深度学习模型之CNN(二)Pytorch官方demo(LeNet)
因为之前一直没有搭建conda的环境,笔记也是后来补充,过程忘得七七八八了,就直接从demo代码开始记录。
By the way, Anaconda Navigator用管理员打开下载包更能省事。
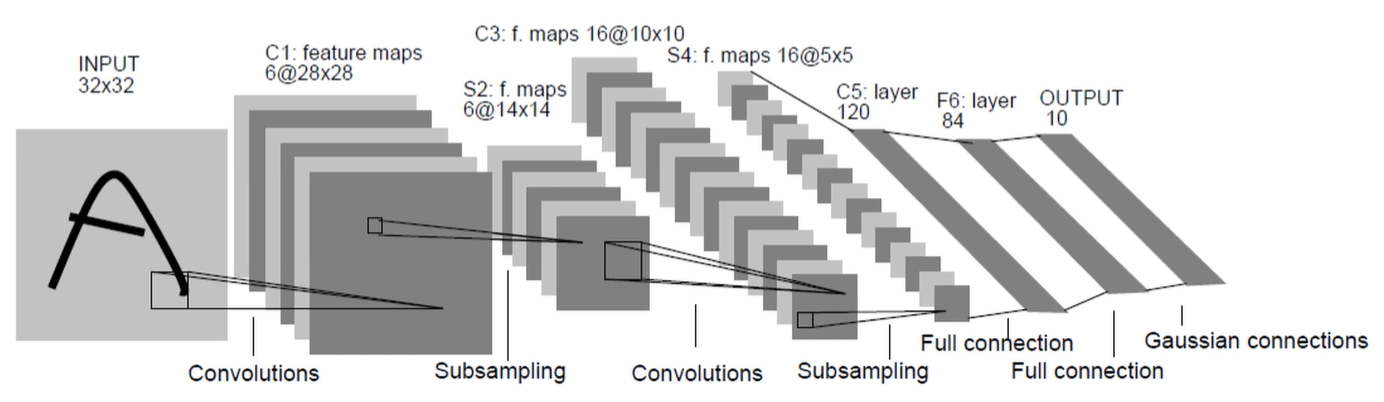
LeCun的LeNet(1998)网络架构
Pytorch Tensor的通道排序: [ batch, channel, height, width ]
- batch:一批图像的个数,如图中示例,表示有32张图片
又因为本次使用的官方数据集为CIFAR10(官方提供),是彩色图片,所以深度为3(RGB)
- channel:3(深度)
- height:32(高度)
- width:32(宽度)
代码示例
工程目录如下(data数据集的下载方式后文补充)
1 | ├── Test1_official_demo |
模型文件model.py
1 | import torch.nn as nn |
用的两个包都是pytorch的包,虽然下载的是pytorch的包,但实际使用的时候,导入的还是pytorch.XX
1 | import torch.nn as nn |
代码解释
初始化函数
新建一个类,继承于nn.Module这个父类,类中实现两个方法:init()和forward()
1 | class LeNet(nn.Module): |
在初始化函数中,会实现在搭建网络过程中所需要使用到的一些网络层结构
1 | def __init__(self): |
super函数:因为在定义类的过程中继承了nn.Module这个父类,而super函数是用来解决多重继承中调用父类方法中可能出现的一系列问题,简而言之就是——只要涉及到多继承,一般都会使用super函数
1 | # python2.0版本 |
conv1相当于图片中的第一个Convolutions,通过nn.Conv2d()函数来定义卷积层。
3:图片深度,16:使用了16个卷积核 = 输出16维度的特征矩阵,5:卷积核大小5×5
1 | self.conv1 = nn.Conv2d(3, 16, 5) |
pool1定义下采样层,相当于图片中第一个Subsampling
