深度学习模型之CNN(八)使用pytorch搭建GoogLeNet网络
pytorch搭建GoogLeNet
model模型搭建对照以下参数表及网络架构图
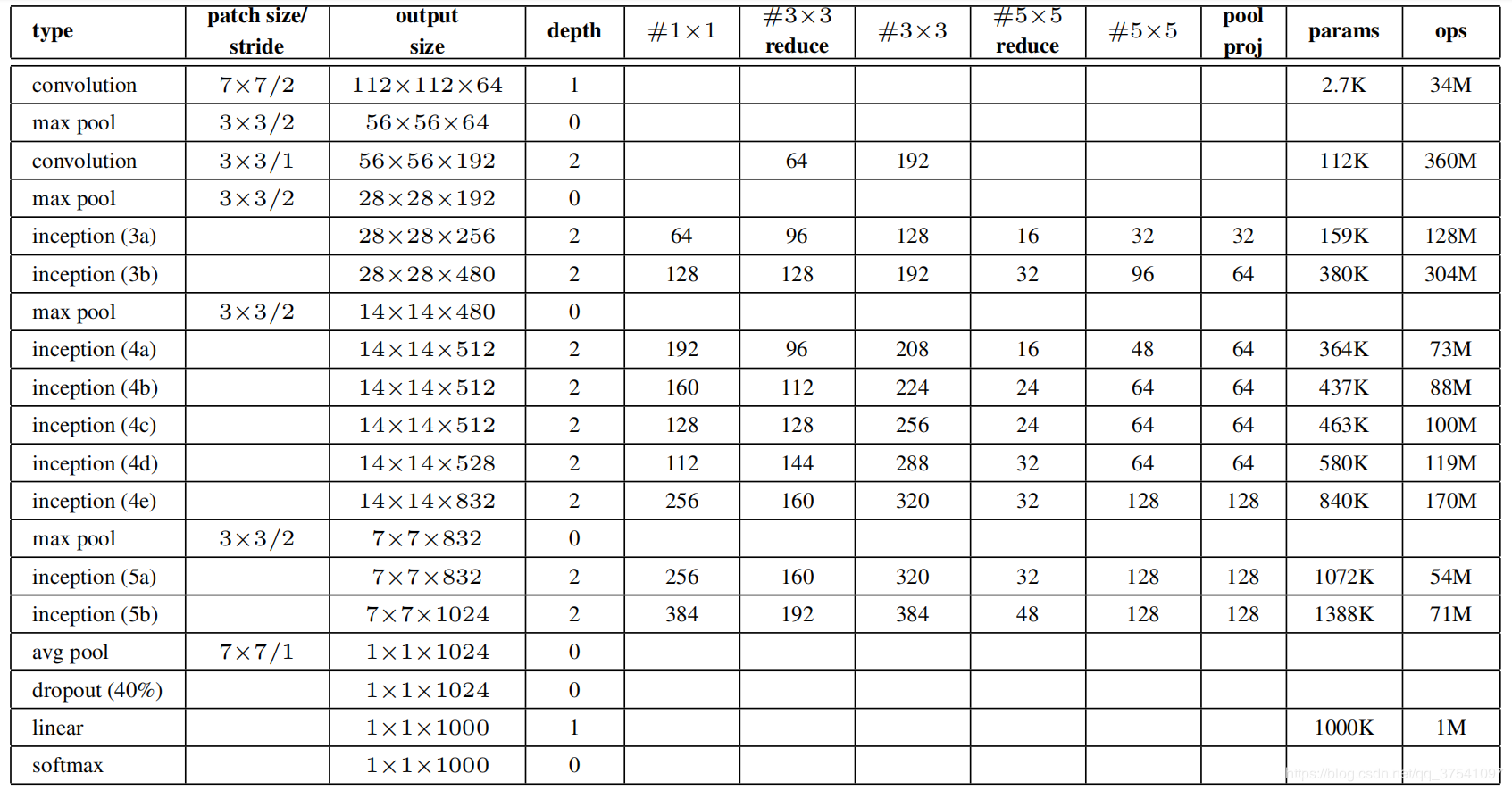
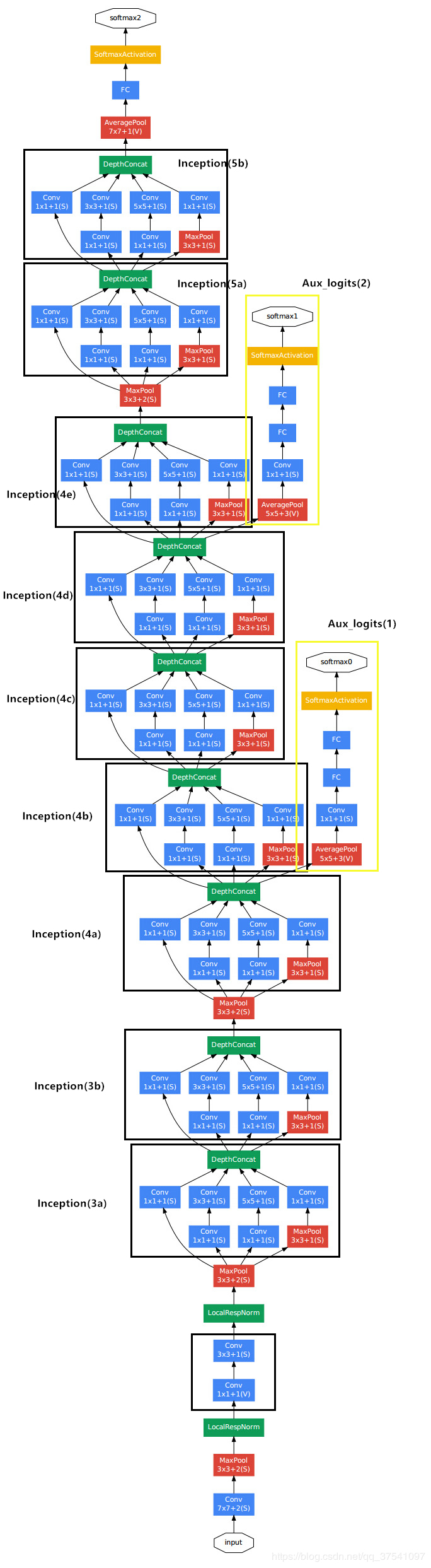
model.py
相比于AlexNet 和 VggNet 只有卷积层和全连接层这两种结构,GoogLeNet多了Inception和辅助分类器(Auxiliary Classifier),而 Inception和辅助分类器也是由多个卷积层和全连接层组合的,因此在定义模型时可以将卷积、Inception 、辅助分类器定义成不同的类,调用时更加方便。
1 | import torch.nn as nn |
BasicConv2d类模板
定义BasicConv2d类,包含了卷积层和ReLU激活函数的卷积模板,继承nn.Module,将卷积层和ReLU激活函数打包在一起
1 | class BasicConv2d(nn.Module): |
Inception类模板
定义Inception类模板,同样继承于nn.Module父类。初始函数中输入Inception函数所需要使用的参数:
in_channels:输入特征矩阵的深度;ch1X1:第一个分支中1X1卷积核的个数;ch3X3red:第二个分支中1X1卷积核的个数;ch3x3:第二个分支中3X3卷积核的个数;ch5x5red:第三个分支中1X1卷积核的个数;ch5x5:第三个分支中5X5卷积核的个数;pool_proj:第四个分支中1X1卷积核的个数
分支1:self.branch1
1 | self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) |
分支2:self.branch2
padding=1:保证输出大小等于输入大小。output_size = (input_size - 3 + 2*1)/1 + 1 = input_size
1 | self.branch2 = nn.Sequential( |
分支3:self.branch3
padding=2:保证输出大小等于输入大小。output_size=(input_size - 5 + 2 * 2) / 1 + 1 = input_size
1 | self.branch3 = nn.Sequential( |
分支4:self.branch4
padding=1:保证输出大小等于输入大小。output_size = (input_size - 3 + 2*1)/1 + 1 = input_size。池化操作不会改变特征矩阵的深度
1 | self.branch4 = nn.Sequential( |
在forward正向传播函数中,将输出放入列表中,再通过torch.cat(concatention)函数对输出进行在深度方向的合并
1 | outputs = [branch1, branch2, branch3, branch4] |
在pytorch中,通道[batch, channel, hight, width],因为延深度方向拼接,因此位置在第1个(0,1,2,3)
1 | return torch.cat(outputs, 1) |
InceptionAux辅助分类器
当实例化一个模型model之后,可以通过model.train()和model.eval()来控制模型的状态,在model.train()模式下self.training=True,在model.eval()模式下self.training=False
