深度学习模型之CNN(三)AlexNet网络结构及数据集下载
AlexNet详解
AlexNet时2012年ILSVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的70%+提升到80%+。它是由Hinton和他的学生Alex Krizhevsky设计的。也是从那年后,深度学习开始迅速发展。
ILSVRC 2012
- 训练集:1,281,167张已标注图片
- 验证集:50,000张已标注图片
- 测试集:100,000张未标注图片
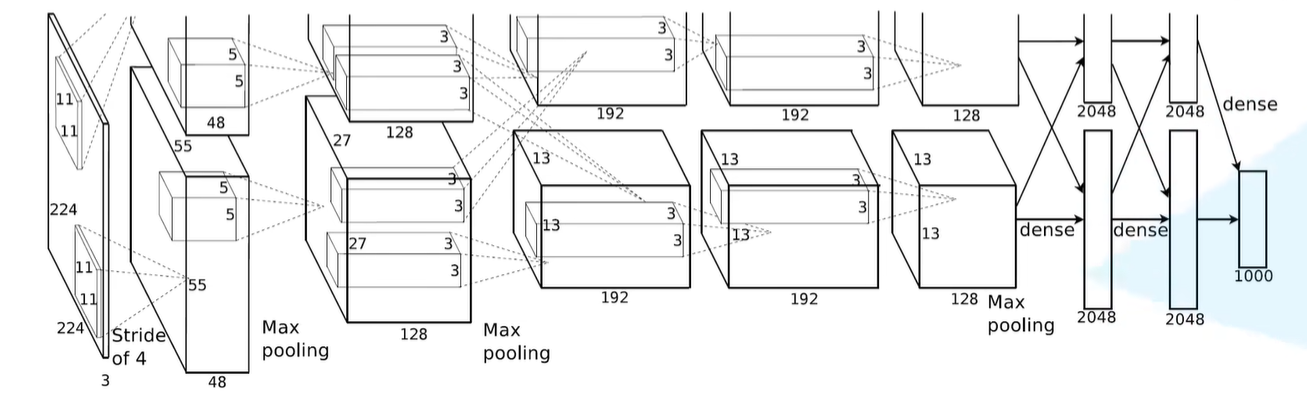
网络的亮点
- 首次使用GPU进行网络加速训练
- 使用ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数