1 | self.pool1 = nn.MaxPool2d(2, 2) |
全连接层输入是一个一维向量,需要将特征矩阵展平,图片显示第一层的节点个数是120
1 | self.fc1 = nn.Linear(32*5*5, 120) |
第二层的输入是第一层的输出 120,输出为84
1 | self.fc2 = nn.Linear(120, 84) |
第三层的输入是第二层的输出 84,输出为10(需要根据实际的训练集进行修改,本次例子中采用CIFAR10数据集,具有10个类别的分类任务,因此这里设置为10)
1 | self.fc3 = nn.Linear(84, 10) |
forward函数
forward函数中定义正向传播的过程。x代表输入的数据,数据指的是Tensor的通道排序:[batch, channel, height, width]
1 | def forward(self, x): |
relu激活函数。input(3, 32, 32) output(16, 28, 28)
1 | x = F.relu(self.conv1(x)) |
经过Maxpool2d处理,大小缩减为原来的一半,深度不变
1 | x = self.pool1(x) # output(16, 14, 14) |
数据经过view函数将它展成一维向量,-1代表第一个维度进行自动推理(batch),第二个维度值展平之后的节点个数。view中第一个参数为-1,代表动态调整这个维度上的元素个数,以保证元素的总数不变
1 | x = x.view(-1, 32*5*5) # output(32*5*5) |
Con2d函数
ctrl+鼠标左键点击Conv2d,pycharm自动跳转到Conv2d的函数定义
简介:使用2d卷积的方法对输入的数据进行处理

其中__init__()函数参数定义如下
1 | def __init__( |
2.1.1在pytorch官方文档中ctrl+F查找Conv2d函数,得到在官方的解释
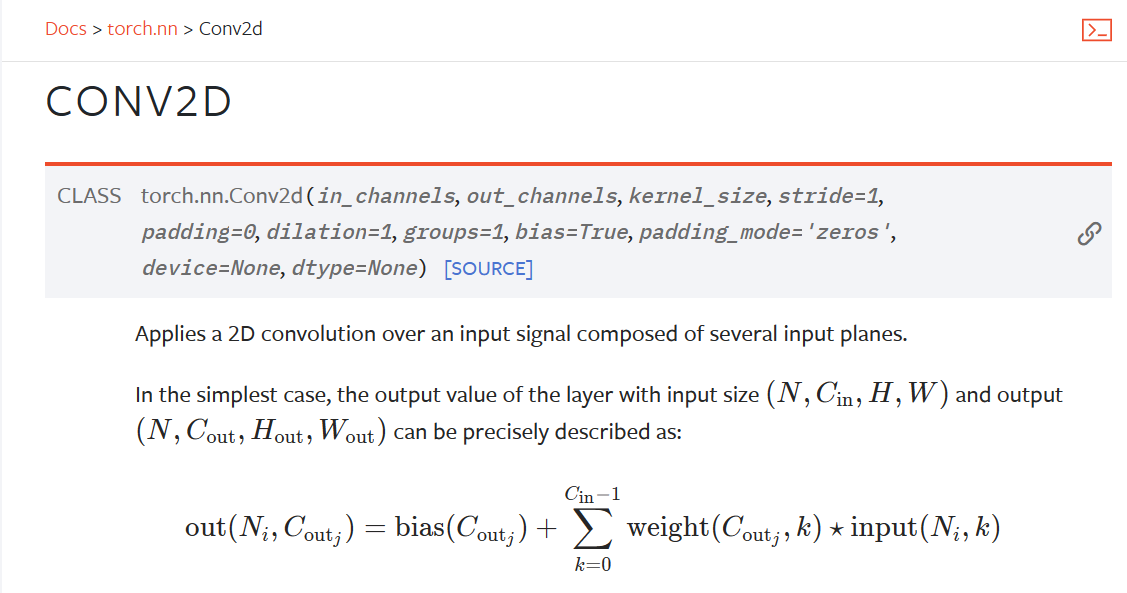
每个参数的解释

以及卷积输出维度的变化

实际相当于
\begin{flalign}
N = (W-F+2P)/S + 1
\end{flalign}
- 输入图片大小:W×W
- Filter大小:F×F
