深度学习模型之CNN(六)使用pytorch搭建VGG网络
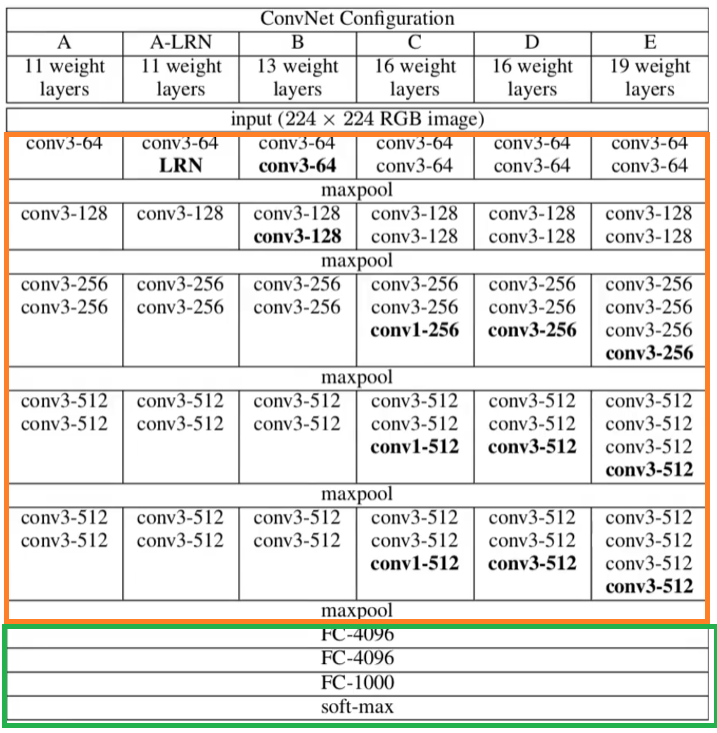
在上堂课讲解了D模型,今次以实操的形式,针对模型A、B、D、E做一个代码的实现。将代码构造分为两部分:提取特征网络结构(图中橙色框)、分类网络结构(图中绿色框)
VGG网络架构
model.py
1 | import torch.nn as nn |
定义一个字典文件,字典中每个key代表着一个模型的配置文件。
- eg:vgg11:对应A配置(模型A),即11层的网络结构(11层指的是卷积层+全连接层的个数);
- vgg13:对应配置B(模型B),即13层网络结构;
- vgg16:对应配置D(模型D),即16层网络结构;
- vgg19:对应配置E(模型E),即19层网络结构;
1 | cfgs = { |
含义解释:eg:vgg11的配置文件,对应的值是一个列表,其中列表的数字代表着卷积层中卷积核的个数,其中的字符M代表的是池化层的结构。
对应着表中配置A的内容,第一层是一个3*3的卷积,有64个卷积核,因此在配置列表中的第一个元素是64;第二层是一个最大池化下采样层,因此配置列表中对应的是一个M字符;第三层是一个卷积层大小为3*3的卷积核,有128个卷积核,因此在配置列表中对应的元素为128;第四层是一个最大池化下采样层,对应一个M字符;
接下来经过的是2个3*3的卷积核个数为256的卷积核,因此配置列表中对应两个256;再接下来是一个最大池化下采样层,对应一个M字符;接下来经过的是2个3*3的卷积核个数为512的卷积核,因此配置列表中对应两个512;再接下来是一个最大池化下采样层,对应一个M字符;接下来经过的是2个3*3的卷积核个数为512的卷积核,因此配置列表中对应两个512;再接下来是一个最大池化下采样层,对应一个M字符;
提取特征网络结构
提取特征网络结构,传入参数为列表类型的配置变量,在运行过程中,只需要传入cfgs对应配置的列表即可。
假设传入一个列表,首先定义空列表layers,用来存放创建的每一层结构;紧接着定义in_channels变量,因为输入的是rgb彩色图像,所以输入通道为3;接下来通过一个for循环来遍历配置列表。如果当前的配置元素是一个M字符,则该层是一个最大池化层,那么创建一个最大池化下采样层,就是nn.MaxPool2d。上节课讲到,在VGG网络中,所有的最大池化下采样池化核大小都为2,步距也都为2,因此kernel_size=2, stride=2。
1 | def make_features(cfg: list): |
如果当前的配置元素不为M字符,则该层是一个卷积层。
创建一个卷积操作nn.Conv2d,在第一层卷积层中,输入的深度是彩色图像的3,因此第一个值是in_channels;输出的特征矩阵的深度对应着卷积核的个数,因此在第一层卷积层中,v对应64。上堂课中讲到,在VGG中,所有的卷积核为3*3,步距为1,padding为1(stride默认为1,所以没写)。因为每一个卷积层都需要采用ReLU激活函数,所以将刚刚定义好的卷积层和ReLU激活函数拼接在一起,并添加在事先定义好的layers列表中。
当特征矩阵通过该层卷积之后,输出深度变为v,因此执行in_channels = v,因此再下一层卷积层时,它的in_channel会自动变为上一层的卷积层的输出特征矩阵的深度。
通过for循环遍历配置列表,能得到一个有卷积操作和池化操作所组成的一个列表。
接下来通过nn.Sequential函数,将layers列表通过非关键字参数的形式传入进去。在代码中layers前有一个*,代表着是通过非关键字参数传入函数。
原因:在Sequential类中给出了两个使用示例:第一个是最常用的,通过将一个个非关键字参数输入到Sequential类中,就能生成一个新的网络层结构;第二种通过一个有序的字典的形式进行输入。我们这是通过一个非关键字参数的形式输入,因此加了一个*。