- 使用LRN局部响应归一化
- 在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合
- 高端GPU的提速比可以达到CPU的20-50倍的速度差距
- sigmoid激活函数的两个缺点:1、求导的过程比较麻烦;2、当网络比较深的时候会出现梯度消失的现象。ReLU能够解决以上问题
- dropout操作可以减少过拟合现象
过拟合
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。过度的拟合了训练数据,而没有考虑到泛化能力
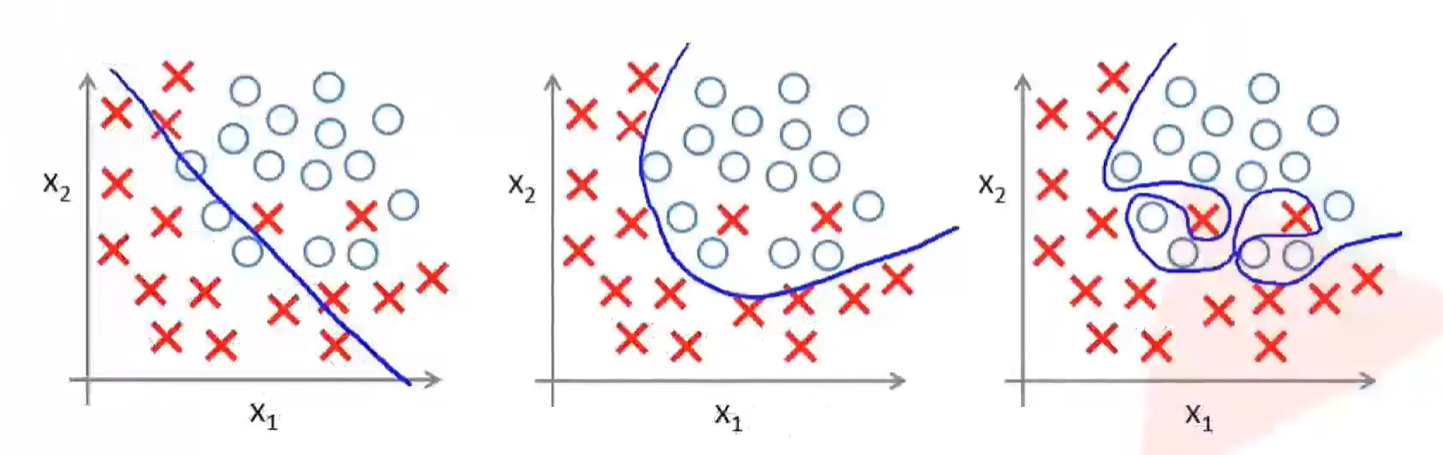
