深度学习模型之CNN(九)ResNet网络结构、BN以及迁移学习详解
ResNet详解
ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名(超级NB)。原论文:Deep Residual Learning for Image Recognition

网络中的创新点
- 超深的网络结构(突破1000层)
- 提出residual模块(残差模块,因为有了残差模块,才能够搭建层数很深的网络)
- 使用Batch Normalization加速训练(丢弃dropout)
卷积层和池化层不断叠加是否都会导致准确率不断提高?
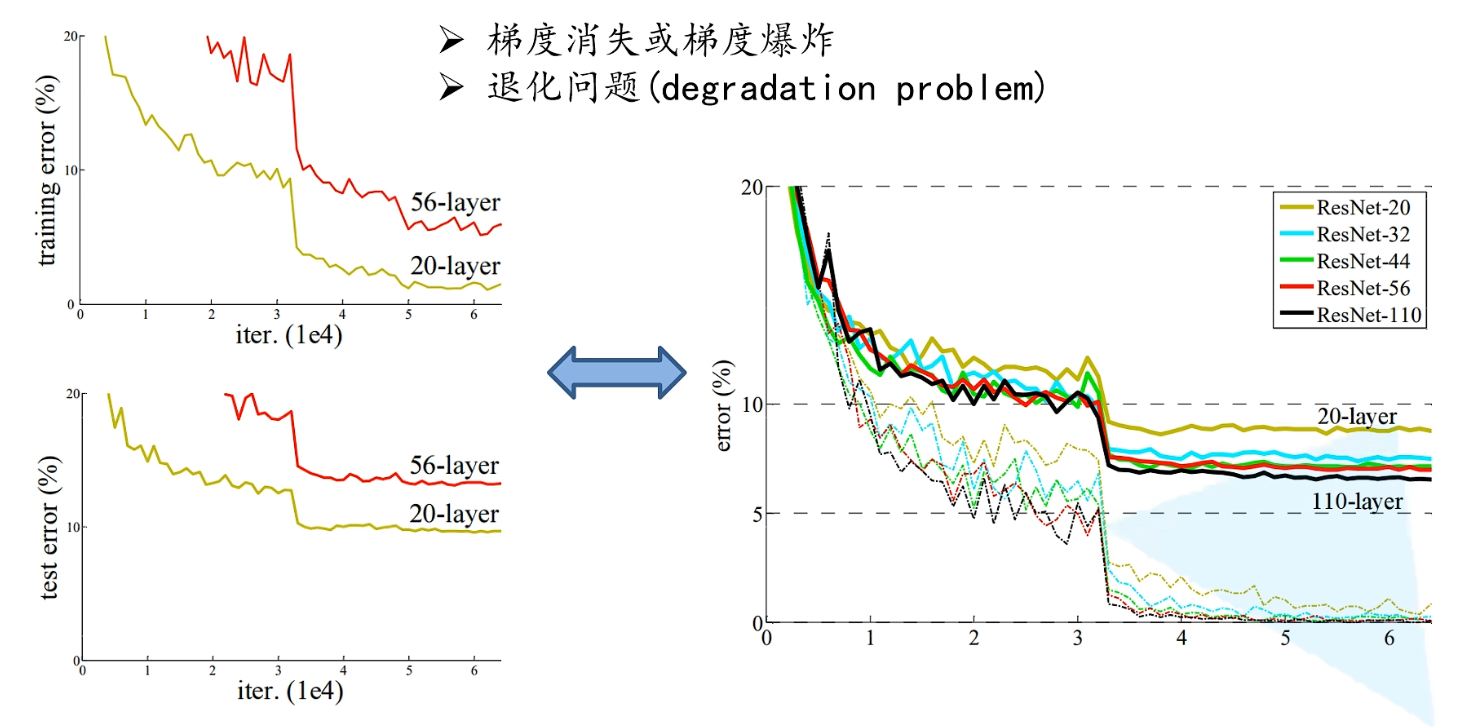
下图(左)通过简单将卷积层和池化层进行堆叠所搭建的网络结构,橙黄色曲线表示20层的网络结构,最终的训练错误率在[1%, 2%],红色区县表示56层网络结构,最终的训练错误率在[7%, 8%],很明显,当仅仅通过简单的把卷积层和最大池化下采样层堆叠网络,并不代表层数越深效果越好。
那么是什么原因导致更深的网络造成效果越差呢?
在ResNet论文中,作者给出以下两个结论:
- 梯度消失或梯度爆炸
- 退化问题(degradation problem)
梯度消失或梯度爆炸
随着网络层级越来越深,梯度消失或梯度爆炸的现象会越来越明显。
假设每一层误差梯度小于1,那么在反向传播过程中,每向前传播一次,都要乘以这个小于1的系数。当网络越来越深的时候,所乘的小于1的系数越多,那么这个数越趋近于0,梯度就会越来越小,这就是所说的梯度消失现象。
反过来,当每一层误差梯度是一个大于1的数,那么在反向传播过程中,每向前传播一次,都要乘以这个大于1的系数。当网络越来越深的时候,梯度就会越来越大,这就是所说的梯度爆炸现象。
如何解决梯度消失/爆炸:通常对数据进行标准化处理、权重初始化、以及这堂课将会讲述的Batch Normalization标准化处理来解决
退化问题
在解决了梯度消失或梯度爆炸的问题之后,可能仍然会出现层数深的没有层数小的效果好的问题。也就是网络越深反而识别错误率提高的现象。
那该如何来解决提到的退化问题呢?
