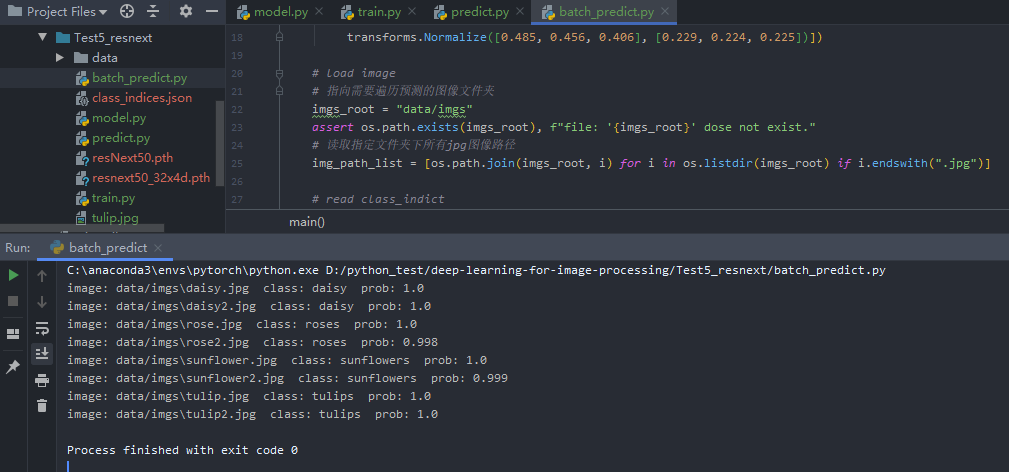
训练结果
predict.py
修改调用model.py函数
1 | from model import resnext50_32x4d |
修改使用权重路径(train.py中通过迁移学习产生的权重pth文件)
1 | weights_path = "./resNext50.pth" |
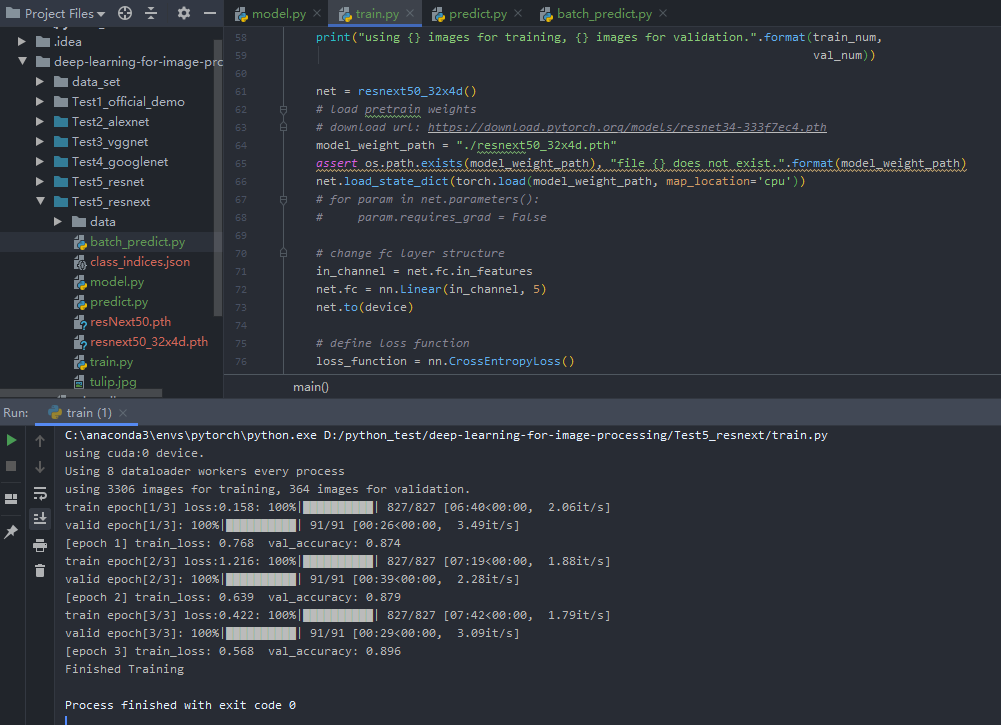
预测结果
批量预测batch_predict.py
1 | import os |
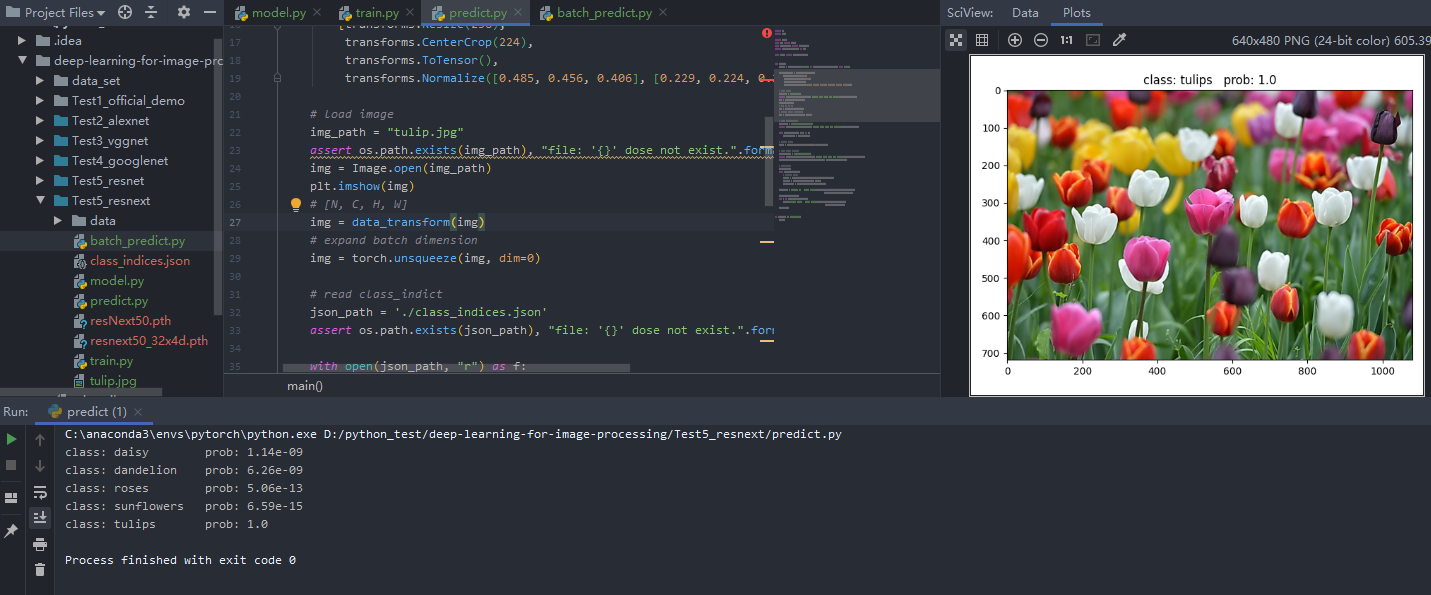
批量预测结果