- 第一幅图是网络的一个初始状态,随机地划分了一条边界对于样本进行分类
- 通过不断的训练过程中,网络会慢慢学习出一条分类的边界如第二幅图所示,得到了一个比较好的分类的结果
- 第三幅图虽然能够将训练样本进行完全正确的分类,但是图中出现了过拟合现象
- 过拟合的函数能够完美地预测训练集,但是对新数据的测试机预测效果较差,过度的拟合了训练数据,而没有考虑到泛化能力
使用dropout减少过拟合现象
使用Dropout的方式在网络正向传播过程中随机失活一部分神经元
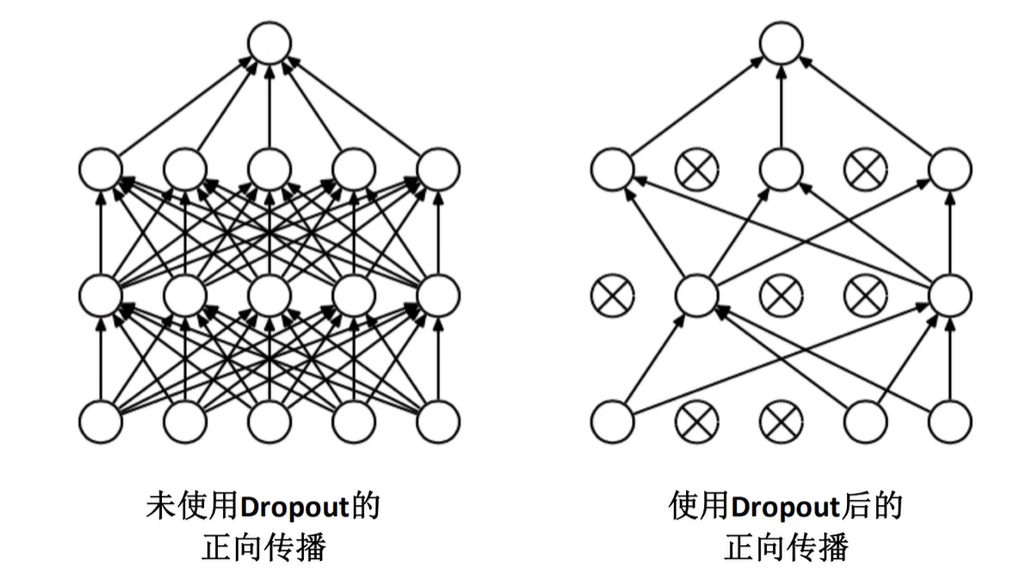
- 左图是一个正常的全连接的正向传播过程,每一个节点都与下层的节点进行全连接
- 使用了dropout之后,会在每一层随机地失活一部分神经元,变相地减少了网络中训练的参数,从而达到了减少过拟合现象的作用