在ResNet论文当中,作者提到一个名为残差的结构,通过残差结构,即能解决退化问题
上图(右)就是在原论文中所搭建的一系列网络,里面有20、32、44、56、110层的网络。其中实线代表验证集的错误率变化情况,虚线代表测试集的错误率变化情况(主要看验证集中的错误率)
在图中,随着层数的加深,错误率越小,效果越好。对比图左,ResNet确实解决了文中所提到的退化问题,因此,我们即可以使用文中提到的残差结构来不断加深网络,以获得更好的结果
residual模块(残差结构)
图形结构对比
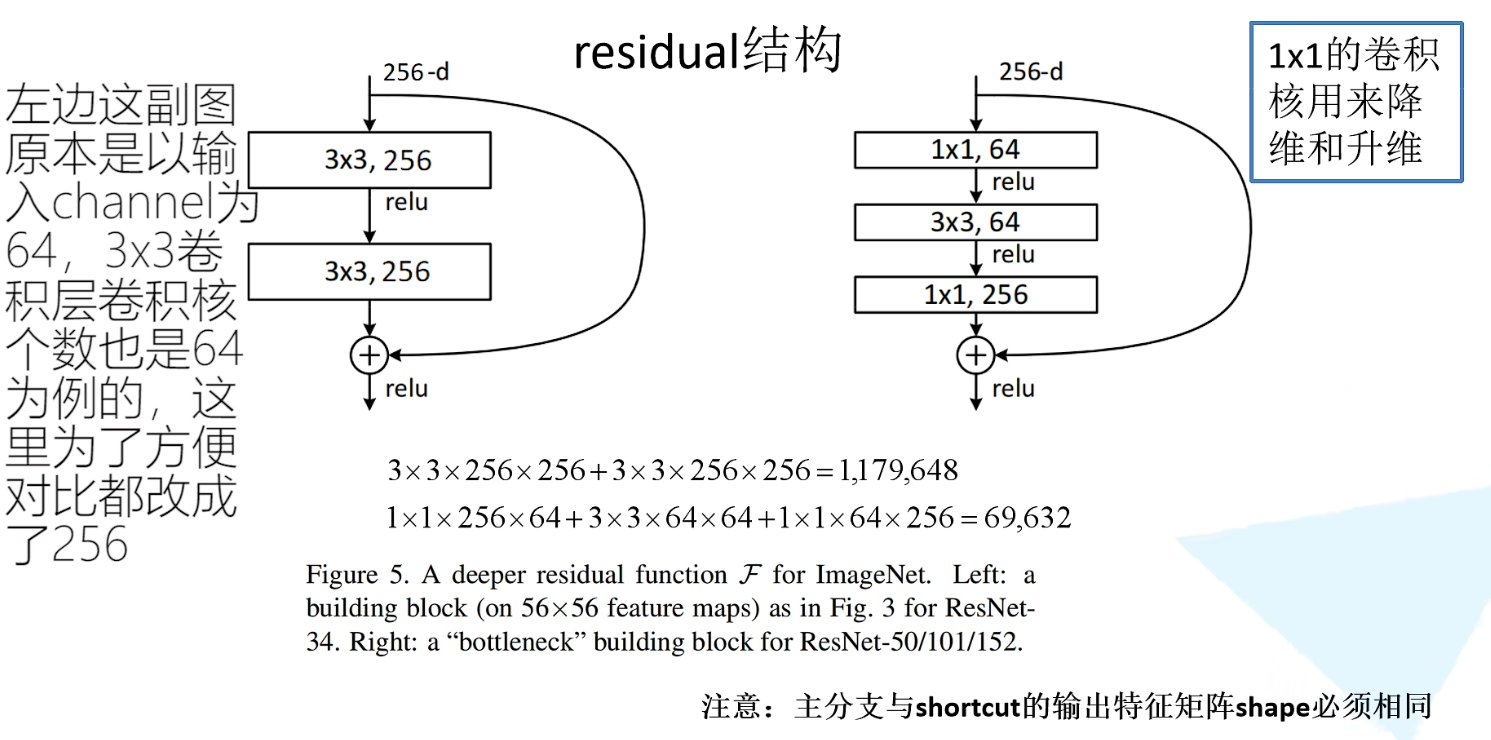
图中代表着两种不同的残差结构,左边的结构主要针对网络层数较少的结构,对应的是32层的网络结构;右边的结构对应的是50、101、152层的网络结构。
左边结构的主分支,将输入特征矩阵通过2个3×3的卷积层得到结果,右边有一个弧线,直接从输入连接到输出,并在输出点有个+符号。意思是:在主分支上通过一系列卷积层之后所得到的特征矩阵,再与输入特征矩阵进行相加,相加之后再通过ReLU激活函数。且在主分支上,第一次卷积层之后通过ReLU激活函数激活,但第二层是在与输入特征矩阵相加之后,再通过ReLU激活函数激活的。
注意:主分支与侧分支(shortcut)的输出特征矩阵中shape必须相同
右边结构的主分支,将输入特征矩阵先通过1×1卷积层,再通过3×3的卷积层,最后通过1×1的卷积层之后,与侧分支的输入特征矩阵进行相加,最终得出结果。
相比左边的结构,是在输入及输出分别加入一个1×1的卷积层,目的是用来降维和升维
