深度学习模型之CNN(十)使用pytorch搭建ResNet并基于迁移学习训练
工程目录
1 | ├── Test5_resnet |
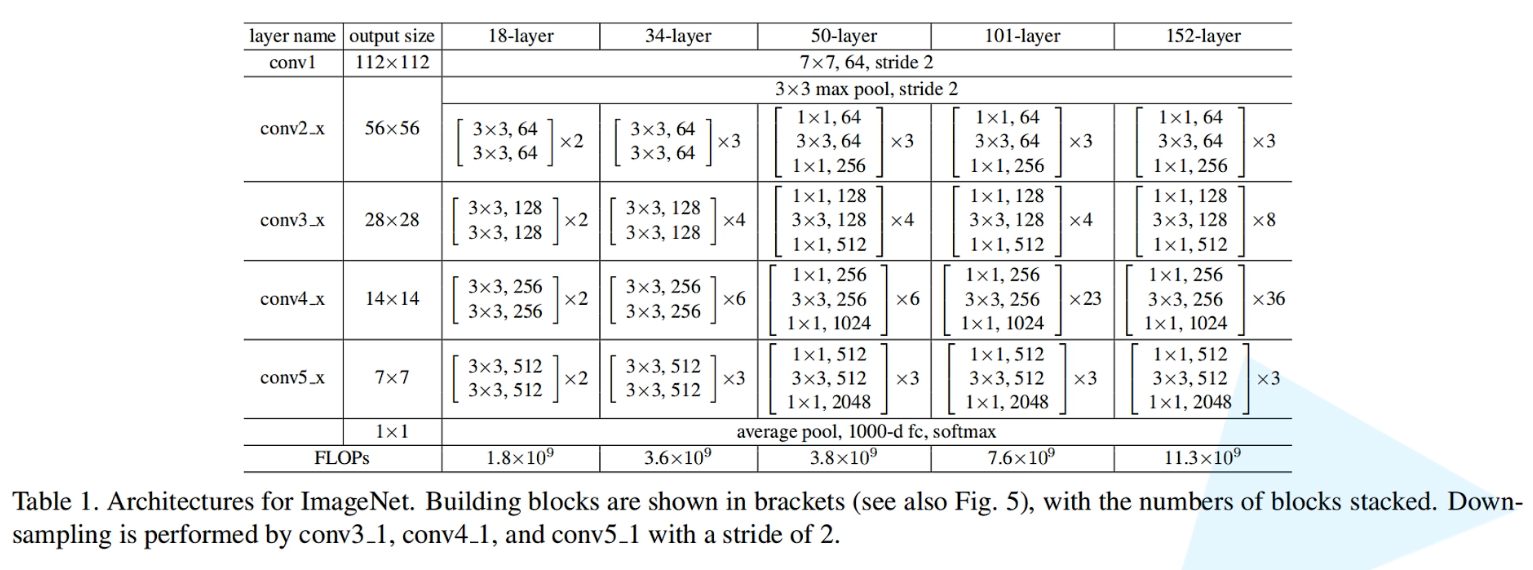
原论文中分别对应18、34、50、101、152层的网络结构参数一览表
model.py
1 | import torch.nn as nn |
对应18、34层的残差结构
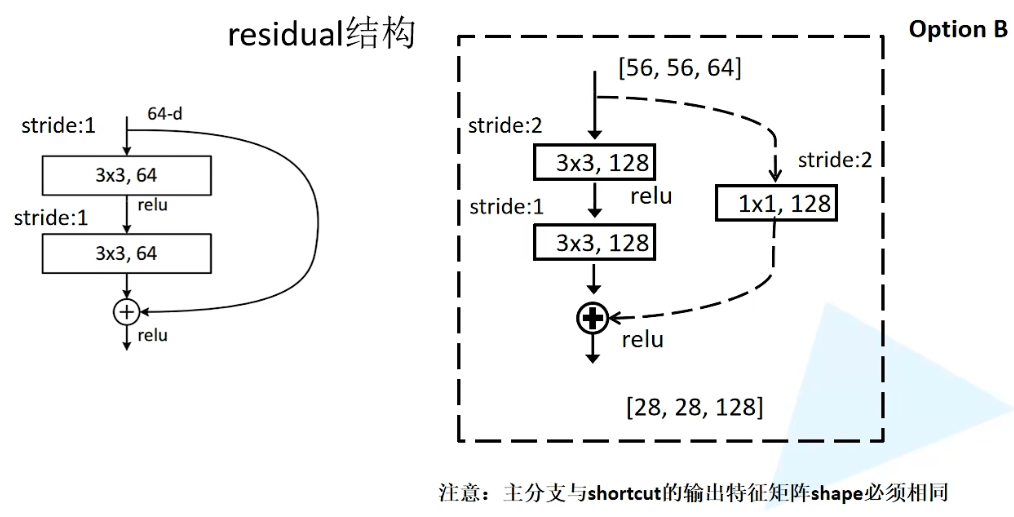
首先定义一个类BasicBlock,对应着18层和34层所对应的残差结构,继承来自于nn.Module父类。包含实线与虚线残差结构的功能,依靠初始化函数中downsample参数进行分辨
1 | class BasicBlock(nn.Module): |
expansion参数对应着残差结构中,主分支所采用的卷积核的个数是否发生变化。例如图上(左)显示,其输入特征矩阵和输出特征矩阵的shape是一致的,因此由expansion = 1来表示卷积核的个数并没有发生变化,也就是1倍。
在之后搭建第50、101、152层的残差结构时,会发现输出特征矩阵的深度是输入特征矩阵的4倍,也就是说,残差结构中,第三层的卷积核个数是第一、二层的四倍,因此expansion = 4。
1 | expansion = 1 |
定义初始函数
下采样参数downsample默认为none,所对应着虚线残差结构中的shortcut的1 x 1的卷积层。作用是对上一层的输出进行维度上的缩放,保证shortcut和本层的输出能够在同一维度上合并
1 | def __init__(self, in_channel, out_channel, stride=1, downsample=None): |
conv1–out_channels
- output_size = (input_size - 3 + 2 * 1 )/ 1 + 1 = input_size( shape保持不变)
- 当stride = 2时,对应的是虚线残差结构:output_size = (input_size - 3 + 2 * 1)/ 2 + 1 = input_size / 2 + 0.5 = input_size / 2(向下取整)
conv1–bias
- bias=False,代表不使用bias参数,在上堂课中说明,使用Batch Normalization时,使用或者不使用bias的效果是一样的
bn1–out_channel
- Batch Normalization:所输入的参数是对着应输入特征矩阵的深度,也就是对应着卷积层1输出特征矩阵的深度,也就是out_channel
1 | self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, |
正向传播函数
- identity = x:将x赋值给identity,也就是shortcut上的输出值
- 对下采样函数downsample进行判断,如果是None(没有输入下采样函数),则表示shortcut是实线,则可以跳过这部分,反之将输入特征矩阵x输入下采样函数downsample,得到shortcut函数的输出
1 | def forward(self, x): |
对应50、101、152层残差结构