AlexNet网络结构
经卷积后的矩阵尺寸大小计算公式为:
\begin{flalign}
N = (W-F+2P)/S + 1
\end{flalign}
- 输入图片大小:W×W
- Filter大小:F×F
- 步长:S
- padding的像素数:P
- 这个图可以看成上下两部分:作者使用了两块GPU进行了并行运算
- 上下两部分都是一样的,只用看其中一部分即可
Conv1
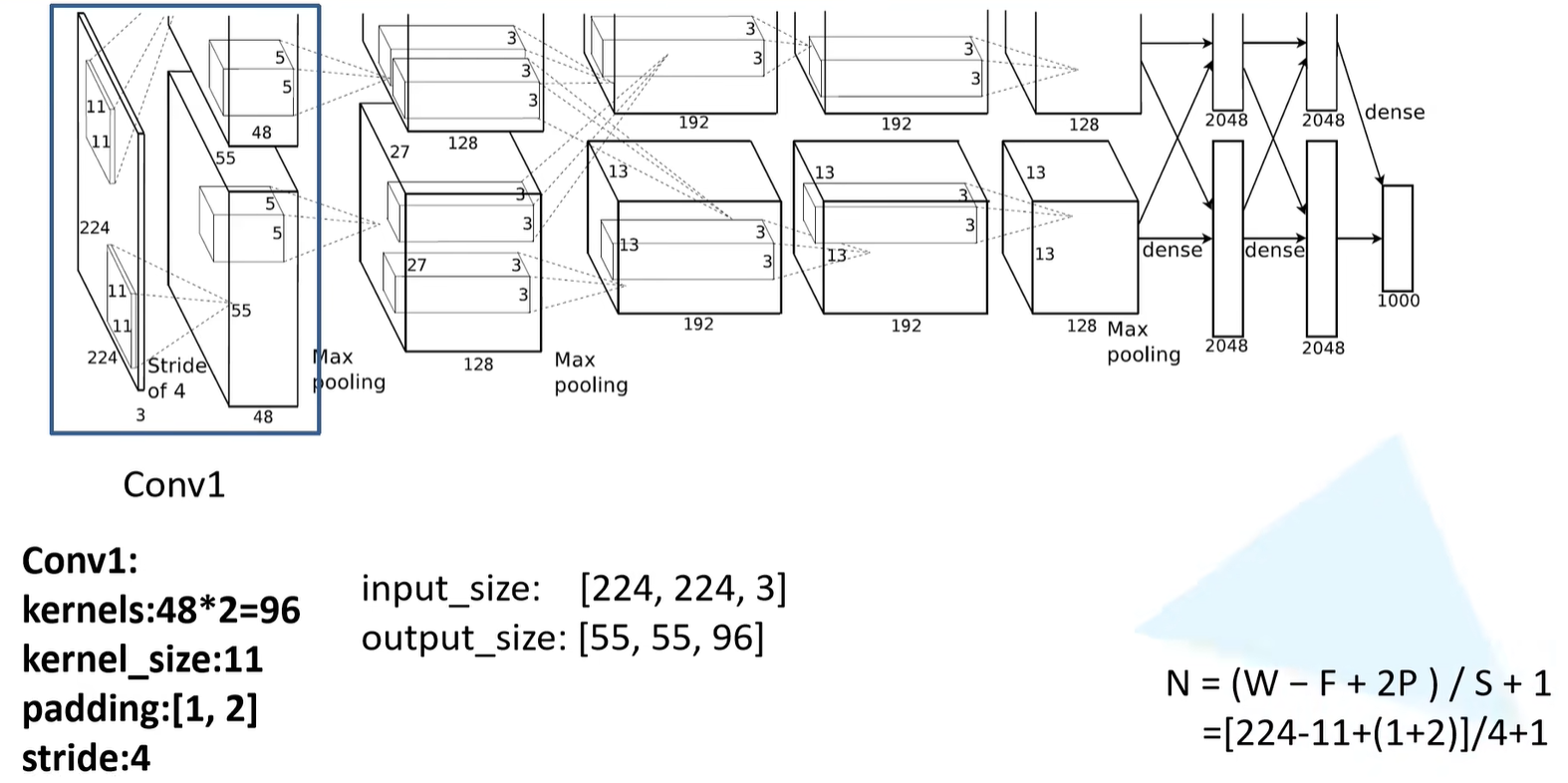
- 原始图像是一个224*224的channel为3的彩色图像
- 卷积核大小是11*11
- 步长为4
- 卷积核的大小为11
- 一共有48*2=96个卷积核