在结构中,输入深度为256的特征矩阵,通过1×1卷积层,高宽不变,深度由256变为64,因此第一个卷积层是起到降维的作用。再通过一个3×3卷积层,之后再经过1×1卷积层,高宽不变,深度由64变为256,因此这一个卷积层是起到升维的作用。
使用参数对比
左侧residual结构所需参数:3 × 3 × 256 × 256 + 3 × 3 × 256 × 256 = 1,179,648
右侧residual结构所需参数:1 × 1 × 256 × 64 + 3 × 3 × 64 × 64 + 1 × 1 × 64 × 256 = 69,632
使用的残差结构越多,减少的参数也就越多
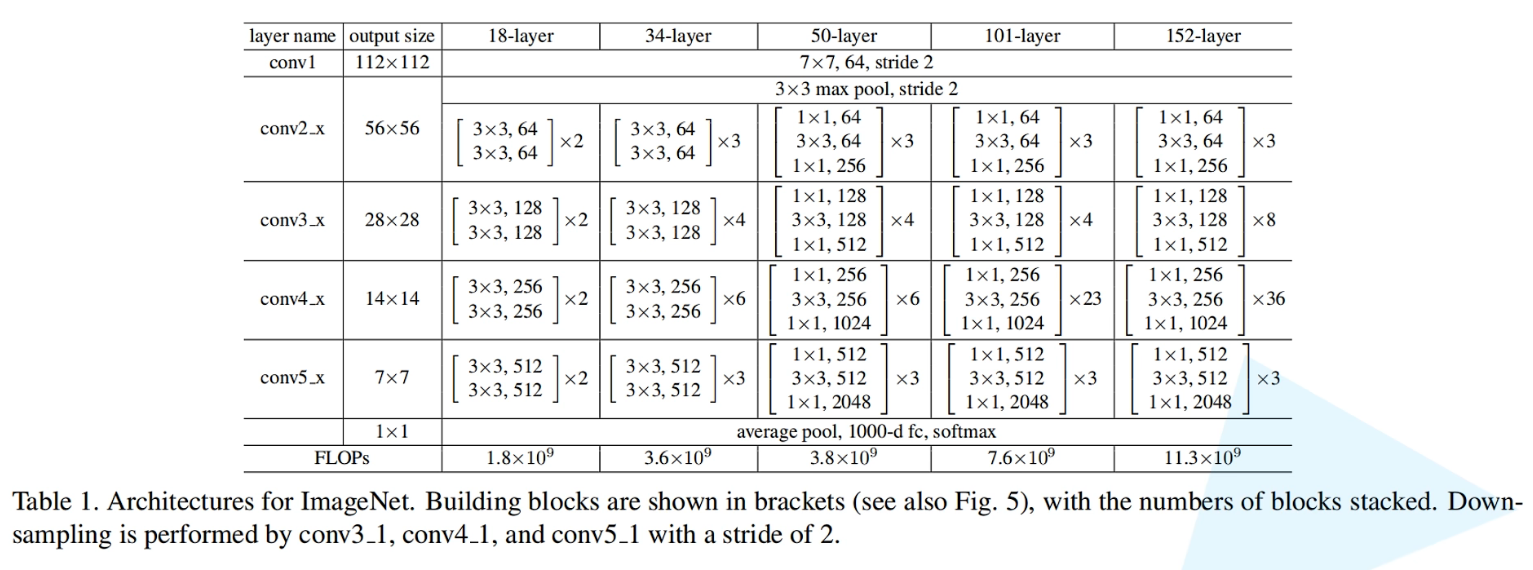
上图是原论文给出的不同深度的ResNet网络结构配置,代表着在不同层数下的参数列表,所对应的是18、34、50、101、152层的网络结构。注意表中的残差结构给出了主分支上卷积核的大小与卷积核个数,表中 残差块×N 表示将该残差结构重复N次。
图中显示,这几个网络框架是一致的,同样是通过1个7X7的卷积层,再通过3X3的最大池化下采样层,再分别通过一系列残差结构,最后再接1个平均池化下采样层以及全连接层输出,softmax将输出转化为概率分布。
降维时的shortcut
34层残差结构
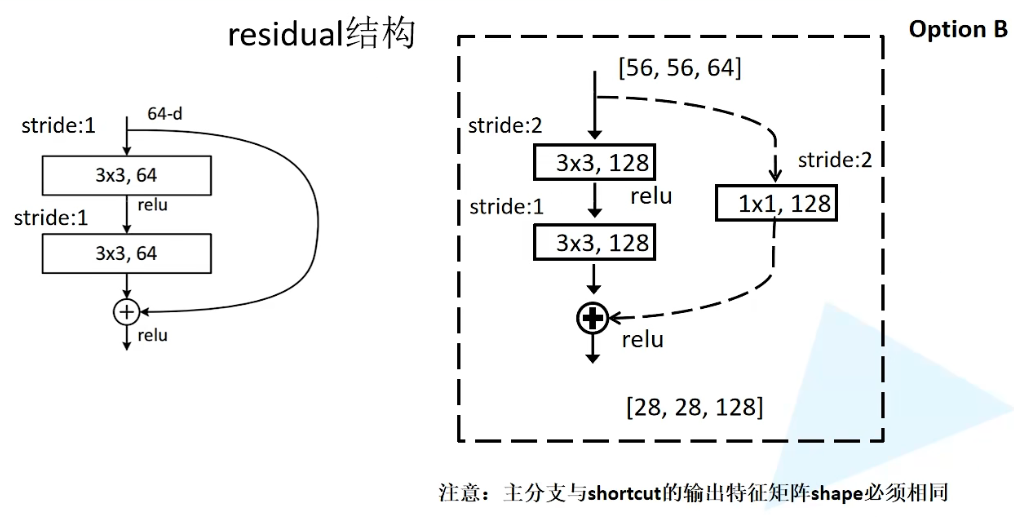
经过对 ResNet34层网络的观察,可以发现有些残差块的shortcut是实线的,而有些则是虚线的。这二者间有什么区别呢?