.png)
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,这么做的好处是能够在top1上提升大概0.5%的准确率。可参考Resnet v1.5
1 | class Bottleneck(nn.Module): |
在搭建第50、101、152层的残差结构时,会发现输出特征矩阵的深度是输入特征矩阵的4倍,也就是说,残差结构中,第三层的卷积核个数是第一、二层的四倍,因此expansion = 4。
1 | expansion = 4 |
定义初始函数
1 | def __init__(self, in_channel, out_channel, stride=1, downsample=None): |
**conv1:**output_size = (input_size - 1 + 2 * 0 )/ 1 + 1 = input_size( shape保持不变)
1 | self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, |
conv2:
实线:stride默认=1,output_size = (input_size - 3 + 2 * 1 )/ 1 + 1 = input_size + 0.5 = input_size ( shape保持不变)虚线:stride = 2,由参数传入,output_size = (input_size - 3 + 2 * 1 )/ 2 + 1 = input_size / 2 + 0.5 = input_size / 2
1 | self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, |
conv3:
- output_size = (input_size - 1 + 2 * 0 )/ 1 + 1 = input_size (高宽不变)
- out_channels=out_channel * self.expansion:表示深度变为上一层输出特征矩阵深度的4倍(self.expansion = 4)
1 | self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion, |
正向传播函数
identity = x:将x赋值给identity,也就是shortcut上的输出值
对下采样函数downsample进行判断,如果是None(没有输入下采样函数),则表示shortcut是实线,则可以跳过这部分,反之则对应虚线的残差结构,将输入特征矩阵x输入下采样函数downsample,得到shortcut函数的输出
1 | def forward(self, x): |
ResNet网络框架
在初始化函数当中,传入的block就是对应的残差结构,会根据定义的层结构传入不同的block,例如传入是18、34层的残差结构,那么就是BasicBlock,如果传入的是50、101、152层的残差结构,那么就是Bottleneck;
blocks_num:传入的是一个列表类型,对应的是使用残差结构的数目。例如对应使用34层的残差结构,那么根据参数表来看,blocks_num = [ 3, 4, 6, 3 ];对于101层就是[ 3, 4, 23, 3 ]