- 可以推理出padding的大小是1和2:表示在特征矩阵的左边加上一列0,右边加上两列0,上面加上一列0,下面加上两列0**(注意代表padding的2p值的是两边padding的像素之和,并不一定要求两边像素一定要一样)**
Maxpooling1
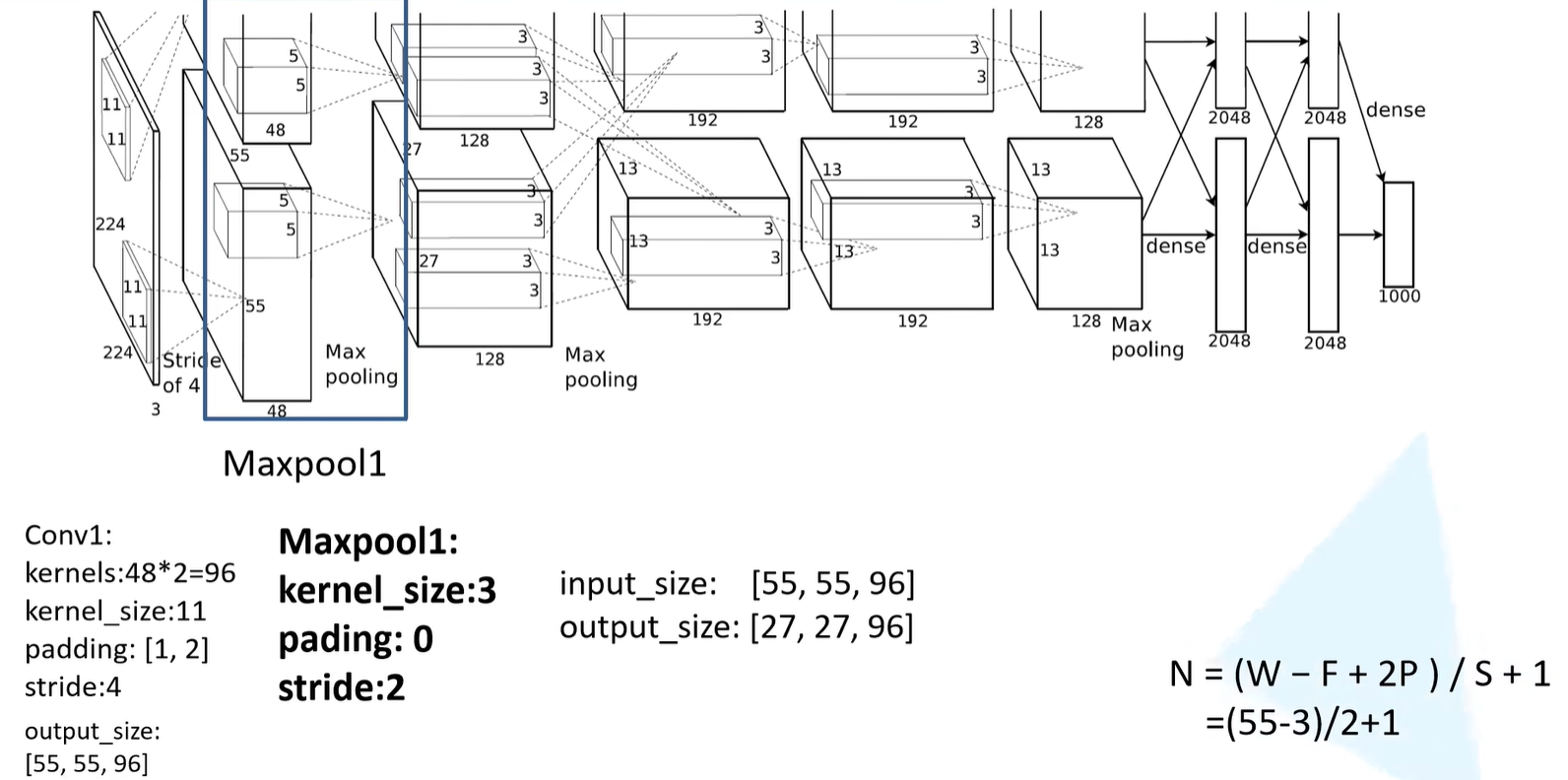
- 最大池化下采样操作
- 池化核大小等于3
- padding为0
- 步长为2
- 这一层的输入是第一层卷积层的输出
- 池化操作只会改变输出矩阵的高度和宽度,不会改变特征矩阵的深度
Conv2
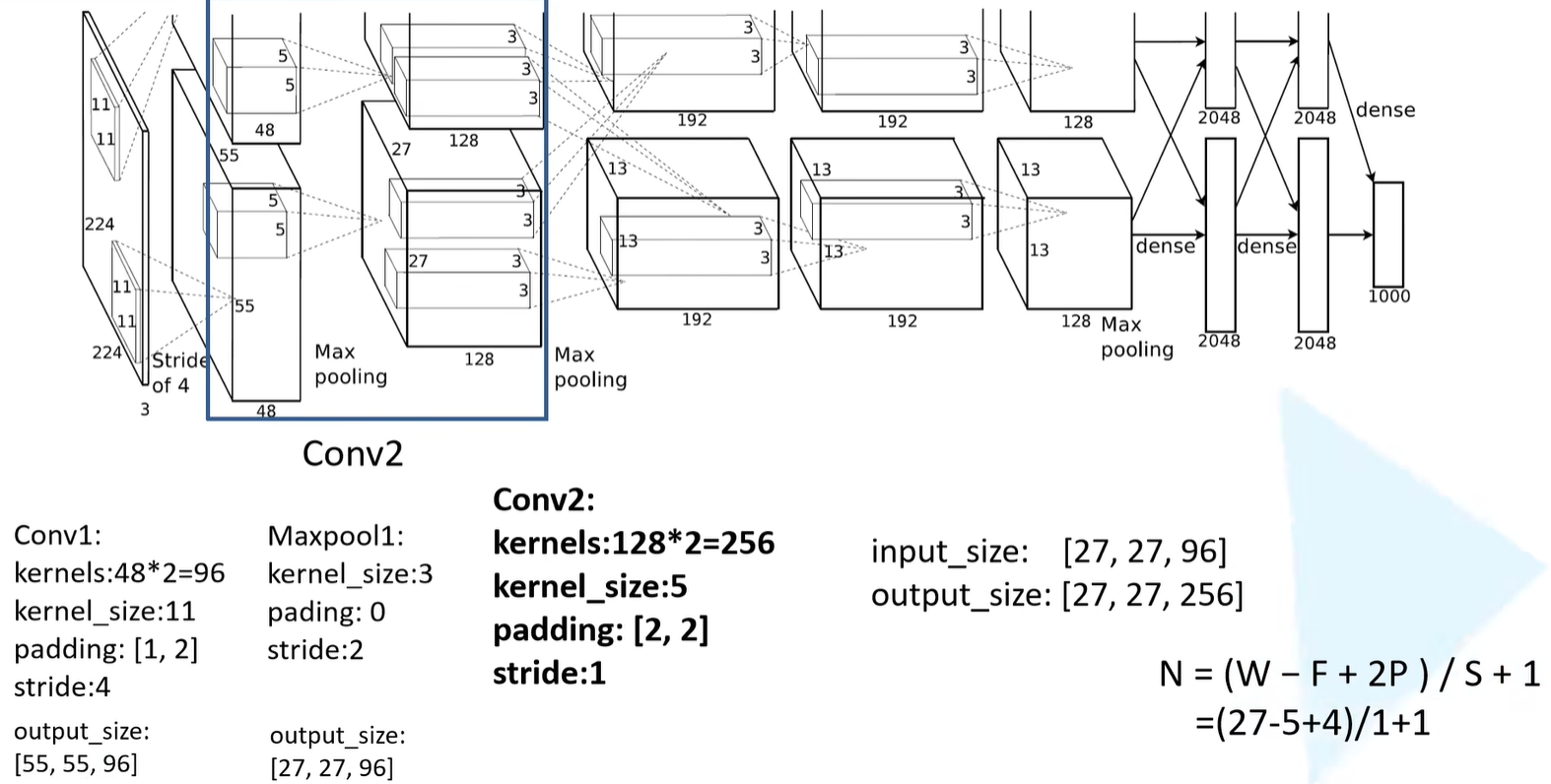
- 卷积核的个数为128*2=256
- 卷积核的大小为5