对于上图左两层3X3卷积层的残差结构来说,输入特征矩阵深度和输出特征矩阵的shape是一致的,所以能够直接进行相加。但是对于上图右虚线的残差结构来说,其输入和输出的shape是不一致的。
上图右对应到参数表中,是ResNet-34层conv3.x第一层,输入特征矩阵shape是[56, 56, 64],输出特征矩阵shape是[28, 28, 128]
只有通过虚线残差结构,得到输出之后输入到实线对应的残差结构当中,才能够保证输入特征矩阵和输出特征矩阵的shape保持一致。
更高层的残差结构
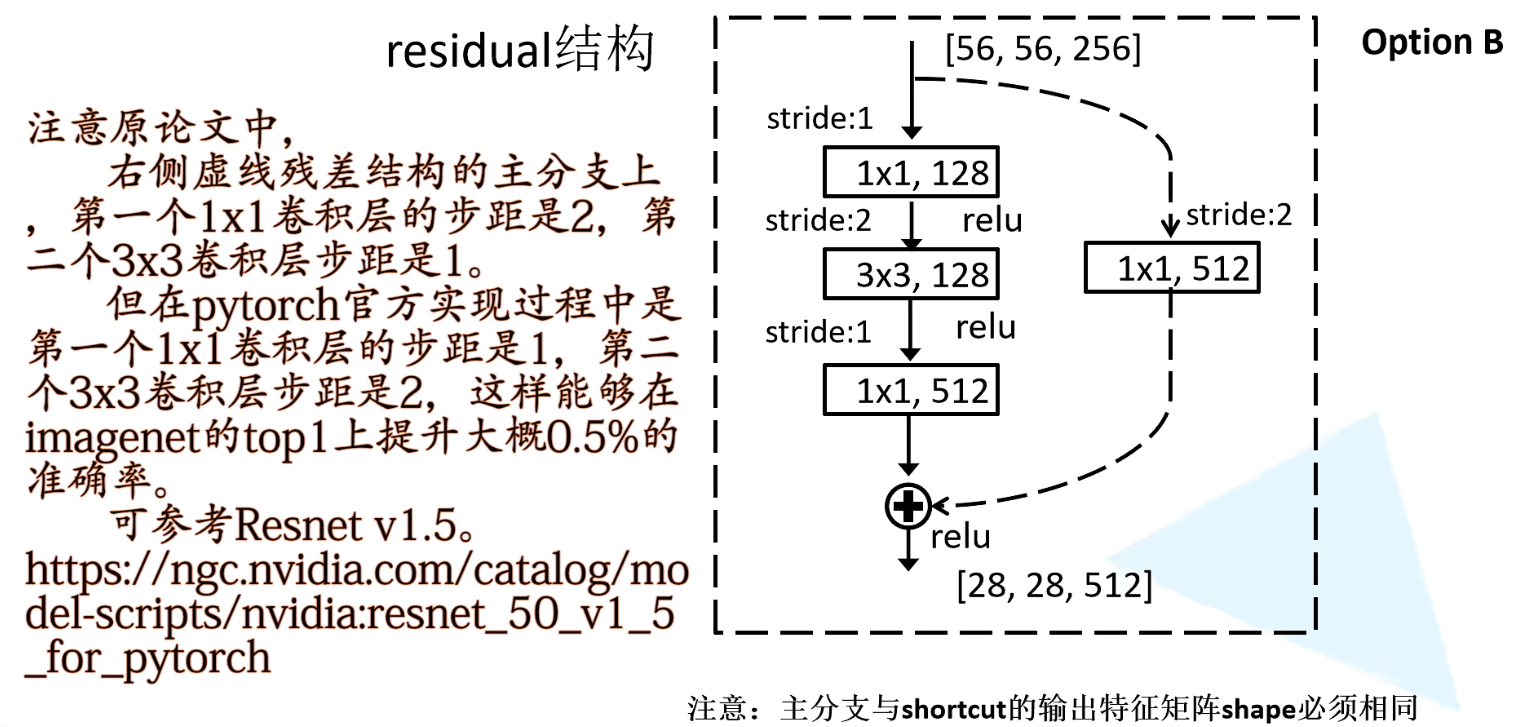
上图右虚线对应的参数,也就是参数表中conv3.x对应的一系列残差结构:50,101,152层。输入特征矩阵的shape是[56, 56, 256],输出特征矩阵的shape是[28, 28, 512]
对于主分支而言,stride=1,所以第一层1X1卷积层只起到降维的作用,不改变高宽,将深度从256改为128;在第二层stride=2,( 56 - 3 + 1 )/ 2 + 1 = 28,所以第二层3X3卷积层将特征矩阵的高宽缩减为原本的一半,深度不变;第三层stride=1,所以第三层1X1卷积层只起到升维的作用,不改变高宽,将深度从128升到512。