- 步长:S
- padding的像素数:P
MaxPool2d函数
简介:没有初始化函数,因为继承来自_MaxPoolNd父类
跳转到父类_MaxPoolNd
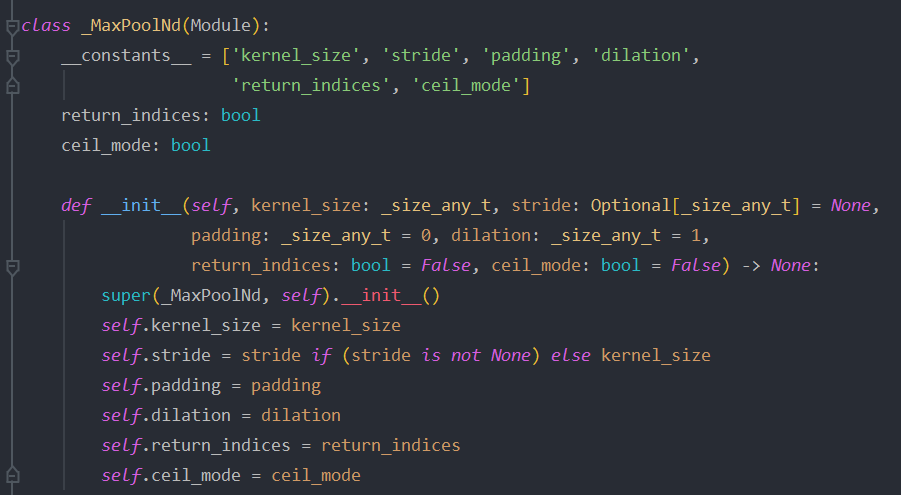
1 | def __init__(self, |
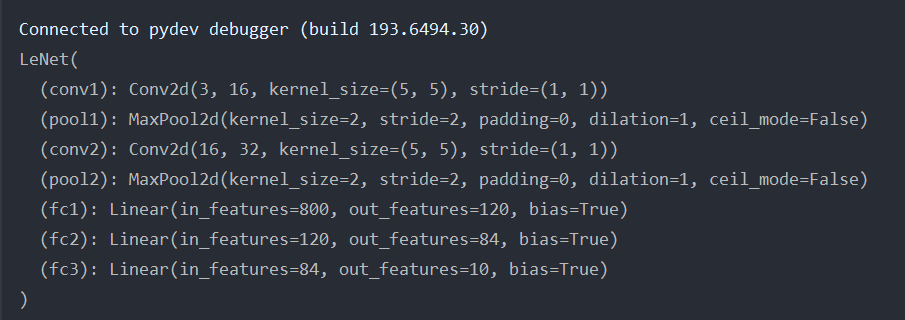
测试结果(debug)
1 | import torch |
终端打印信息
调用模型训练train.py
1 | import torch |
下载及测试数据集
使用Compose函数将使用的一些预处理方法给打包成一个整体,首先通过CIFAR10导入数据集,将训练集的每一个图像transform预处理函数进行预处理
1 | transform = transforms.Compose( |
50000张训练照片,下载数据集download=True,下载成功后改download=False;root代表将数据集下载到什么地方,train=True时会导入CIFAR10训练集的样本;download=True自动下载;transform=transform对图像进行预处理
或者在当前文件夹下新建data文件夹,直接下载CIFAR10数据集并在data文件夹下解压
1 | transet = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform) |
将数据集导入进来,分成一个个批次,这里指每一批随机拿出batch_size=36张图片进行训练;shuffle=True表示是否要将数据集打乱,一般为True;num_workers理解为载入数据的线程数,目前windows环境下也可以设置,但不能超过支持的线程个数,可以加快图片载入的速度。
1 | trainloader = torch.utils.data.DataLoader(transet, batch_size=36, shuffle=True, num_workers=0) |
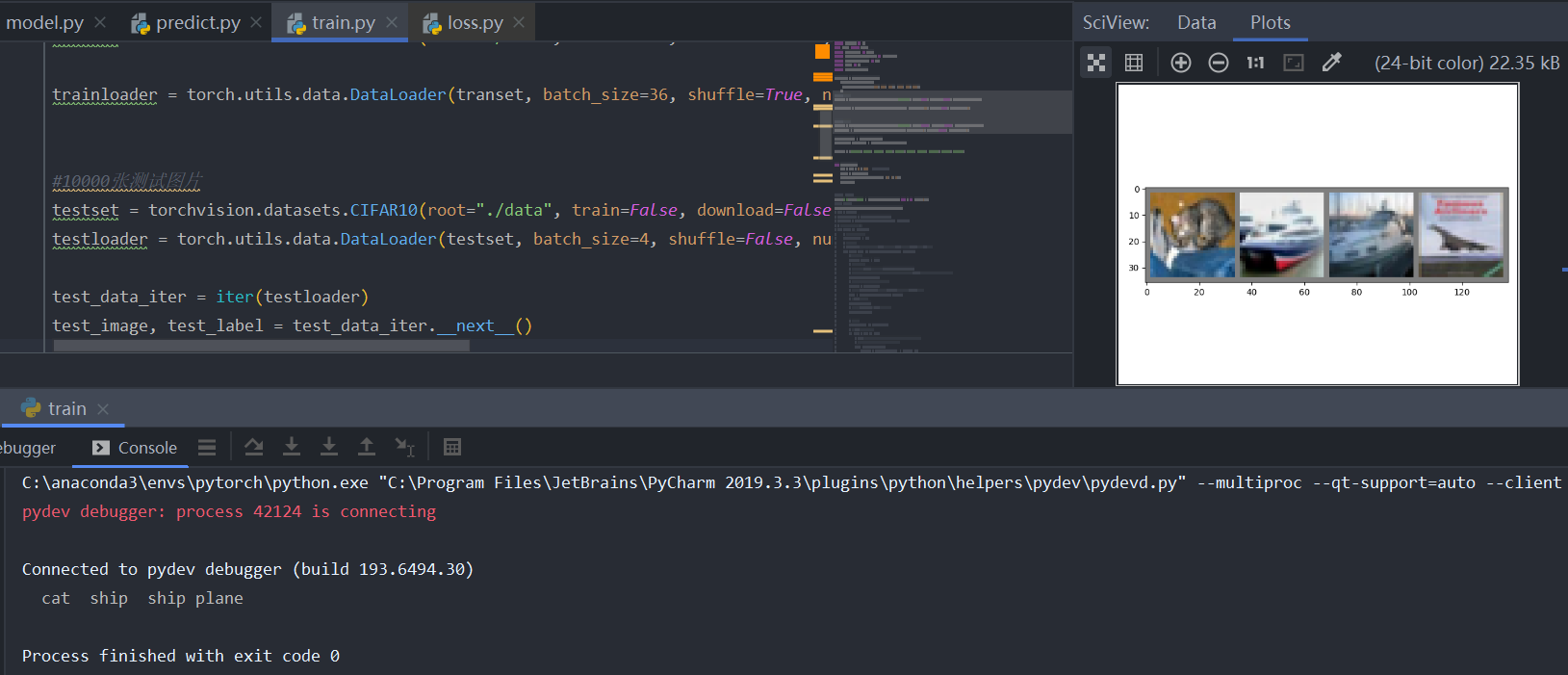
10000张测试图片,测试时将batch_size改为4