include_top:是为了方便以后能在ResNet网络基础上搭建更加复杂的网络,本节课并没有使用到,但代码中实现了该方法
1 | class ResNet(nn.Module): |
定义初始函数
1 | def __init__(self, block, blocks_num, num_classes=1000, include_top=True ): |
根据参数表,无论在哪一个层结构下,在经过Maxpooling下采样层之后,输出特征矩阵的深度都为64
1 | self.in_channel = 64 |
conv1:首先输入的是RGB彩色图像,因此先输入3。对应参数表中7x7的卷积层,特征矩阵深度还是64,没有发生变化,为了使特征矩阵的高和宽缩减为原来的一半,因此kernel_size = 7,padding = 3, stride = 2。
output_size = ( input_size - 7 + 2 * 3 )/ 2 + 1 = input_size / 2 + 0.5 = intput_size / 2(向下取整)
1 | self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, |
maxpool:kernel_size = 3, 特征矩阵深度还是64,为了使特征矩阵的高和宽缩减为原来的一半,因此pading = 1,stride = 2
output_size = ( input_size - 3 + 2 * 1 )/ 2 + 1 = input_size / 2 + 0.5 = intput_size / 2(向下取整)
1 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) |
接下来定义layer1、layer2、layer3、layer4
其中layer1对应的是参数表中conv2所对应的一系列残差结构;layer2对应的是vonv3所对应的一系列残差结构;layer3对应是conv4;layer4对应conv5。这一系列layer是通过_make_layer函数生成的
1 | self.layer1 = self._make_layer(block, 64, blocks_num[0]) |
在输入时已经将include_top默认为True,通过自适应的平均池化下采样操作AdaptiveAvgPool2d,无论输入特征矩阵的高和宽是多少,都会以(1, 1)的形式,输出高和宽为1的特征矩阵。
再通过全连接层,也就是输出节点层,通过nn.Linear类进行定义。输入的节点个数,也就是通过平均池化下采样层之后所得到特征矩阵展平后的节点个数。由于通过平均池化下采样之后得到的特征矩阵的高和宽都是1,那么展平后的节点个数即特征矩阵的深度。
对于18、34层而言,通过conv5.x经过一系列残差结构输出的特征矩阵的深度为512,所以输入数据为512 * block.expansion,block.expansion = 1;
对于50、101、152层来说,通过conv5.x经过一系列残差结构输出的特征矩阵的深度为2048,也就是512的4倍,正好此时block.expansion = 4。
1 | if self.include_top: |
最后对卷积层进行初始化操作
1 | for m in self.modules(): |