对于shortcut分支,仅使用1X1,深度为512,stride = 2的卷积层对输入特征矩阵起到升维且改变高宽的目的。深度1X1,将深度从256改为512;stride = 2,将输入特征矩阵高宽56,改为28。
$$
N = ( W-F+2P )/S+1
$$
原论文中,作者对于残差结构的shortcut有optionA、B、C三个方法,但作者通过一系列对比之后,得出optionB方法效果最好。
由此得知,虚线残差结构有一个额外的作用,就是将输入特征矩阵的shape与输出特征矩阵的shape保持一致(变化高宽深),而在实线中,输入和输出特征矩阵的shape是完全无变化的
所以在参数表中,50层及以上的深层网络结构,conv3、conv4、conv5所对应的一系列残差结构的第一层都是虚线残差结构。因为第一层需要将上一层输出的特征矩阵的高宽深度调整为当前层所需要的特征矩阵的高宽深度。在conv2中,仅仅改变了深度(所以用的还是实线)
Batch Normalization标准化处理
老师博客:Batch Normalization详解以及pytorch实验
Batch Normalization是google团队在2015年论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的。通过该方法能够加速网络的收敛并提升准确率。本文主要分为以下几个部分:
- BN的原理
- 使用pytorch验证本文的观点
- 使用BN需要注意的地方(BN没用好就是个坑)

BN原理
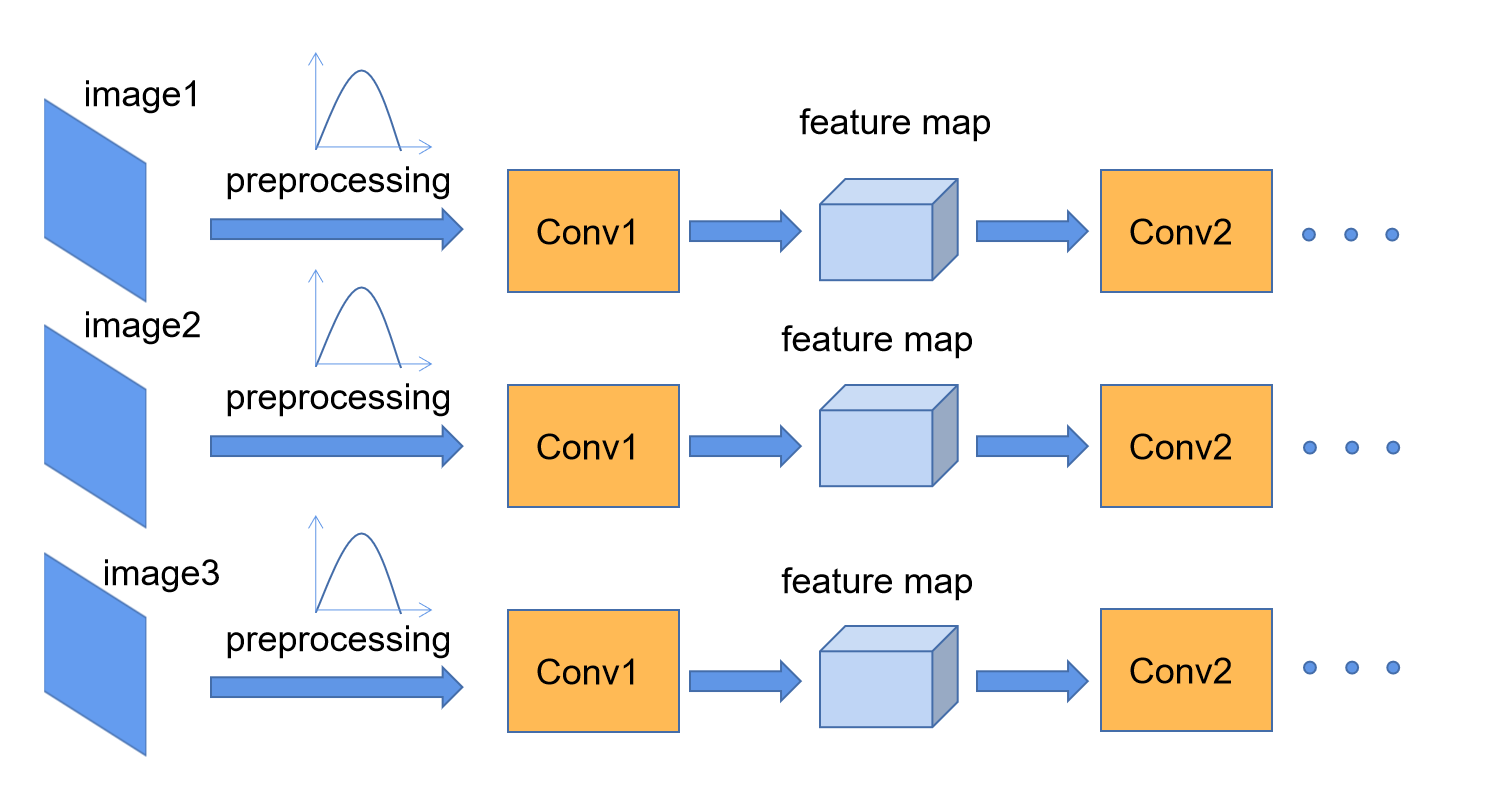
在之前搭建网络过程中,通常第一步会对图像进行标准化处理,也就是将图像数据调整到满足某分布规律,这样能够加速网络的收敛。如下图所示,对于conv1而言,输入的就是经过预处理之后满足某分布规律的特征矩阵,但对于conv2而言,输入的feature map就不一定满足某分布规律了,而Batch Normalization目的即是使feature map满足均值为0,方差为1的分布规律。
注意:Batch Normalization的目的是使我们的一批(Batch)feature map满足均值为0,方差为1 分布规律,并不指某一个feature map
原论文中有一句:“对于一个拥有d维的输入x,我们将对它的每一个维度进行标准化处理。”
假设我们输入的x是RGB三通道的彩色图像,那么这里的d就是输入图像的channels即d=3,$x=(x^{(1)}+x^{(2)}+x^{(3)})$,$x^{(1)}$代表我们的R通道所对应的特征矩阵,依此类推。标准化处理也就是分别对R通道,G通道,B通道进行处理。