1 | testset = torchvision.datasets.CIFAR10(root="./data", train=False, download=False, transform=transform) |
iter函数是将更改生成的testloader转化为一个可迭代的迭代器
1 | test_data_iter = iter(testloader) |
通过__next__()方法获取到一批数据,可拿到图像及图像对应的标签值
1 | test_image, test_label = test_data_iter.__next__() |
导入标签,元组类型,不可更改,0,1,…,9
1 | classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'flog', 'horse', 'ship', 'truck') |
测试代码
1 | def imshow(img): |
数据集下载

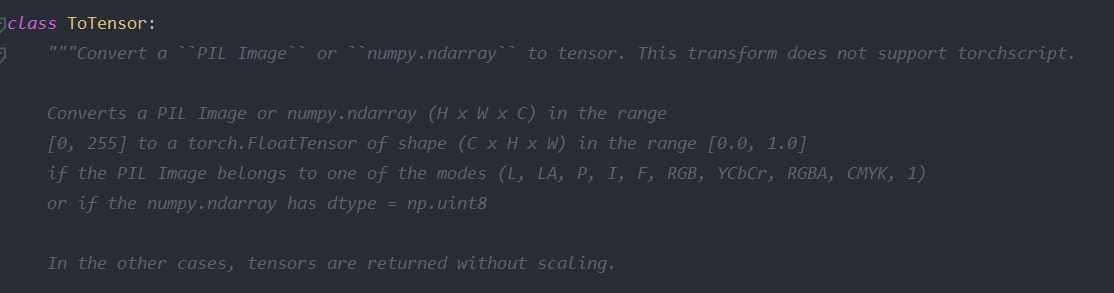
ToTensor函数
将PIL图像或者numpy数据转化为tensor。导入的原始图片,无论是PIL或者通过numpy导入(一般图像为高度,宽度,深度,每一个像素值都是[0, 255]),通过ToTensor函数之后,将shape(长宽高的值)转化为[0.0, 1.0]
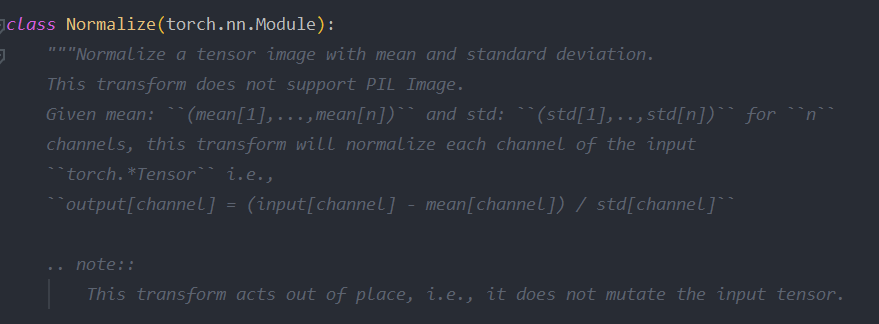
Normalize函数
使用均值和标准差转化tensor,计算方式 : 输出 = (原始数据 - 均值)/ 标准差
测试结果
构造模型
注释掉测试的输出代码
1 | net = LeNet() |
将训练集训练多少次,这里为5次
1 | for epoch in range(5): |
用来累计在训练过程中的损失
1 | running_loss = 0.0 |
遍历训练集样本;enumerate函数不仅能返回每一批的数据data,还能返回这一批data所对应的步数index,相当于C++中的枚举
1 | for step, data in enumerate(trainloader, start=0): |
输入的图像及标签
1 | inputs, labels = data |
将历史损失梯度清零;
为什么每计算一个batch,就需要调用一次optimizer.zero._grad()?