1 | # class Sequential(Module): |
(函数被调用的时候,使用*解包一个可迭代对象作为函数的参数,字典对象可以使用两个参数,解包后将作为关键字参数传递给函数;解包:将序列里面的元素一个个拆开)
分类网络结构
定义VGG类,继承于nn.Module父类,在初始化函数中,传进参数有features(提取特征网络结构),num_classes(分类类别个数),init_weights(是否对网络进行权重初始化)
1 | class VGG(nn.Module): |
通过nn.Sequential生成分类网络结构,在VGG网络结构中,图像通过提取特征网络结构之后,会生成一个7*7*512的特征矩阵,如果要进行全连接操作,需要先进行展平处理。在全连接操作之前,加入Dropout函数,目的是为了减少过拟合,有50%的几率随机失活神经元。第一层全连接层,原论文当中应该是4096,但为了减少训练参数,这里减半2048
1 | self.classifier = nn.Sequential( |
是否需要对网络对参数可视化,如果为init_weights为true,就会进入到事先定义的初始化权重函数中
1 | if init_weights: |
正向传播过程:输入x为输入的图像数据,features:提取特征网络结构,接着对输出进行展平处理,展平之后再将输出的特征矩阵输入到classifier函数中,最后得到输出
1 | def forward(self, x): |
在初始化权重函数中,会遍历网络的每一个子模块,即每一层。如果遍历的当前层是卷积层,就用xavier_uniform_初始化方法取初始化卷积层权重,如果有使用到偏置的话,会初始化偏置为0。
如果遍历当前层是全连接层,那么同样使用xavier_uniform_初始化方法去初始化全连接层权重,同样讲偏置为0。
1 | def _initialize_weights(self): |
实例化所给定的配置模型,通过传入变量model_name,需要实例化哪一个模型配置,默认为vgg16。
以此代码为例:将vgg16传入到vgg函数中,cfg = cfgs[vgg16],即vgg16关键字对应的配置列表内容,再通过VGG类实例化VGG网络(首先传入第一个参数是features(来源于make_features),后面两个*对应的变量是一个可变函数的字典变量,通过在调用VGG函数时所传入的字典变量,这个字典变量可能包含了分类个数,是否初始化权重的bool变量)
1 | def vgg(model_name="vgg16", **kwargs): |
train.py
1 | import os |
代码内容和在AlexNet中一致,不做特别讲解,额外说明一下图像初始化中的某处特殊性,及修改了调用VGG函数的部分参数
说明transforms.Normalize
在大多数VGG使用论文中,大部分会在预处理第一步,将RGB三个通道分别减去[123.68,116.78,103.94],这三个值分别对应imageNet的图像数据集的所有数据三个通道的均值。
但这里并没有减去均值,因为这里搭建的VGG模型是从头开始训练的,如果需要基于迁移学习的方式进行再训练的话,就需要减去均值,因为预训练的模型是基于imageNet数据集进行训练的。
1 | data_transform = { |
调用vgg函数
通过model_name确认调用哪一个配置文件,num_classes和init_weights参数输入进去之后,会保存在model中**kwargs的可变长度字典当中。当调用VGG类时,即可调用相应的参数。
1 | model_name = 'vgg16' |
总结
因为VGG网络非常大,而训练集样本太小(只有3k+),是无法充分训练vgg网络,因此不做训练展示,且网络太大, 训练起来可能需要几个小时,在训练中能够达到的准确率大概在80%,时间漫长效果不太好,不建议日常使用。
如果需要使用VGG网络,建议使用迁移学习的方法。