γ主要调整数据方差的大小,β主要调整这批数据均值的大小(是否处于中心),如果不通过γ和β进行调整,那么得到的数据是均值为0方差为1的数据分布规律。γ和β是通过反向传播去学习得到的,均值和方差是根据一批批的数据统计得到的
γ初始值为1,β初始值为0
示例如下
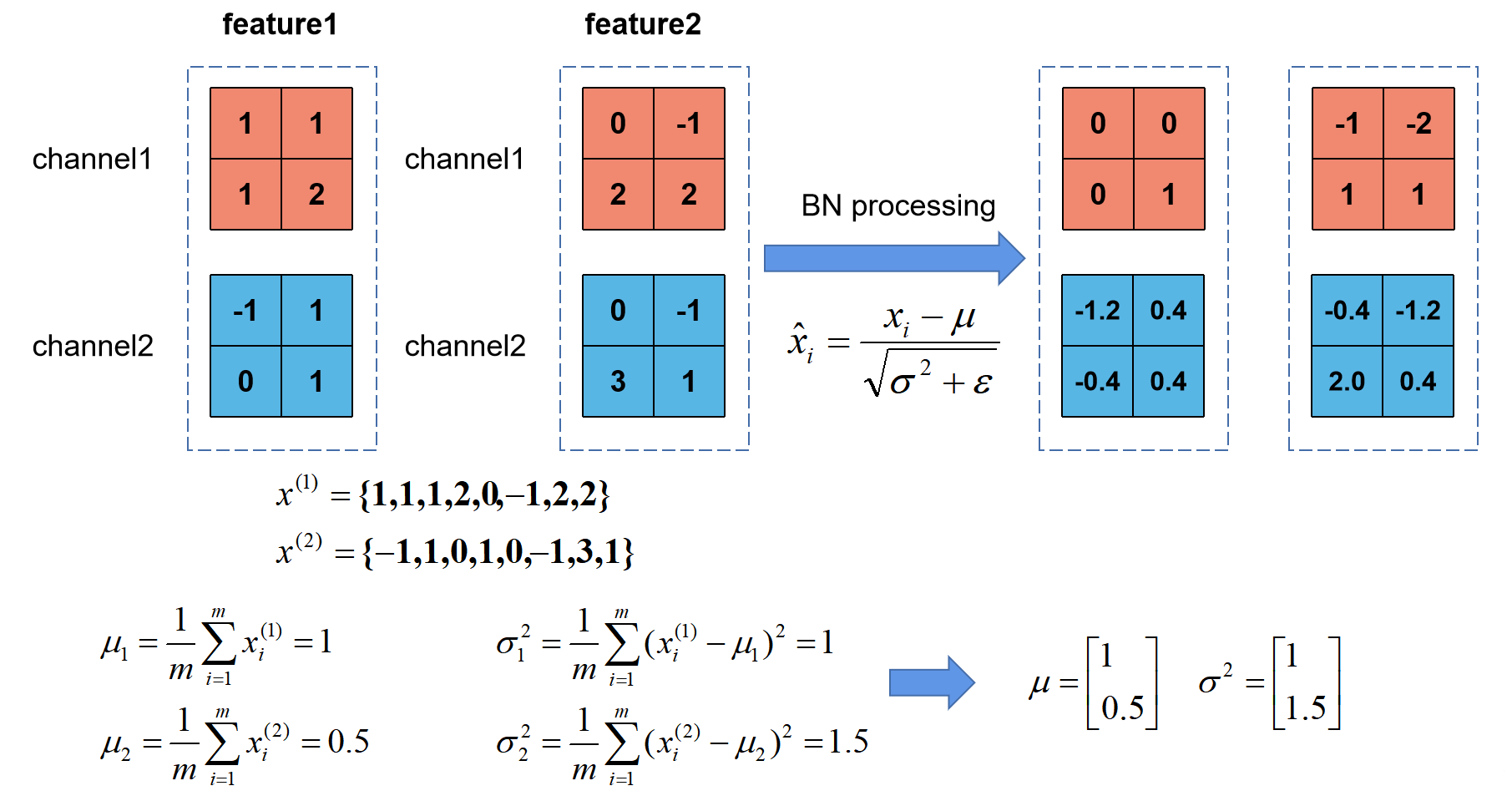
上图展示了一个batch size为2(两张图片)的Batch Normalization的计算过程。
假设feature1、feature2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵,feature的channel为2,那么$x^{(1)}$代表该batch的所有feature的channel1的数据,即$x^{(1)}$={1,1,1,2,0,-1,2,2},$x^{(2)}$同理。
注意:最终所得到的均值和方差是一个向量,其向量的长度即为特征矩阵的深度
使用BN需要注意的问题
-
训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
-
batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
-
建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的$y^b_i=y_i$