- padding为 [ 2,2 ]
- 步长为1
Maxpooling2
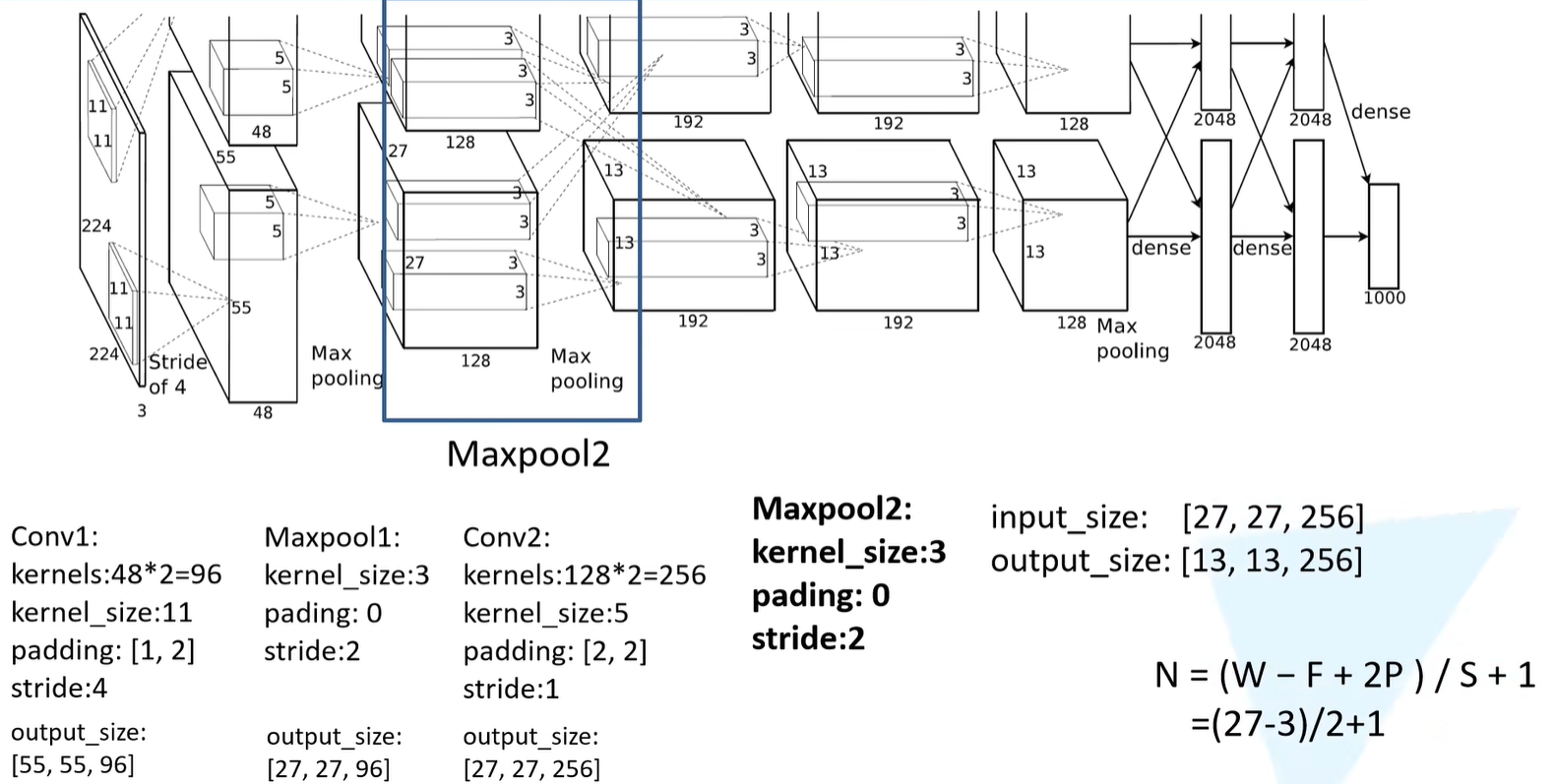
- 池化核大小为3
- padding为0
- 步长等于2
Conv3
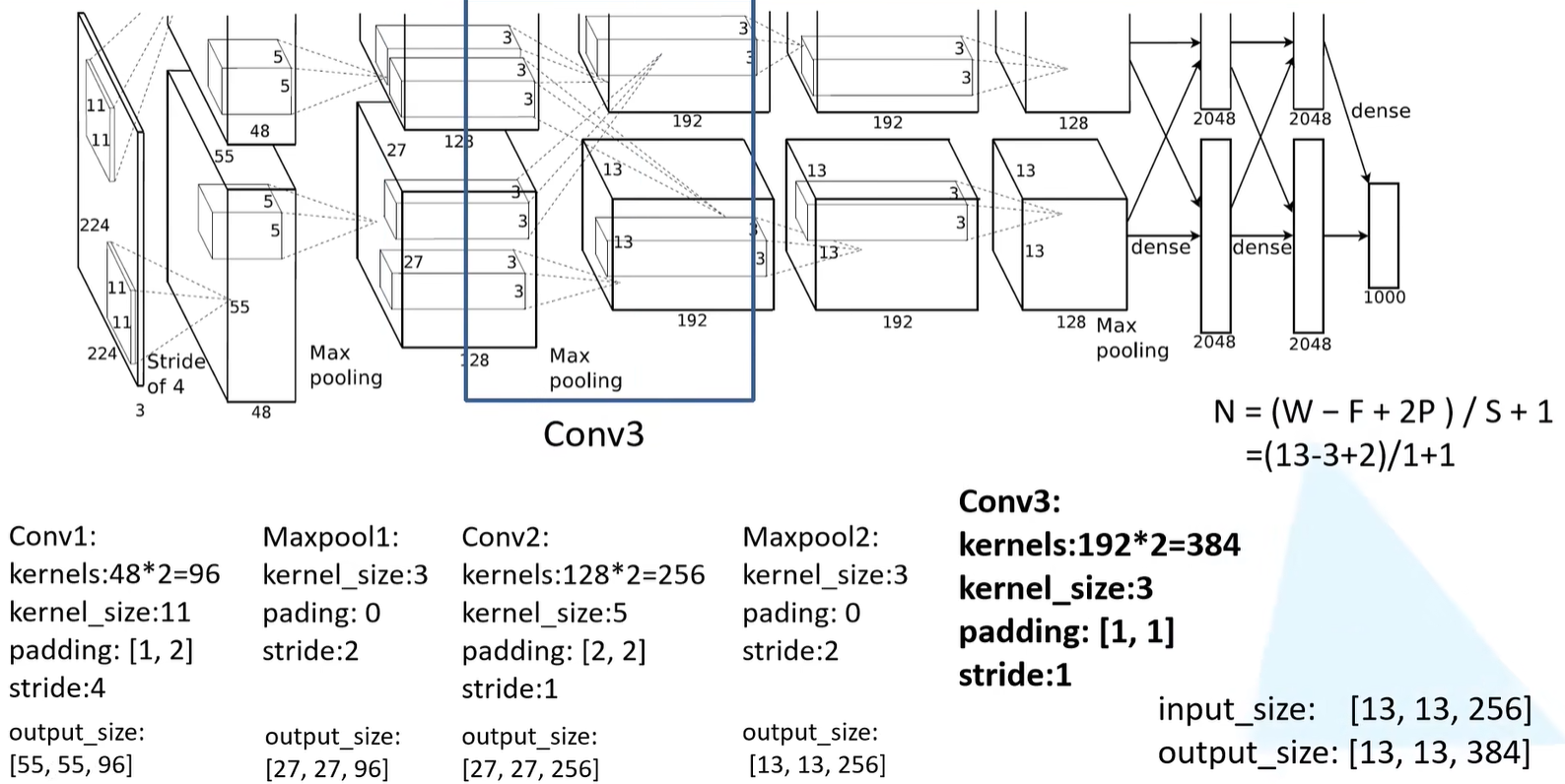
- 卷积核的个数为192*2=384
- 卷积核的大小为3
- padding为 [ 1,1 ]
- 步长为1
Conv4
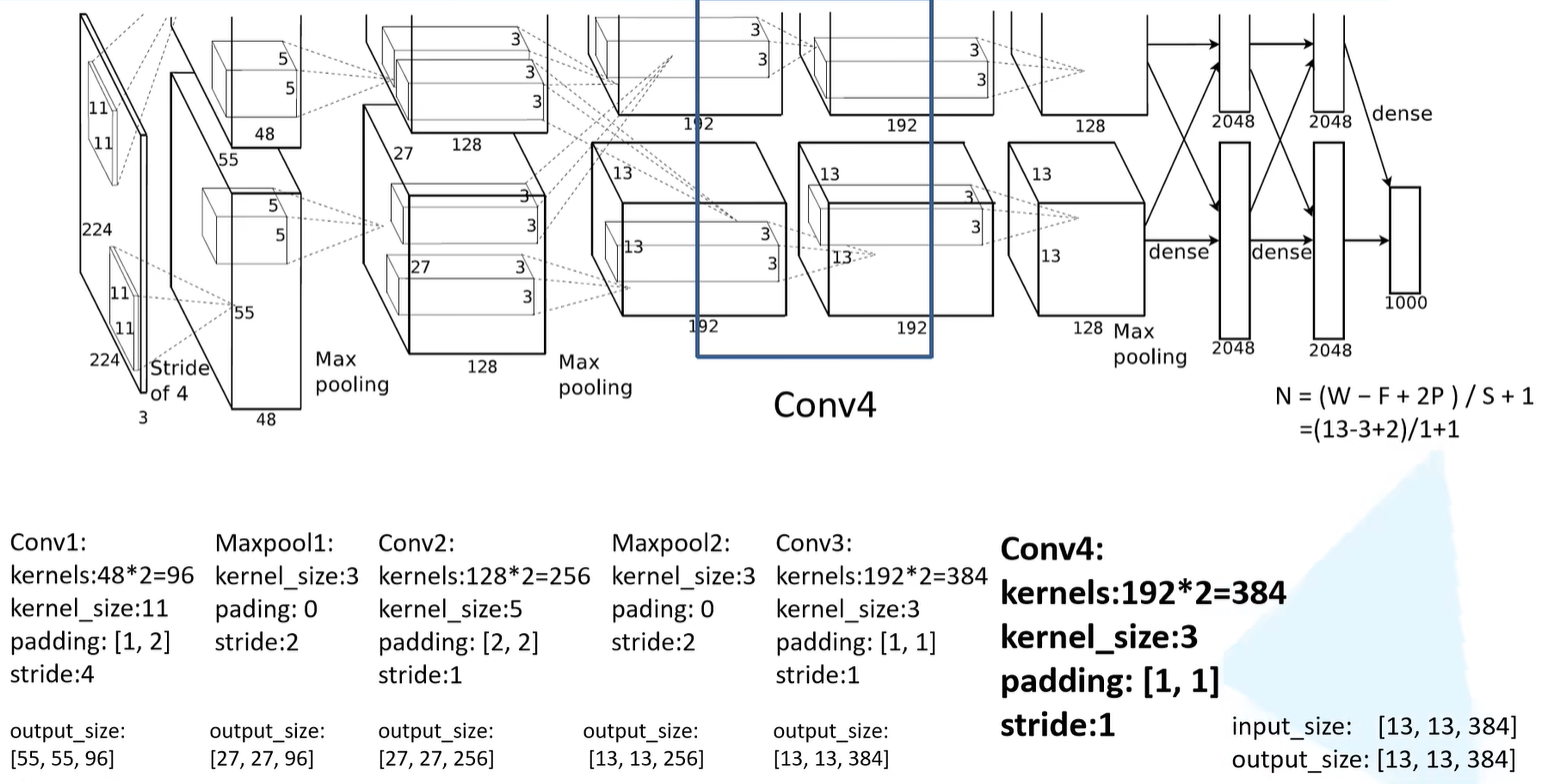
- 卷积核的个数为192*2=384
- 卷积核的大小为3
- padding为 [ 1,1 ]
- 步长为1
Conv5
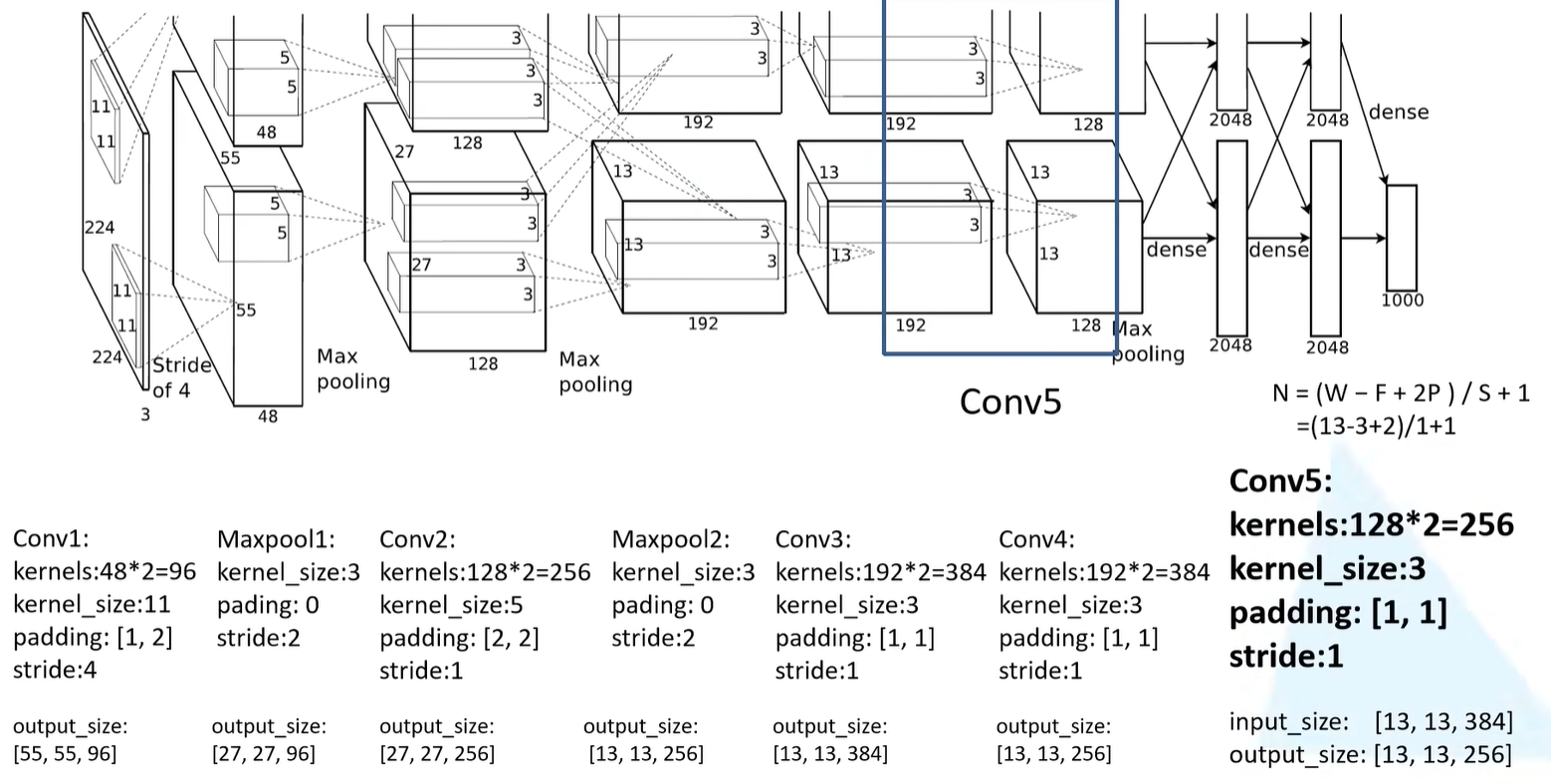