如果不清除历史梯度,就会对计算的历史梯度进行累加(通过这个特性你能够变相实现一个很大batch数值的训练),主要还是硬件设备受限,防止爆内存
1 | optimizer.zero_grad() |
将我们得到的数的图片输入到网络进行正向传播,得到输出
1 | outputs = net(inputs) |
通过定义的loss_function来计算损失,outputs:网络预测的值,labels:真实标签
1 | loss = loss_function(outputs, labels) |
对loss进行反向传播
1 | loss.backward() |
通过优化器optimizer中step函数进行参数更新
1 | optimizer.step() |
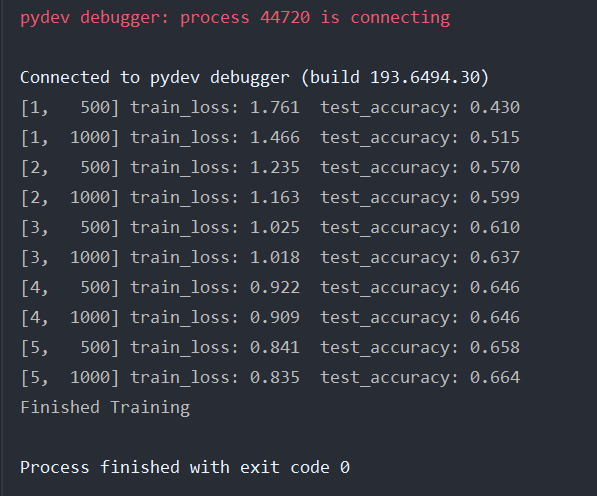
打印的过程:
1 | running_loss += loss.item() |
每隔500步,打印一次数据信息
1 | if step % 500 == 499: |
with是一个上下文管理器,意思是在接下来的计算过程中,不要去计算每个节点的误差损失梯度;否则会自动生成前向的传播图,会占用大量内存,测试时应该禁用
1 | with torch.no_grad(): |
predict_y寻找outputs中数值最大的,也就是最有可能的标签类型;dim:第几个维度,第0个维度是batch,第1个维度指10个标签结果;[1]指只需要知道index即可,不需要知晓具体的值
1 | predict_y = torch.max(outputs, dim=1)[1] |
将预测的标签类别和真实的标签类别进行比较,相同的地方返回1,不相同返回0;使用求和函数,得出在本次预测对了多少个样本;tensor得到的并不是数值,item()才可以拿到
1 | # 数据准确率 |
迭代到第几轮,在某一轮的多少步,训练过程中的累加误差,测试样本的准确率
1 | print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % |
debug一下,会暂时没反应,点开任务管理器,CPU已经100%,等待一段时间会有打印结果
打印结果
训练完之后在当前目录下生成一个模型权重文件
1 | # 对模型进行保存 |
调用模型进行预测predict.py
在网上随便下载一张分类在模型中的图片,存放在当前文件夹下取名1.jpg
1 | import torch |
预测结果
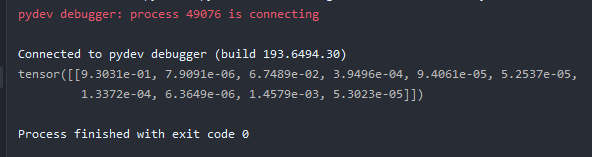
假设:将max函数改为softmax函数
1 | with torch.no_grad(): |
输出结果为:经过softmax处理之后的概率分布
预测index = 0的值概率为93.0%,后面都很小,忽略不看
总结
首先,回顾之前学习LeNet,通过pytorch搭建LeNet模型;
接着,介绍并下载了CIFAR10数据集,对数据集进行预处理,查看图片并导入到LeNet模型,定义了损失函数、优化器;
最后,进行了网络的训练,对训练好的权重进行保存,通过预测脚本,调用保存的模型权重进行预测。