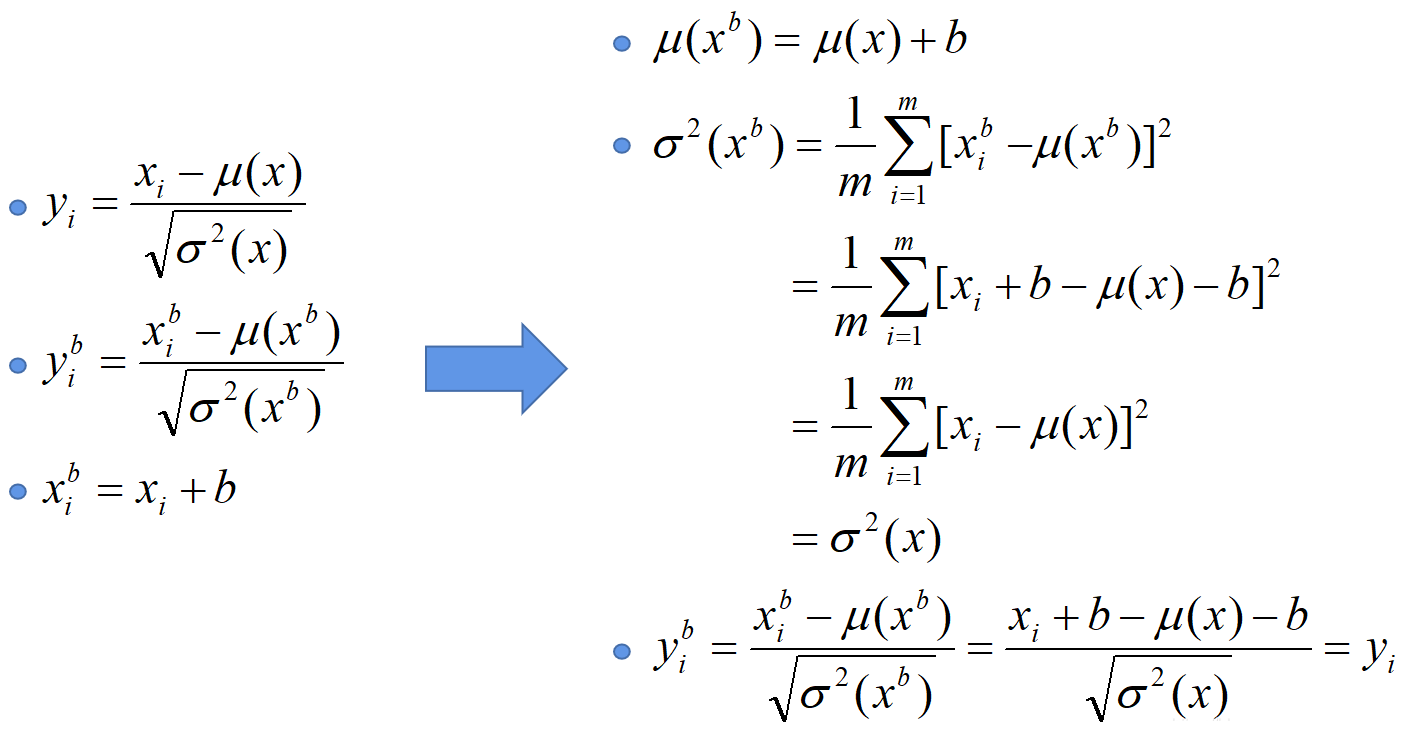
迁移学习简介
迁移学习是一个比较大的领域,我们这里说的迁移学习是指神经网络训练中使用到的迁移学习。
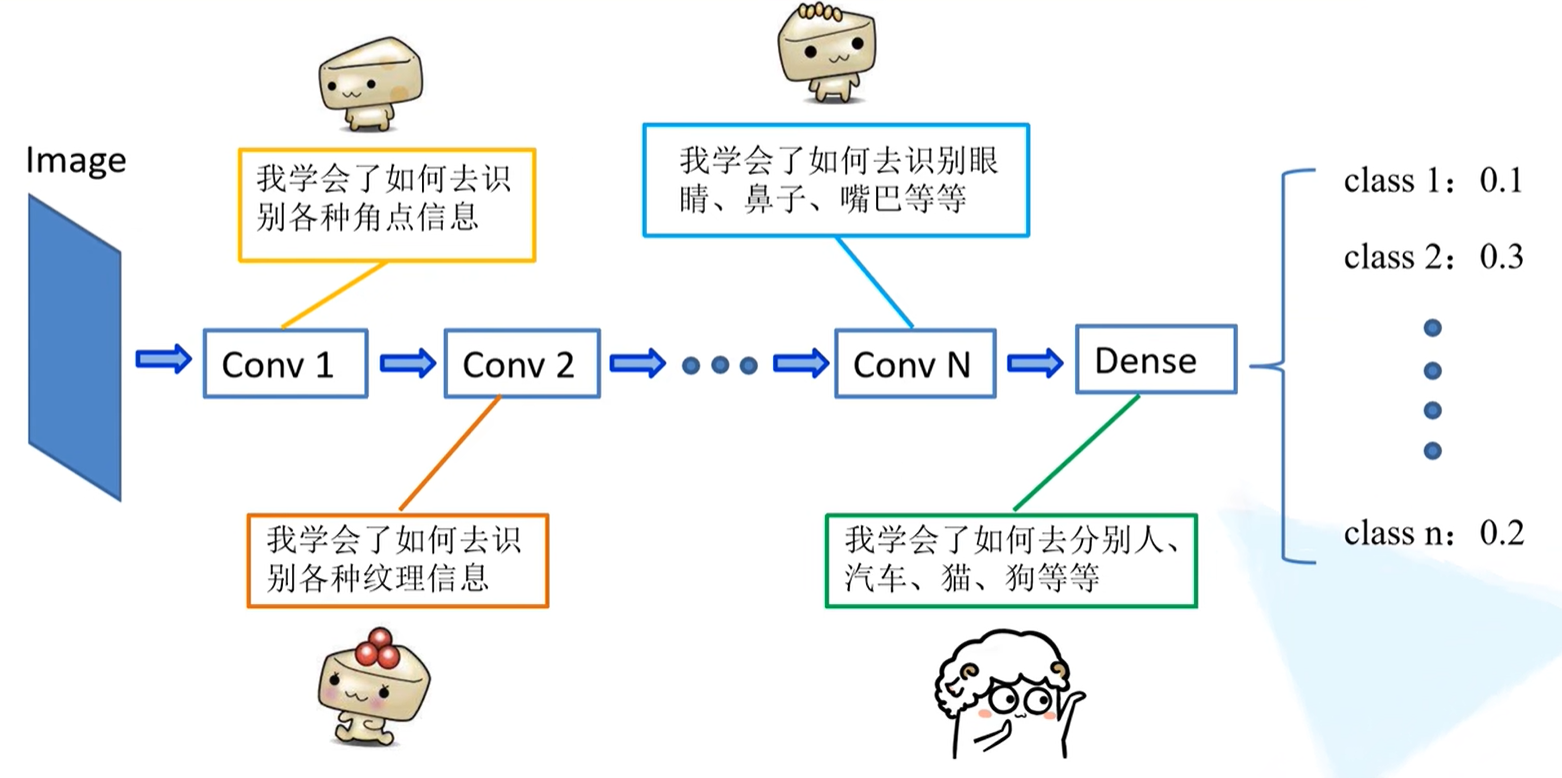
如下图所示,神经网络逐层提取图像的深层信息,这样,预训练网络就相当于一个特征提取器。
迁移学习,即将学习好了的浅层网络的一些参数,迁移到新的网络当中,这一新的网络中也具备识别底层通用特征的能力了。当新网络拥有了底层通用特征检测识别能力之后,就能更快速去学习新的数据集的高维特征。
使用迁移学习的优势
- 能够快速的训练出一个理想的结果
- 当数据集较小时也能训练出理想的效果
注意:使用别人预训练模型参数时,要注意别人的预处理方式
常见的迁移学习方式:
- 载入权重后训练所有参数(准确率最高,需要参数最多,硬件要求最高,时间最长)
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
总结
本节课程讲解ResNet网络结构,针对残差结构做了详细讲解、讲解Batch Normalization标准化处理过程以及迁移学习内容介绍,下节课将会使用pytorch搭建ResNet网络结构。