1 | x = F.dropout(x, 0.5, training=self.training) |
GoogLeNet类
aux_logits:是否使用辅助分类器;init_weights:是否对权重进行初始化
1 | def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): |
为了将特征矩阵的高宽缩减为原来的一半,(224 - 7 + 2 * 3)/2 + 1 = 112.5在pytorch中默认向下取整,也就是112。当ceil_mode-True,表示结果数据如果为小数的话,那么向上取整,反之向下取整
1 | self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) |
Inception的深度可以用过查看参数表格得到,或通过上一个Inception层的四个分支的特征矩阵深度加起来得到
1 | self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64) |
平均池化下采样层,AdaptiveAvgPool2d自适应平均池化下采样:无论输入特征矩阵高宽是多少,都能得到指定的特征矩阵的高和宽
1 | self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) |
输入的展平后的向量节点个数为1024,输出的节点个数是num_classes
1 | self.fc = nn.Linear(1024, num_classes) |
在forward正向传播函数中,self.training判断当前模型是处于训练模式还是验证模式,如果是训练模式的话九尾True,反之为False
1 | if self.training and self.aux_logits: |
train.py
1 | import os |
train.py代码和前期VGG和AlexNet代码内容大同小异,有两点不同需要注意:
实例化代码
1 | net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True) |
损失函数
有三个部分,分别是主干输出loss、两个辅助分类器输出loss(权重0.3)
1 | logits, aux_logits2, aux_logits1 = net(images.to(device)) |
predict.py
1 | import os |
预测部分跟AlexNet和VGG类似,需要注意在实例化模型时不需要辅助分类器(因为辅助分类器目的在于在训练模型过程中防止过拟合的同时增强模型的正确率,当训练结束后,相关参数已经保存在权重文件中,因此在预测时,并不需要使用辅助分类器)
aux_logits=False不会构建辅助分类器
1 | model = GoogLeNet(num_classes=5, aux_logits=False).to(device) |
strict默认为true,意思是精准匹配当前模型和需要载入的权重模型的结构。当设置为False后,现在搭建的GoogLeNet是没有辅助分类器的,所以于保存的模型结构会缺失一些结构
1 | missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device), strict=False) |
总结
训练过程过于漫长,今后在时间充裕的时候可以试一试