- 卷积核的个数为128*2=256
- 卷积核的大小为3
- padding为 [ 1,1 ]
- 步长为1
Maxpooling3
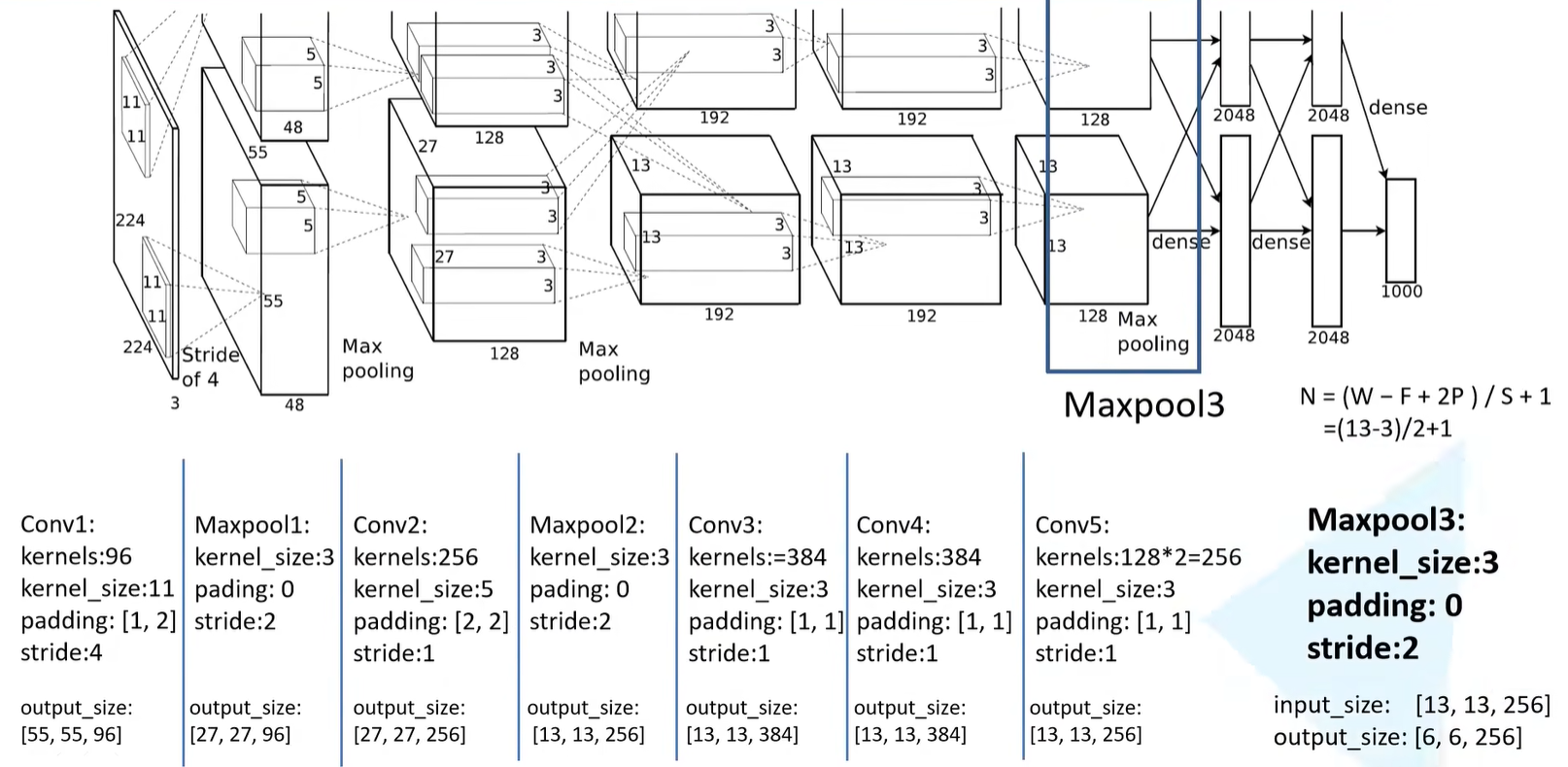
- 池化核的大小为3
- padding等于0
- 步长为2
- 输出的特征矩阵展平之后和三个全连接层进行连接**(注意最后一个全连接层只有1000个节点,对应数据集的1000个类别,如果要将这个网络应用到自己的数据集的话,只需要将最后一层全连接层的节点个数改成和自己数据集的类别数一致即可)**
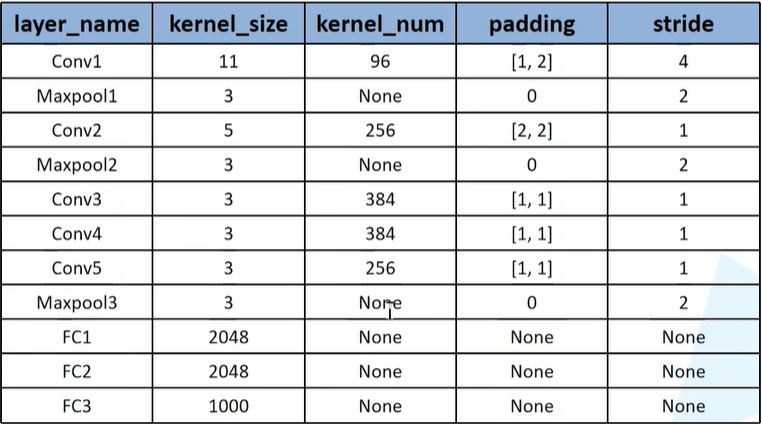
层级参数总结
下载花分类数据集

步骤如下:
- 在data_set文件夹下创建新文件夹"flower_data"
- 点击链接下载花分类数据集 https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
- 解压数据集到flower_data文件夹下
- 执行"split_data.py"脚本(网盘下载)自动将数据集划分成训练集train和验证集val(训练集:测试集 = 9 :1)
1 | ├── data_set |
附split_data.py代码
1 | import os |
运行split_data.py之后,结果如图所示
总结
本节课主要讲AlexNet的网络结构,以及需要使用到的数据集,下节课将会使用Pytorch来搭建AlexNet,并用下载好的花分类数据集进行训练。