_make_layer函数
block:对应的是BasicBlock(18、34层)或者Bottleneck(50、101、152层)
channel:对应的是残差结构中卷积层所使用卷积核的个数,例如layer1对应的是conv2.1中卷积核的个数64,layer2对应的是conv3.1卷积核的个数128,layer3对应conv4.1卷积核个数是256,layer4对应conv5.1卷积核个数是512
block_num:表示该层一共包含多少个残差结构,例如在34层残差机构当中,conv2.x中一共包含3个,conv3.x包含4个,conv4.x包含6个,conv5.x包含3个
1 | def _make_layer(self, block, channel, block_num, stride=1): |
18、34层的网络结构会跳过该判断语句,50、101、152层的网络结构会执行该判断下的语句,即生成下采样函数downsample。
在layer1中,因没有输入stride,所以默认stride = 1,因此判断语句前半段不成立。in_channel判断是否等于channel * block.expansion。当在18、34层残差结构时,由于block.expansion = 1,而channel对应layer1中输入为64,所以二者相等,判断失效。
1 | if stride != 1 or self.in_channel != channel * block.expansion: |
首先定义layers的列表,block对应的是BasicBlock(18、34层)或者Bottleneck(50、101、152层)。等于是将网络结构中虚线残差结构的conv2.1、conv3.1、conv4.1、conv5.1的输出特征矩阵以列表的形式存放在layers列表中,在本次循环中存放进的是conv2.1。
1 | layers = [] |
以循环的方式将实线残差结构依次存放仅layers列表中。range(1, block_num)中从1开始,因为上面的步骤已经将0做好了。
1 | for _ in range(1, block_num): |
结合以上对layer1的过程描述,_make_layer函数实际上是将conv2.x、conv3.x、conv4.x、conv5.x每一层中虚线和实线对应的特征矩阵存放进对应的layers列表中。例如50层的conv2.x,layer1对应是[ 虚线,实线,实线 ]。
正向传播函数
1 | def forward(self, x): |
定义ResNet网络架构的函数
1 | # 18层 |
train.py
1 | import os |
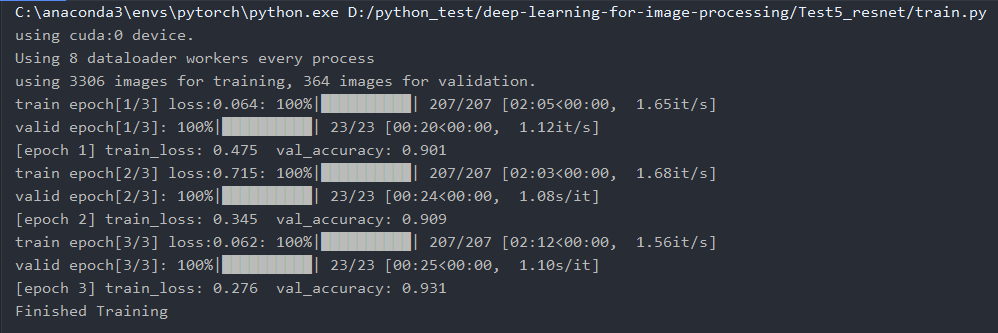
训练结果(迁移学习),准确率最终能达到93%
如果不想使用迁移学习的方法,可以将以下代码注释
1 | model_weight_path = "./resnet34-pre.pth" |
并将传入resnet实例化参数的地方net = resnet34()传入num_classes = 5
predict.py
1 | import os |
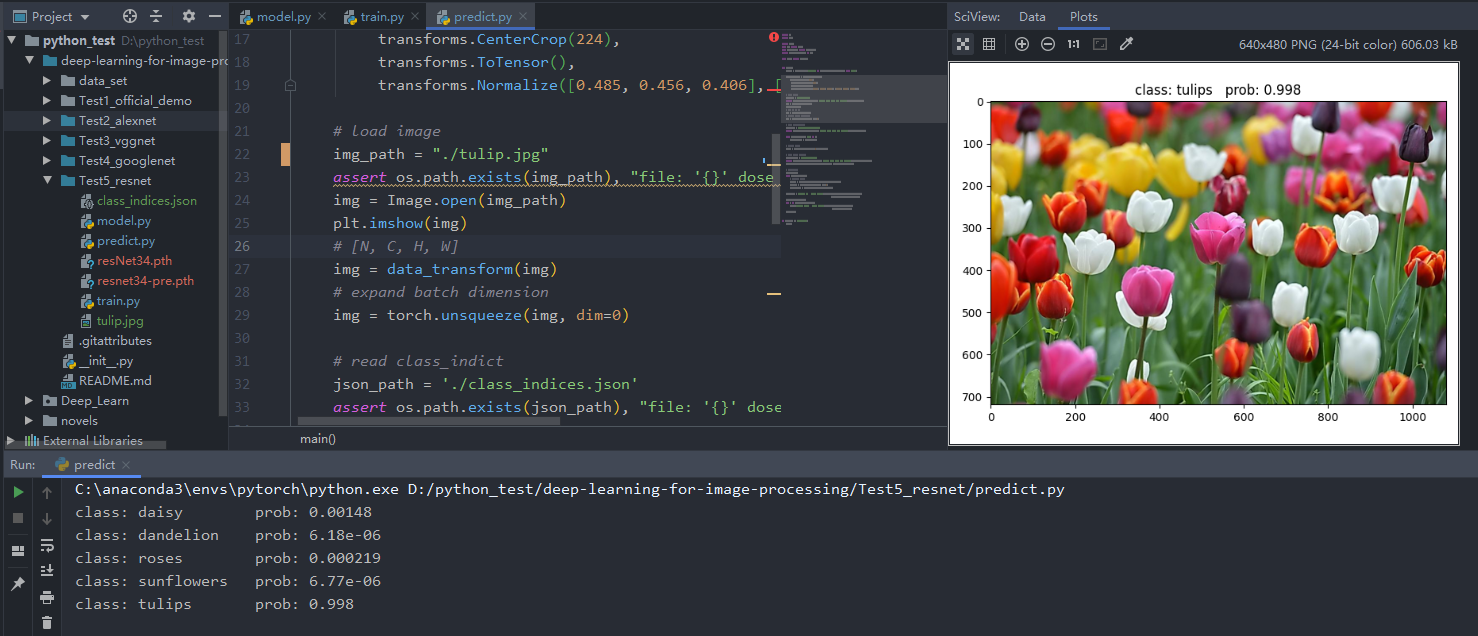
预测结果(迁移学习)